
Introducción a Linux Y Bash scripting (Completo).
En este post iré explicando lo fundamental que necesitas saber sobre linux, hasta cosas más avanzadas como bash scripting.
Comandos basicos linux
whoami
whoami : Este comando nos sirve para saber que usuario esta usando el sistema actualmente.

Podemos ver que el usuario que esta ejecutando el sistema actualmente es d4nsh.
clear
Con este comando vamos a poder limpiar la pantalla de la terminal para no tener en pantalla cosas que ya no queremos y solo hagan espacio.
Esto solo limpia la pantalla de comandos no elimina archivos.
Crear y borrar archivos y directorios(carpetas).
Para crear un archivo usamos el comando touch:

Y para eliminarlo usamos el comando rm:
Y para crear un directorio se usa el comando mkdir:

Y para eliminar directorios vacios simplemente usamos rm, pero cuando no este vacio usamos rm -r:
Vemos que se ha eliminado correctamente el directorio.
Otro parametro de rm puede ser el -f que nos sirve para que no nos pida la confirmación de eliminar una carpeta con archivos dentro.
id, sudo su, exit
id : Este comando nos permite ver los grupos a los que el usuario esta integrado:

Podemos apreciar que pertenecemos a toda esta serie de grupos, cada usuario tiene un grupo con su mismo nombre, pero ademas contiene otros grupos a los que puede ser añadidos.
Existen grupos que son potencialmente peligrosos si es que no se configuran adecuadamente y se les otorga el grupo a un usuario atacante, entonces este atacante podría escalar privilegios, que básicamente es llegar al usuario root, el usuario root es el que tiene permitido hacer la mayoría de cosas en el sistema, siendo algo así como un usuario administrador.
si vemos bien, apreciamos que estamos dentro del grupo (root), por lo que al ejecutar el comando:
sudo su : Podremos migrar al usuario con máximos privilegios siempre y cuando conozcamos la contraseña.
Podemos ver que migramos al usuario root, y dentro de este usuario root, tenemos acceso a esos grupos que se ven en la imagen.
Con el comando exit podemos salir de la sesión de root para volver a la anterior, en este caso d4nsh:
El usuario root comúnmente tiene un identificador que lo caracteriza y es el símbolo de #.
Al momento de entrar a root y salir con exit sin cerrar la terminal, puedes volver a poner el comando
sudo supara migrar nuevamente a root pero esta vez no te pedirá contraseña ya que por detrás se almacena un token temporal por cierto tiempo el cual evita que tengamos que poner la contraseña a cada rato, pero puede ser peligroso si no cierras la terminal ya que otra persona podría poner el comando y migrar a root, por eso es importante que al terminar cierres tu terminal y al momento de abrir otra y querer migrar a root, nuevamente te pedirá la contraseña.
Y si quieres ejecutar solo un comando en el contexto de root, pero no tienes la necesidad de migrar a root para ejecutar este comando como root.
Podemos usar el comando sudo antes del comando que queremos ejecutar como root, por ejemplo tenemos una terminal como el usuario d4nsh, pero si queremos ejecutar el comando whoami con privilegios de root entonces sucederá lo siguiente:
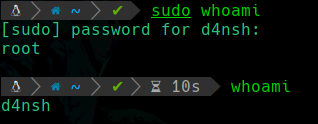
Podemos apreciar que ejecutamos el comando whoami en el contexto del usuario root, pero seguimos siendo d4nsh ya que solamente ejecutamos el comando anterior con contexto de root más no nos convertimos en root.
Rutas de los grupos, cat
Los grupos mostrados anteriormente existen en rutas del sistema, existen dentro de la ruta del sistema /etc/ y dentro de esta ruta existe un archivo llamado group.
cat El comando cat se utiliza para leer archivos de texto o similares, por ejemplo si queremos leer el archivo anterior tendríamos que ejecutar:
cat /etc/group Aquí estamos diciendo que nos lea el contenido del archivo group que se encuentra dentro de la ruta /etc/:
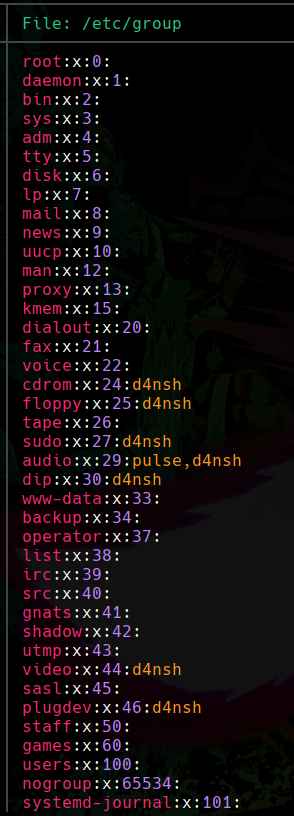
Podemos apreciar que todos estos grupos son los que existen dentro del sistema, son el total de todos los que hay, así que de esta forma podemos leer archivos con el comando cat.
Se verá diferente si tienes tu sistema operativo linux sin modificar, pero el mio esta así gracias a unas configuraciones.
Ruta absoluta y ruta relativa, which
Cada comando contiene una ruta absoluta y una ruta relativa, veamos el ejemplo con el comando whoami .
Al usar el comando whoami estamos llamando a ese comando desde su ruta relativa.
Y para ver su ruta absoluta usaremos el comando which:

Podemos apreciar que la ruta absoluta del comando whoami es la ruta: /usr/bin/ y ejecuta el binario whoami que es la ruta donde se almacena el binario de este comando.
Un binario es un ejecutable que hace algo, en este caso sabemos que whoami nos muestra el usuario actual del sistema.
Ahora que ya sabemos la ruta absoluta de este binario, llamaremos a el comando whoami desde su ruta absoluta para ver que funciona:

Esto es lo mismo que usar simplemente whoami, pero si lo llamamos desde toda su ruta entonces se esta llamando desde su ruta absoluta.
Variable de entorno, $PATH, $HOME, echo
echo Este comando nos sirve para imprimir un mensaje en pantalla por ejemplo:

Podemos ver que hemos mostrado el texto que pusimos entre comillas dobles y después nos lo mostró.
Ahora, ¿que es una variable de entorno?
Una variable de entorno es una variable que se puede encontrar dentro del sistema operativo y que podemos leer su contenido.
Por ejemplo, la variable PATH:

Para imprimir el valor de una variable en bash, se utiliza el símbolo de dolar $ seguido de la variable a la que quieres leer sus datos, en este caso es la variable PATH.
Podemos ver que esta variable de entorno contiene una serie de rutas, estas rutas tienen la siguiente función:
Cuando ejecutas un comando con la ruta relativa, este comando con ruta relativa, se empieza a buscar dentro de todos estos directorios que se ven en la imagen.
Empieza desde /root/.local/bin y sigue así buscando que exista ese binario dentro de todas las rutas que siguen, cada ruta se separa por “:” y sigue buscando hasta encontrarlo, cuando lo encuentra lo ejecuta.
Sabemos que la ruta absoluta de whoami esta dentro de /usr/bin, entonces al momento de llamar el comando whoami sin ruta absoluta, solamente relativa, entonces este comando buscara por cada directorio, y como vemos en la imagen en la quinta posición esta la ruta donde se encuentra el binario de whoami, por lo que lo encontrará y lo ejecutará.
También existe una forma de hackear una maquina si en el sistema hay un script o algo similar al que tengamos acceso y si se esta usando comandos con ruta relativa puede haber un riesgo de seguridad que veremos más adelante.
Y la variable de entorno HOME nos indica cual es nuestro directorio personal del sistema, que podemos verlo usando echo a esa variable de entorno:

Esta ruta es donde el sistema nos pone por defecto al abrir una terminal, más adelante veremos sobre estas rutas.
grep, pipes
El comando grep nos es muy útil al momento de querer filtrar información, por ejemplo, si hacemos un cat al archivo /etc/group:
Vemos este contenido, pero si solamente queremos ver algo en especifico, por ejemplo el grupo que se llama floppy, entonces aquí es donde entra el uso de pipes y grep.
Los pipes o tuberías nos sirven para que la salida de un comando se guarde dentro del pipe para después tratar esa salida y hacerle lo que le indiquemos.
Por ejemplo:

Podemos ver que la salida del comando cat /etc/group se almacena dentro del pipe que se representa con este carácter: | , dentro de esa tubería se guarda la salida del cat para después usar el siguiente comando, el cuál es grep y lo que hace grep es filtrar datos de una salida de datos dada, en este caso esa salida de datos dada es la que esta almacenada en el pipe que es todo el texto que esta dentro de /etc/group y que estamos leyendo con cat.
Entonces ponemos como parámetro al comando grep la palabra a filtrar, en este caso queremos que nos filtre lo que contenga la palabra “floppy”, y en la salida del comando podemos ver que nos da una linea de salida filtrandonos solo ese elemento y ignorando el resto ya que solo queremos filtrar las cosas que contengan ese valor en la linea.
parametro -n de grep
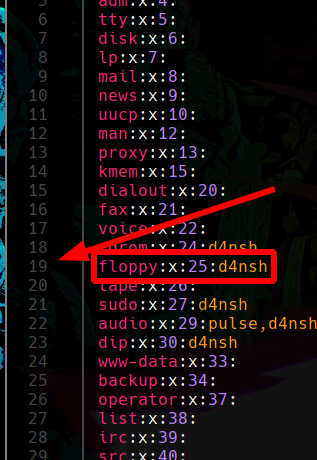
el parámetro -n del comando grep, nos sirve para indicarnos en que linea del archivo pasado se encuentra el valor que filtramos, por ejemplo:

Podemos apreciar que nos muestra que esta en la linea 19, y podemos comprobar que es verdad:
Segunda parte de comandos basicos en Linux
Ahora toca ver más comandos Básicos:
command -v
Como recordamos en el post anterior, vimos el uso del comando which para saber la ruta absoluta de un comando, pero también nos puede servir para verificar si existe cierto comando, por ejemplo si ponemos algo que no existe nos mostrara esto:

Podemos ver que queremos ver la ruta absoluta de noexiste pero obviamente ese comando no existe, por lo que nos responde con la salida: “noexiste not found”.
De esta forma podemos saber si existe un comando o no dentro de un sistema, pero también podemos usar el comando: command -v whoami:
 Esto es una alternativa en caso de que el binario de whoami no exista en el sistema y queramos saber si existen otros binarios, vemos que también nos dice su ruta absoluta.
Esto es una alternativa en caso de que el binario de whoami no exista en el sistema y queramos saber si existen otros binarios, vemos que también nos dice su ruta absoluta.
pwd, ls
El comando pwd nos sirve para saber en que directorio estamos actualmente:
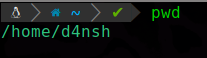
Podemos ver que estamos dentro de la ruta /home/dansh
ls : El comando ls nos sirve para listar los directorios y archivos de una ruta.
si usamos solo el ls a secas veremos los directorios y archivos de la ruta actual:

Podemos ver que hay 12 carpetas dentro de la ruta actual en la que estamos.
También podemos listar archivos no solo de la ruta actual si no también de la ruta que le indiquemos, por ejemplo queremos listar lo que hay dentro de la carpeta /home/

Y podemos ver que dentro de esa ruta existe la carpeta d4nsh.
Parametros de ls
-l nos sirve para mostrar lo mismo que lo anterior pero con más detalles, como los permisos, propietario y grupo, etc:
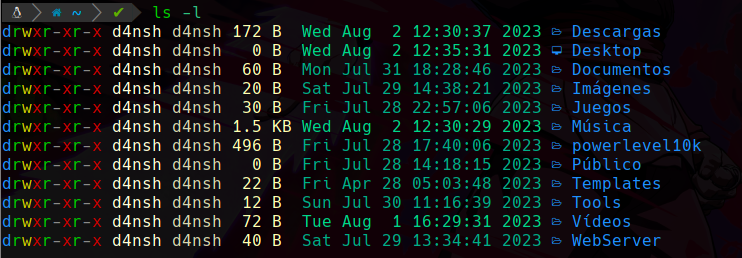
-la : Este parámetro nos sirve para listar directorios y archivos pero también nos listará los que están ocultos:
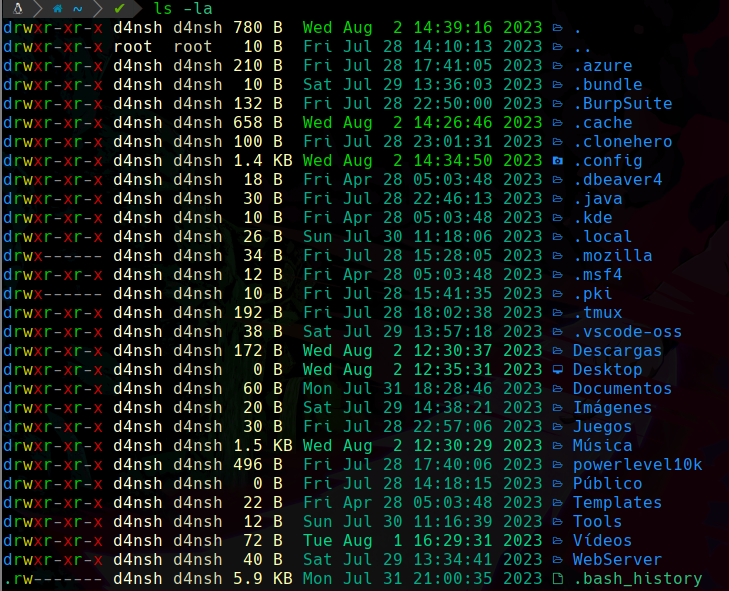
En linux los elementos ocultos inician con un punto, por ejemplo: .datos
cd y manejo de directorios
cd : Este comando nos sirve para entrar dentro de un directorio especifico, por ejemplo, hacemos un ls para listar los archivos del directorio actual:
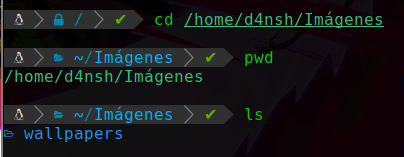
Y con el comando cd queremos entrar a la carpeta que se llama “Imágenes”, entonces haremos lo siguiente:
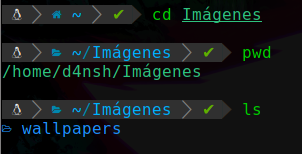
Podemos apreciar que entramos a esa carpeta, después usamos pwd para que vean que si estamos en la ruta de Imágenes, y por último hice un ls para ver que había dentro de ese directorio actual, en este caso hay otra carpeta llamada wallpapers.
Y en este caso estamos en la ruta de Imágenes, pero si queremos volver un directorio atrás , osea llegar al directorio d4nsh, entonces usaremos:
cd .. : Con este comando retrocederemos un directorio hacía atrás:
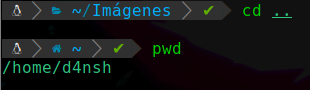
Podemos apreciar que después de retroceder un directorio usamos el comando pwd para confirmar que hemos retrocedido un directorio.
Ahora si queremos retroceder más de un directorio podemos usar lo mismo pero indicando las veces que queremos ir para atrás, supongamos que queremos ir más atrás de la carpeta d4nsh y la carpeta home, entonces usaríamos:
cd ../../
De este modo cada 2 puntos y barra inversa estamos retrocediendo un directorio, en este caso estamos retrocediendo dos, y nos deja en el siguiente directorio:
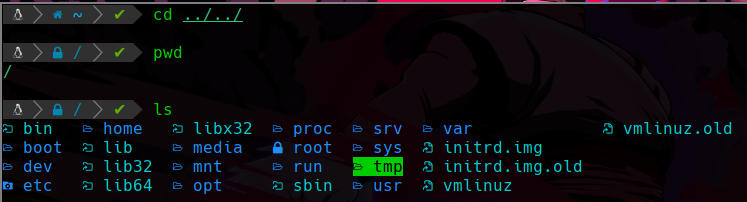
Podemos apreciar que detrás de esos 2 directorios que recorrimos hacía atrás existe uno que simplemente es el signo de barra inversa / , y esto es un directorio , es la raíz del sistema, ya no hay nada más atrás de este directorio, así que si hacemos un ls como en la imagen podemos ver que hay ciertos archivos del sistema y directorios.
Ahora si queremos ir a un directorio que esta dentro de otro y dentro de ese hay otro y así sucesivamente, entonces podemos hacer lo siguiente:
cd /home/d4nsh/Imágenes/ : Con este comando estamos viajando hasta la carpeta Imágenes ya que esa es su ruta absoluta, y si ejecutamos ese comando iremos a la ruta:
Podemos apreciar que hemos viajado hacía esta ruta nuevamente.
Al abrir una terminal, por defecto apareceremos en la ruta /home/d4nsh/ ya que es la ruta por defecto donde esta lo necesario para el usuario, cada usuario tiene asignado una carpeta dentro del directorio /home/.
Y si estamos dentro de una ruta por ejemplo en la de imágenes, y hacemos el comando cd a secas, entonces esto nos llevará a la misma ruta que nos lleva el sistema por defecto al abrir una terminal, osea en /home/d4nsh:
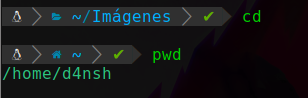
Manejo de rutas y TAB
Una vez entendimos un poco el funcionamiento del comando cd toca ir a explicar unas cuantas cosas más.
Digamos que estamos en la siguiente ruta:

Y deseamos viajar a la carpeta Imágenes pero queremos ir de una forma más rápida y no tener que escribir todo desde /home/d4nsh/Imágenes , entonces lo que podemos usar en este caso para resumir el directorio por defecto que es /home/d4nsh podemos usar esto: ~/
Este símbolo ~ representa a la ruta por defecto del sistema que es la carpeta home de nuestro usuario, por ejemplo:
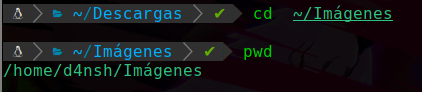
Podemos ver que viajamos a Imágenes usando el comando cd y usamos el símbolo ~ que es lo mismo que /home/d4nsh y ahora nos facilita el trabajo de no tener que escribir toda la ruta de home de nuestro usuario.
Auto-completado de rutas con TAB
Otra cosa que nos será muy útil para ahorrar tiempo viajando dentro de rutas es que podemos usar la tecla de TAB para auto-completar la ruta a la que queremos ir, por ejemplo escribimos: cd /home/d4 y al dar a la tecla de TAB esta nos auto-completará el resto que es nsh, y nos lo agrega ya que eso es lo único que empieza con d4, si hubiera otro directorio que empiece con d4 entonces tendrías que agregar más letras hasta que haya una diferencia y el único que quede sea el directorio al que quieres ir.
O otro modo es presionar TAB multiples veces ya que de esa forma se irá poniendo automáticamente todas las rutas dentro de la ruta a la que estas apuntando y si no es una vuelves a pulsar TAB para que se cambie por la que sigue y si no es esa nuevamente pulsas TAB hasta llegar a la que deseas.
Identificador de usuario e identificador de grupo
Cada usuario tiene asignado un grupo, y ese grupo tiene un valor numérico que es un identificador y también el usuario tiene un identificador.
El identificador del usuario se le llama uid
El identificador del grupo se le llama gid
Dentro del archivo passwd que se encuentra en la ruta de /etc/ dentro de ese archivo llamado passwd, podemos ver los usuarios existentes en el sistema al igual que sus uid, y gid, hagamos lo siguiente:

Estamos como ya sabemos, leyendo el contenido del archivo /etc/passwd después esos datos se pasan al pipe y grep toma esa salida de datos para filtrar por el valor “d4nsh” y nos muestra el resultado de las lineas que contienen ese valor.
Podemos ver que esta nuestro nombre, seguido de una x que es el valor de la contraseña pero después explicaremos bien esa parte, después esta un valor el cual es el 1000, y otro el cual es el 1003 y también vemos el nombre del propietario y su ruta personal home, también seguido de que tipo de shell/terminal usa, en este caso uso una zsh pero podría ser una bash o cualquier otra.
Estos valores son los del uid y gid, ya que si recordamos el comando id para ver los grupos veremos lo siguiente:
Podemos apreciar que el identificador de usuario es el 1000 que es d4nsh, y el identificador de grupo que es 1003 que igual es d4nsh ya que cada usuario tiene un grupo con su nombre.
Migracion de shell
Existe una variable de entorno llamada SHELL la cuál nos indica que tipo de shell esta ejecutando nuestro usuario:

Podemos apreciar que estamos usando una shell la cuál es ZSH, pero hay un archivo donde están todas las shell que están disponibles en nuestro sistema, este archivo esta en /etc/shells:
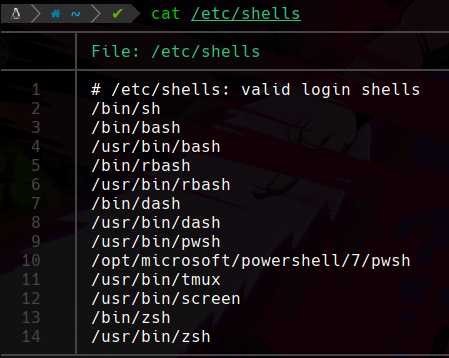
Podemos ver que hay unas cuantas, nuestra shell por defecto como vimos es ZSH pero la tuya podría ser una de estas, si queremos migrar a alguna por ejemplo quiero pasar de zsh a bash podemos usar simplemente el comando bash, podemos ver que bash esta dentro de /bin/bash y como en la variable de entorno PATH recordamos que esta la ruta /bin/:
Podemos apreciar, que esta en la sexta posición, por lo que al ejecutar su ruta relativa podremos acceder:
Podemos ver que hemos cambiado de shell a una bash.
Para volver a tu shell por defecto simplemente usa el comando exit.
Operadores logicos , control del flujo (stdout y stderr) y procesos en segundo plano
Ahora sigue ver sobre los operadores lógicos, saber que son y también control de flujo, y procesos en segundo plano.
Concatenacion de comandos
Existe una forma de concatenar comandos para ejecutar 2 o más comandos en una sola linea (one liner), por ejemplo si queremos ejecutar el comando whoami y también el comando ls en una sola linea podemos concatenar ambos usando el punto y coma ; como podemos ver:

Podemos ver que nos dio el output de los 2 comandos.
El output significa la salida de los comandos que hemos ejecutado que se muestran en pantalla.
Podemos ver que primero nos dio el output del comando whoami seguido del comando ls.
Si ponemos un comando que no existe concatenado con uno que si existe sucederá esto:

Podemos ver que el comando “whoa” no existe, pero aún así si ejecuto el ls ya que ese comando si existe, y vemos que en el output nos da un error en la salida del comando whoa, ya que no existe y nos dice que el comando no ha sido encontrado.
Cuando recibes un error en pantalla como el del comando whoa se le denomina stderr, ya que significa que hubo un error, por el contrario si todo es exitoso se le denomina stdout a la salida de tu comando como en este caso lo es el ls.
Ver codigos de estados de un comando o proceso
Cada que ejecutamos un comando, ya sea que haya sido exitoso o no, siempre por detrás se genera un código de estado ante el último comando ejecutado.
Los más comunes son los siguientes:
| Valor de estado | significado |
|---|---|
| 0 | Indica que la ejecución del comando o proceso se ha realizado con éxito. |
| 127 | Este estado significa cuando el comando dado no existe en la ruta de la variable de entorno PATH. |
| 1 | Indica que el proceso tuvo un error y nos ha mostrado una alerta sobre ese error. |
Hagamos unas pruebas con cada uno de estos estados de respuesta.
Primero ejecutaremos un comando que sea exitoso, osea que lo que hayamos ejecutado se haya realizado con éxito y como debe ser, por ejemplo un simple ls:
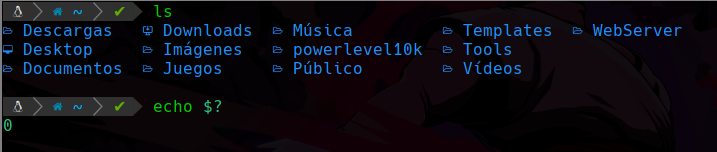
Después de ejecutar el ls, podemos ver que ejecutamos echo $? esto nos sirve para imprimir el estado que tuvo la ejecución anterior, en este caso podemos ver un valor 0 por lo que se ha realizado con éxito.
Pero por otro lado si llamamos a un comando que no existe y mostramos el estado:
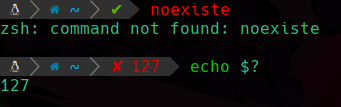
Podemos apreciar que nos ha respondido el valor 127 que como sabemos, indica que el comando no existe dentro de la variable de entorno PATH.

Podemos apreciar que intentamos leer el contenido de un archivo que no existe y su respuesta de estado fue 1, que como sabemos indica que ha habido un error con alerta.
Operadores logicos
Existen varios tipos de operadores lógicos en linux, veamos cuales son:
| Operador lógico | significado |
|---|---|
| && | Este operador “AND” significa que si ambas expresiones son verdaderas entonces nos devuelve un valor positivo (true), y si alguna de las 2 expresiones no se cumple entonces devolverá un estado de error (false). |
| || | El operador “OR” significa que aunque una de las 2 expresiones sea falsa, mientras una sea verdadera este se ejecutará sin problemas, dando 2 opciones a elegir, en caso de que la primera no se cumpla, tomara la segunda, que en caso de cumplirse devolverá un estado de respuesta verdadero (true), y obviamente si ninguna es verdadera devolverá un false. |
| ! | Y este operador no se usará por ahora ya que se toca en otros temas pero significa que si al evaluar las operaciones osea las expresiones, si esto da falso, entonces esto responderá con un estado verdadero, esto es para asegurarse de que algo no se este cumpliendo por cualquier motivo necesario, pero esto se verá después. |
Para entender mejor los primeros 2 operadores veamos ejemplos:
ejemplo del operador AND
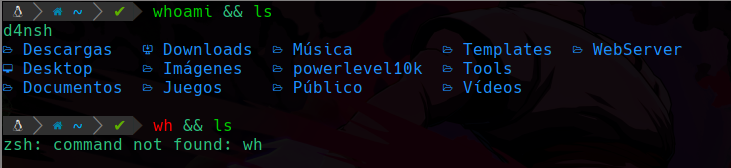
Podemos ver que en la primera ejecución pusimos whoami && ls y como ambas expresiones son verdaderas ya que existen en el PATH, entonces se ejecutará la acción, en este caso es la ejecución del comando.
Pero si vemos abajo si desde un inicio la primera expresión es falsa, ambas se tomaran como falsas y no ejecutarán su función.
Ejemplo del operador OR
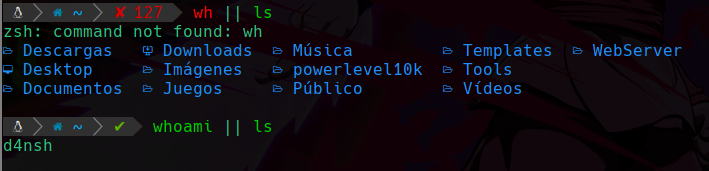
Podemos apreciar en la imagen que aunque la primera expresión no exista en el PATH la cual es en este caso “wh” , vemos que como la primera expresión no existe, entonces paso a la siguiente y la ejecuto aunque no existiera la primera expresión.
Y en la segunda ejecución vemos que siempre tomará la primera expresión pero en caso de no existir pasará a la segunda para comprobar si esa otra opción existe.
Control de flujo stdout y stderr
stderr
Al ejecutar un comando, o una instrucción que genere un error como por ejemplo, intentaremos leer un archivo que no existe:

Podemos ver que por debajo se manifiesta el mensaje de error que se le conoce como stderr ya que nos esta mostrando una salida con un mensaje erróneo.
Pero podemos ocultar esto en caso de que nos sea molesto y queramos omitir esta salida de error aunque el comando no haya sido exitoso por cualquier motivo.
Para esto usamos el control de flujo, el stderr se identifica en su control de flujo como el valor numérico 2.
Entonces podemos hacer lo siguiente:

Podemos apreciar que al ejecutar esto ya no nos mostró el aviso y en la segunda ejecución podemos ver que aunque fue un estado de error, ya no nos mostró ningún aviso de error en la pantalla, y esto fue porque redirigimos la salida del error hacía la ruta /dev/null.
La ruta /dev/null es una ruta del sistema donde todo lo que se meta dentro de esa ruta será eliminado permanentemente, es algo así como un agujero negro dentro del sistema.
Vemos que usamos 2>/dev/null después de el comando, y esto se hace para como dijimos redirigir el stderr hacía esa ruta y sea desaparecida sin verla en pantalla en ningún momento a pesar de que no haya sido una ejecución exitosa.
El número 2 indica que la salida en caso de ser errónea, entonces será redirigida a el /dev/null pero usamos el símbolo de mayor que > para redirigir el estado de error osea el 2 a la ruta > /dev/null.
stdout
De igual manera que el error, también podemos redirigir la salida de un comando exitoso.
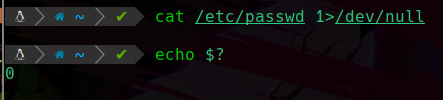
Es exitoso ya que el archivo que intentamos leer si existe, pero no queremos ver su salida.
Podemos apreciar que es lo mismo pero simplemente cambio el valor de 2 a 1 que el 1 significa stdout, salida exitosa.
redirigir ambos flujos a la vez
Ahora si queremos ocultar el estado stdout, y el stderr a la vez, haremos lo siguiente:

Podemos apreciar que usando: &>/dev/null tanto de forma exitosa y no exitosa pudimos ocultar ambos casos.
Y lo que hacemos aquí es que simplemente redirigimos las 2 salidas a la ruta que ya sabemos /dev/null/ para desaparecer cosas.
¿Para que ocultar el flujo de algo?
Puede que te estés preguntando esto ya que por el momento no parece tener sentido, pero pongamos un ejemplo sencillo.
Al abrir un programa por ejemplo:
En este caso estamos abriendo telegram desde la terminal y vemos muchas advertencias pero nosotros no queremos ver esto, por lo que podemos redirigir esto para tener la terminal limpia:

Podemos apreciar que al redirigir el flujo ya no nos muestra nada y es más cómodo estar así , pero obviamente tiene muchas funciones mejores que estas, esto solo fue un simple ejemplo.
Por ejemplo algo más extenso sería al momento ya de programar scripts en bash y requieras la ejecución de ciertos programas, comandos, etc. Entonces será muy útil esto para no llenar la pantalla de quien ejecuta el script haciendo que tenga un mal aspecto.
procesos en segundo plano
Como en el ejemplo anterior vimos que al abrir un programa o algún proceso por terminal esta se queda en espera, se quedará así a menos que cierres la terminal pero si la cierras se cerrara también el programa que haz abierto con ella.
Para solucionar esto podemos optar por poner el proceso en segundo plano.

Podemos ver que al final de la ejecución del programa pusimos un símbolo de &, y este símbolo al final de un proceso indica que lo que se va a ejecutar se haga en segundo plano, y podemos ver que nos lanza un numero que es un identificador llamado “pid” process id, el cuál se le asigno a el proceso que se abrirá en segundo plano.
Pero aún hecho esto si cerramos la terminal se cerrara el programa que abrimos con el ya que el programa aún depende de la terminal, pero para hacerlo independiente usaremos el comando disown para hacer independiente el proceso anterior:

Y de esta forma podremos cerrar la terminal sin perder el programa abierto ya que ya no depende de la terminal.
Esta no es la manera más recomendada de ejecutar programas en linux, ya que se puede facilitar simplemente ejecutándolos desde el menú de apps o desde un atajo de teclado si es que usas bspwm o algún parecido, pero explico esto ya que es muy importante para cuando profundicemos más.
Descriptores de archivo
Para crear un descriptor de archivo podemos hacer lo siguiente:
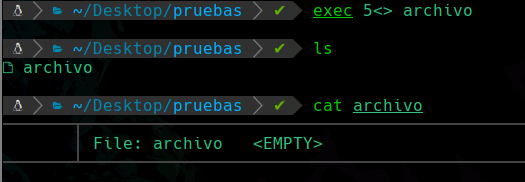
Lo que estamos haciendo aquí es que con el comando exec estamos creando un descriptor de archivo, este descriptor que estamos creando se identificara con el ID 5, y contendrá permisos para leer y escribir dentro de ese archivo, esto se lo indicamos usando los <> el símbolo de menor que significa que asignas el permiso de lectura, y el símbolo de mayor que, significa que asignas el permiso de escritura en el descriptor de archivo, y por último le damos un nombre al archivo en este caso será “archivo”.
Una vez lo creamos hicimos un ls para apreciar que el archivo se ha creado y al hacerle cat nos dice que no contiene nada y es normal ya que no hemos metido ningún contenido.
Redirigir un output dentro de un descriptor de archivo
Si queremos redirigir la salida de un comando hacía el descriptor de archivo que hemos creado podemos hacer lo siguiente:
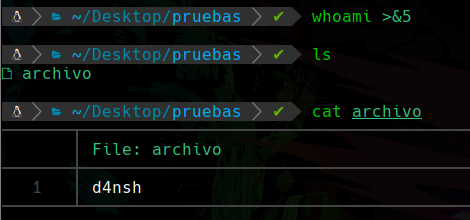
Lo que estamos haciendo es redirigir la salida del comando whoami usando el símbolo > y con el & lo que hacemos es llamar a el id 5 que sabemos que es del archivo que creamos anteriormente, por lo que al ejecutar eso y leer el contenido del archivo vemos que ahora la salida del comando whoami se ha redirigido hacía el descriptor de archivo.
Y si ahora queremos meter otro output dentro del mismo descriptor de archivo podemos hacerlo:
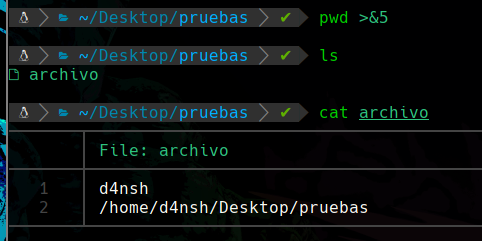
Podemos apreciar en la primera ejecución que se esta enviando el output del comando pwd hacía el descriptor de archivo con el id 5, en este caso es el que creamos antes.
Y al leer el archivo podemos apreciar que se agrego el contenido encima del anterior sin reemplazarlo, de esta forma se guardan multiples cosas sin ser reemplazadas.
Finalizar de escribir en un descriptor de archivo
Si ya no queremos meter datos dentro de un descriptor de archivo podemos cerrarlo de la siguiente forma:

De esta forma ya no podremos meter datos dentro de este descriptor de archivo ya que lo hemos finalizado.
Y si intentamos meter datos nos saldrá esto:

Podemos ver que ya nos sale un error ya que ya hemos cerrado el descriptor de archivo anteriormente.
Hacer copias de un descriptor de archivo
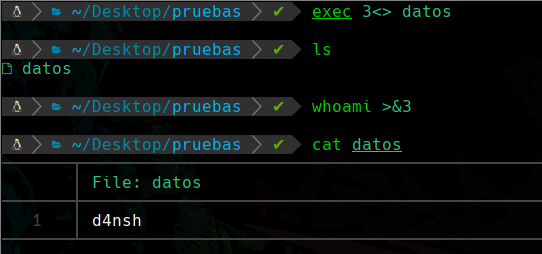
Creamos un nuevo descriptor de archivo con el id 3, permisos de escritura y lectura, y que se llame “datos” en este caso.
Después le metemos algo, en este caso el output del comando whoami, y al mostrar su contenido vemos que se guardo con éxito.
Ahora para hacer una copia de este descriptor haremos lo siguiente:
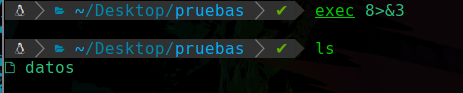
Podemos ver que con exec asignamos un nuevo descriptor de archivo con el id 8, y con >&3 indicamos que ese nuevo descriptor apuntará a el descriptor con id 3.
Y vemos que no se duplico el archivo, ya que lo que se duplica es el descriptor en si con el contenido más no el archivo.
Ahora si metemos datos dentro del nuevo descriptor:
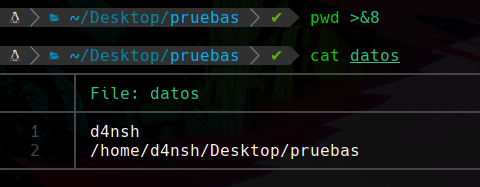
Podemos apreciar que aunque metimos el output del comando pwd dentro del descriptor con el id 8, vemos que se refleja dentro de el archivo “datos” que pertenece al descriptor con el id 3.
Si cerramos el descriptor con el id 3:
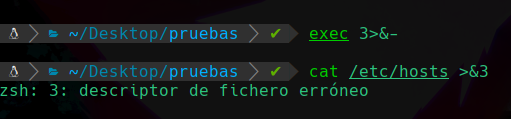
Vemos que ya no nos deja obviamente ya que lo hemos cerrado, pero aún tenemos el duplicado y podremos hacerlo desde ese:
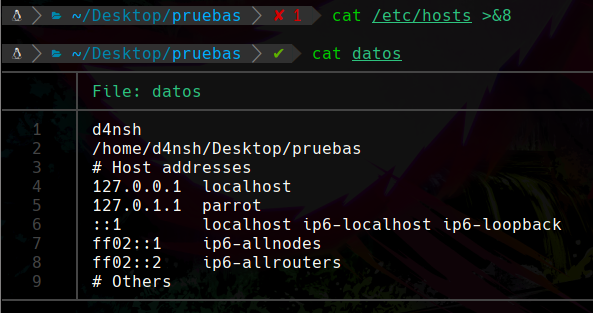
Podemos ver que aquí si nos permitió meter el output al descriptor con el id 8, el cuál apunta hacía el archivo datos ya que al duplicarlo obtuvo esa referencia por lo que vemos que se ha pasado correctamente el output.
No olvides cerrar el descriptor copia.
Lectura e interpretacion de permisos + modos de escribir en archivos
Antes de ver la lectura e interpretación de permisos veremos algo básico pero necesario.
Comando file y escritura en archivos
file : Este comando se usa para crear un archivo, por ejemplo:

Podemos ver que hemos creado un archivo llamado “archivo.txt” el cuál vemos que se creo correctamente al verificarlo con un ls.
Ahora hay multiples formas de editar el contenido de un archivo, por ejemplo si queremos meter un texto dentro del archivo podemos hacerlo así:

Podemos ver que estamos metiendo el output del comando echo con el contenido que queremos meter dentro del archivo, ya sabemos que con el símbolo de mayor que se redirige el output hacía un sitio, en este caso al archivo.
Y vemos que al hacerle un cat leemos su contenido.
Pero si intentamos meter más texto a ese mismo archivo de esta misma manera sucederá lo siguiente:
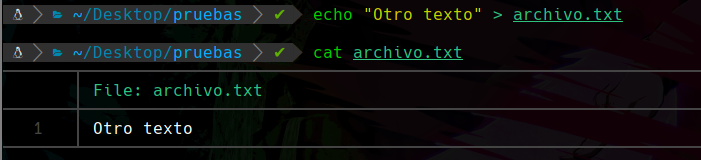
Podemos apreciar que el texto anterior se ha borrado y a cambio se ha sobrepuesto este texto nuevo.
Para evitar que un contenido se sobre-escriba encima del otro, haremos uso de dobles símbolos de mayor que:
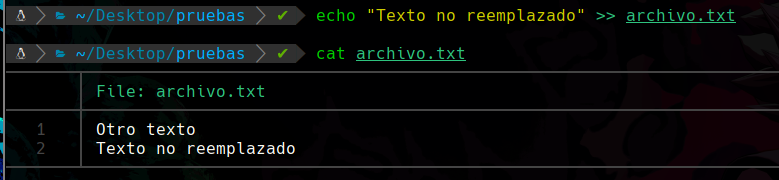
De esta forma el texto anterior ya no sera reemplazado.
Uso de nano
Otra forma de editar archivos más fácil es usando el editor de texto nano:

Al ejecutar este comando y al darle el archivo que queremos editar nos abrirá lo siguiente:
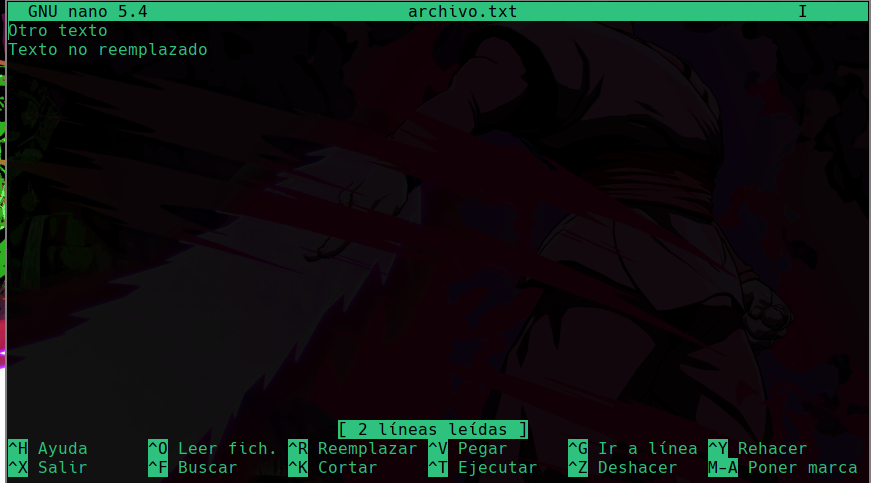
Desde aquí mismo ya podemos ir editando el texto.
Abajo vemos una serie de elementos que nos pueden ayudar, el símbolo de ^ significa ctrl, por ejemplo para salir se usa ctrl + x, o para buscar algo dentro del archivo se usa ctrl + f, para cortar una linea entera de texto se usa ctrl + k pero debes tener el cursor a partir de donde quieres cortar el contenido.
Para pegar contenido que tengas en el portapapeles, en nano se pega contenido con ctrl + shift + v y para copiar ctrl + shift + c.
Y por último para guardar el contenido se usa ctrl + s.
Ahora pasaremos a la parte de los permisos en el sistema.
Lectura e interpretacion de permisos, mkdir
Con el comando mkdir nos sirve para crear un nuevo directorio, osea una carpeta:

La carpeta la hice para explicar los permisos.
Al hacer un ls -l veremos lo siguiente:

Si podemos ver bien, primero están los permisos que en breve profundizaremos en ellos.
Después nos muestra el propietario y grupo al que pertenece ese archivo o directorio, también vemos su peso, y hora de creación etc.
Pero lo que nos interesa es lo de los permisos:
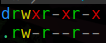
En los permisos del directorio nos muestra “d” al inicio que indica que es un directorio.
Y en los permisos del archivo nos muestra un simple punto “.” al inicio para saber que se trata de un archivo.
Vemos lo siguiente en los permisos del directorio:
rwx r-x r-x
Estos valores siempre se separan en conjuntos de 3, la “d” no la tomamos en cuenta ya que solo indica que es un directorio.
| Permiso | significado | |
|---|---|---|
| r | permiso de lectura en el archivo o directorio. | |
| w | permiso de escritura en el archivo o directorio. | |
| x | permiso de ejecutar un archivo, programa, etc, pero en caso de que este permiso este en un directorio, indica que podemos entrar a dicho directorio. |
Si vemos en los permisos del directorio:
rwx r-x r-x
Podemos ver que los hemos separado en 3 conjuntos, ¿y esto porque?: Lo hacemos así ya que cada conjunto de estos permisos pertenecen a lugares diferentes.
El primer conjunto pertenece a los permisos que el usuario propietario de ese directorio tiene sobre ese directorio.
El segundo conjunto pertenece a los permisos que el grupo al que pertenece ese directorio tiene sobre el, por ejemplo si algún usuario dentro de la red de mi linux tiene asignado el grupo al que pertenece este archivo, entonces se le asignaran estos permisos del segundo conjunto.
Y por último el tercer conjunto pertenece a otros, por ejemplo alguien que no es dueño del archivo y no esta en el grupo del archivo, entonces se le asignan esos permisos del tercer conjunto.
Siempre van en orden rwx rwx rwx pero al desactivar un permiso se usa un guion.
Por eso vemos que el propietario tiene todos los permisos, los grupos solo pueden leer, y ejecutar pero no escribir.
Y con los otros es lo mismo que grupos.
Un ejemplo mas para aclarar la lectura de permisos
Ahora veremos los permisos del archivo:
.rw- r– r–
Sabemos que el punto indica que es un archivo y no un directorio que en su caso sería “d”.
Ahora los separamos en conjuntos de 3:
rw- r– r–
Si entendimos bien, sabremos que el propietario tiene permiso de leer y escribir en el archivo pero no de ejecutarlo.
Los grupos y otros solo pueden leer el archivo pero no modificarlo ni ejecutarlo.
Prueba de permisos
Haremos otra prueba para entender un poco más, listamos con detalle el siguiente archivo:

Podemos ver que en este caso nosotros somos parte del grupo de otros ya que no somos el propietario, y tampoco estamos en el grupo root, podemos verlo con id:

Por lo que no estamos tampoco en el grupo, así que nuestros permisos son los de otros.
Sabemos que se separa de 3 conjuntos:
| propietario | grupo | otros |
|---|---|---|
| rw- | r– | r– |
Y pertenecemos al último conjunto que es el de otros, así que se nos asignas esos permisos hacía ese archivo.
Podemos leer el contenido:
Pero no podemos modificarlo:

Ya que no tenemos los permisos de escritura en este archivo.
Asignacion de permisos
Ahora que ya sabemos leer los permisos, vamos a aprender a asignar esos permisos.
Cuando somos el propietario ya sea de un directorio, archivo, etc. Podemos modificar también el grupo al que pertenece ese archivo y también su propietario.
Veamos un ejemplo:
Primero entre como el usuario root para crear un archivo y después con
su d4nshvolví a ser el usuario d4nsh para hacer la prueba.
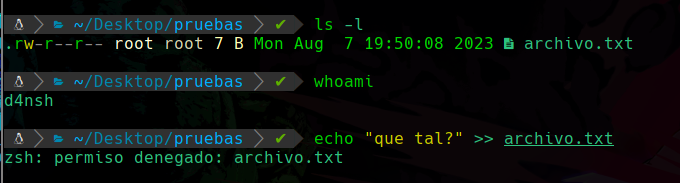
Ya como el usuario d4nsh, podemos ver que hay un archivo el cuál el propietario es root, y su grupo es root.
Como no somos el propietario, como podemos ver en la segunda ejecución vemos que somos d4nsh, así que nuestros permisos son los del último conjunto los cuales son solo de lectura.
Y podemos ver que no podemos escribir en el archivo ya que no tenemos permiso.
Así que volvemos a convertirnos en root con sudo su para poder modificar los permisos y ver como se hace:

Primero, podemos apreciar que usamos whoami para mostrar que nos convertimos en root.
Después mostramos los permisos del archivo, los cuales son: rw- r-- r-- y vemos que “otros” no tienen permiso de escritura pero se lo queremos agregar.
Así que usaremos el comando chmod esto sirve para modificar los permisos de algo.
En este caso como somos el propietario ya que root lo es, entonces podemos modificar los permisos de este archivo, así que queremos que los que pertenecen a “otros”, tengan el permiso de escritura sobre ese archivo.
Por lo que haremos lo siguiente:

Podemos ver que usamos: chmod o+w archivo.txt
Lo que significa esto es que la o significa “otros”, y el símbolo de + significa que asignaremos un permiso, la w es para asignar ese permiso, y pasamos el archivo al cual se le modificaran esos permisos, en este caso es archivo.txt.
Y podemos ver abajo que al hacer nuevamente un ls -l apreciamos que el permiso “w” de escritura ya esta asignado en “otros”, y al volver a ser d4nsh y intentar meter contenido ya podremos ya que hemos asignado ese permiso:
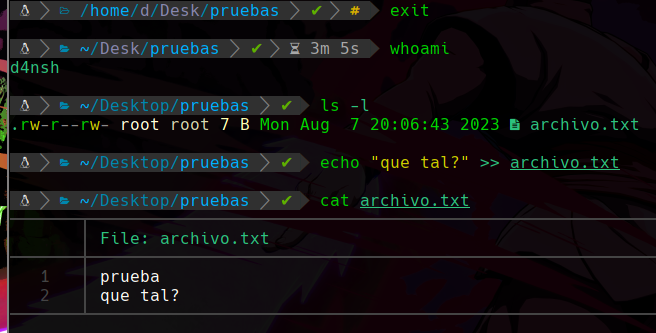
Vemos que hacemos un exit para volver a ser d4nsh, después mostramos el permiso que vimos que se asigno anteriormente y probamos meter contenido que antes no pudimos y ahora si ya que tenemos el permiso en “otros”.
Y podemos ver que el contenido se agrego correctamente gracias a la asignación del permiso de escritura en “otros”.
Ahora si queremos remover un permiso se usa el signo de menos - en lugar del de + y de esta forma asignamos y removemos permisos.
Y si quieres cambiar permisos del propietario se usa u que significa user.
Si quieres cambiar el permiso de grupos se usa g que significa group.
Recordemos estos valores:
| Letra | significado |
|---|---|
| u | propietario. |
| g | grupo. |
| o | otros |
Y los símbolos:
+ para asignar un permiso.
- para remover un permiso.
Cambiar diferentes permisos en una sola linea
Ahora si queremos cambiar diferentes permisos en una sola ejecución, veamos como se hace.
Supongamos que queremos cambiar:

estos permisos, por otros.
rw- r– rw-
Queremos cambiarlos por:
rwx rwx r–
Por ejemplo.
Así que haremos lo siguiente:

Apreciamos que separamos con una coma al momento de asignar los de cada conjunto.
Y podemos adjuntar varios en uno solo como fue en el g+wx esto para asignar los 2 permisos de ese conjunto, por lógica también podemos hacer esto al remover permisos.
Cambiar grupo de un archivo/directorio
Para hacer esto usaremos el comando chgrp que significa change group, cambiar grupo, y le pasamos el grupo al que queremos que se cambie el archivo dado:
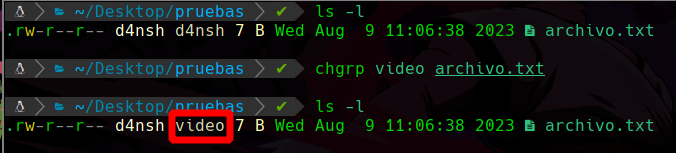
Podemos apreciar que el grupo de el archivo.txt ha cambiado del grupo d4nsh a el grupo video, como vemos en la imagen.
De esta forma se cambia el grupo a algo.
Cambiar propietario de un archivo/directorio
Y ahora para cambiar el propietario usamos el comando chown de change owner, cambiar propietario, y le pasamos el propietario que queremos que se cambie el archivo o directorio dado:
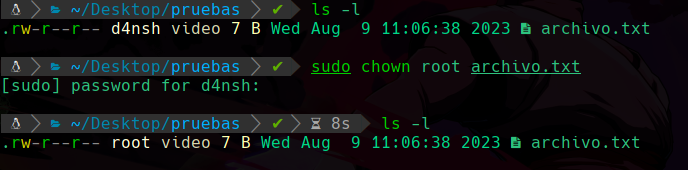
Podemos apreciar que esta vez usamos los permisos de sudo ya que como es root necesitamos su permiso para asignarle un archivo como propietario.
Y abajo podemos aperciar que el usuario propietario del archivo ya es root y no d4nsh.
De esta forma podemos cambiar el propietario de algo.
Asignar propietario y grupo en un solo comando
Veamos:
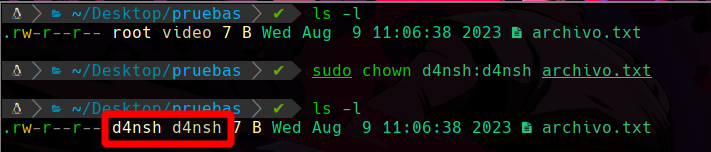
Podemos apreciar que usamos el comando que se usa para cambiar el propietario chown pero esta vez hicimos:
sudo chown d4nsh:d4nsh archivo.txt
Vemos que ponemos en el primer apartado d4nsh, que indica el propietario al que se cambiara el archivo, pero si también ponemos separado de dos puntos : el grupo, entonces esto automaticamente lodetectará que el segundo valor es para asignar el grupo y primero el propietario , para no usar 2 comandos diferentes, por lo que al hacer eso podemos ver debajo que el propietario y el grupo han sido cambiados a d4nsh.
Y fue gracias a el comando chown que pudimos hacer esto, recuerda:

Vemos que podemos hacerlo en un solo comando, también podemos usar el comando chgrp del mismo modo y esto funcionará igual pero obviamente en lugar de que primero sea el usuario el que se asigne, será el grupo ya que es su comando.
Y vemos que usamos sudo ya que como le quitaremos el propietario a root necesitamos su permiso ya que es el propietario y necesitamos su confirmacion.
Crear un nuevo usuario
Ahora aprenderemos a crear un usuario nuevo, primero necesitamos ser root para hacer modificaciones en el sistema.
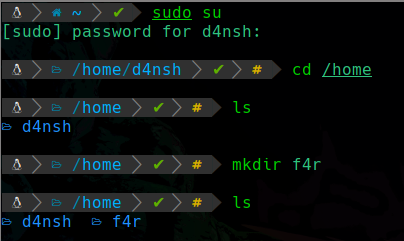
Podemos ver que siendo como root, creamos el directorio f4r dentro de la ruta /home/ Y esto es porque este directorio home será la carpeta por defecto de un nuevo usuario que vamos a crear:

Lo que hicimos en este comando primero fue usar el comando useradd seguido de sus parametros , el primero es el nombre del nuevo usuario, en este caso es “f4r”, después con -s indicamos que tipo de shell va a tener ese usuario, le indicamos que tendrá una bash /bin/bash y por último con el parametro -d le indicamos cúal va a ser su directorio personal, en este caso es el que creamos anteriormente /home/f4r.
Y podemos confirmar que se creo el usuario leyendo el archivo /etc/passwd:

Vemos que se ha creado el usuario f4r y vemos que tiene su directorio personal al igual que la shell bash asignada.
Ahora le asignaremos una contraseña a este nuevo usuario, para ello usamos el comando passwd y le pasamos como parametro el usuario a modificar la contraseña:
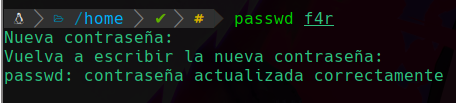
Podemos ver que hemos asignado la contraseña al usuario f4r correctamente.
Ahora vemos que al hacer un ls -l podemos apreciar que el directorio de f4r le pertenece a root y también al grupo root:

Pero queremos que le pertenezca al usuario f4r, por lo que lo vamos a modificar:

Podemos apreciar que hemos modificado correctamente el propietario y grupo del directorio f4r.
No usamos sudo antes de ejecutar el comando ya que ya estamos como el usuario root y no es necesario.
Migrar a otro usuario
Ahora migraremos a el nuevo usuario f4r, usaremos su f4r y entraremos automaticamente:
Podemos ver que al hacer simplemente este comando entramos como el usuario f4r, y no nos pidio la contraseña de f4r ya que como estabamos como root y tenemos los maximos privilegios sobre el sistema entonces tenemos admitido entrar a cualquier usuario sin proporcionar su contraseña.
Pero si estuviesemos como d4nsh, si nos pediria la contraseña al intentar migrar:
Podemos apreciar que aquí si nos pidió la contraseña del usuario f4r, ya que d4nsh no tiene permisos de acceder a cualquier usuario como root.
Podemos ver que estamos en la ruta /home en un inicio, pero vemos que si usamos el comando cd este nos llevará a nuestro directorio personal como podemos comprobarlo con pwd:
Esto fue gracias a que asignamos esta ruta como su directorio personal.
Crear nuevo grupo
Ahora aprenderemos a crear nuevos grupos, en este ejemplo crearemos el grupo “Testing”:

Recuerda estar como root al crear usuarios,grupos,modificar contraseñas, y cualquier actividad que requiera modificaciones en el sistema que cualquier usuario no privilegiado no pueda hacer.
Podemos apreciar que hemos creado el grupo correctamente usando el comando groupadd y pasandole como parametro el grupo a crear.
Después comprobamos que se ha creado este grupo “Testing” al comprobarlo en el archivo /etc/group, y podemos ver que se le asigno un gid(group id) con el valor de 1005 y también vemos que no aparece ningún usuario ya que nadie esta en este grupo por ahora.
Asignar usuarios a grupos
Ahora para asigar usuarios a un grupo, en este caso asignaremos al usuario f4r al grupo “Testing”:

para ello usamos el comando usermod con el parametro -a que significa añadir algo a un usuario, y lo que le añadimos es al grupo que se pasa en el parametro -G en este caso es Testing, y por último le pasamos el usuario al que se le aplicarán estos cambios.
Y si vemos abajo en el cat podemos apreciar que ahora ya hay un usuario dentro del grupo “Testing” que podemos leer en el archivo /etc/group/.
Ahora migraremos a el usuario f4r y podremos ver que al hacer id se encuentra el grupo que asignamos anteriormente:
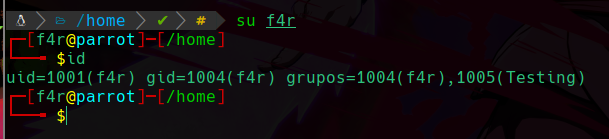
Vemos que aparece el grupo Testing al cual pertenece el usuario f4r.
Ejemplo extra de permisos
Veremos un último ejemplo sobre estos temas para repasar, crearemos una carpeta la cuál solo los que pertenecen al grupo Testing, puedan atravesar un directorio y escribir dentro de el.
Primero creamos el directorio:
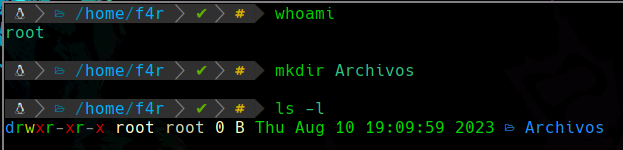
Podemos ver que hemos creado un directiro llamado Archivos, y como somos root, el propietario y grupo de este directorio es root como podemos ver.
Ahora con el comando chgrp hemos cambiado el grupo de ese directorio a el grupo Testing:

Podemos ver que ya pertenece este directorio a el grupo Testing.
Ahora solamente queda modificar los permisos como queremos, que otros no puedan atravesar el directorio ni leer nada dentro, y que solo el propietario y el grupo puedan escribir, leer y atravesar ese directorio:

Y podemos apreciar que hemos asignado los permisos usando chmod como lo explicamos pero esta vez aplicado a lo requerido que en este caso es que solo el propietario y el grupo tengan control sobre el directorio pero no “otros”.
Como el usuario d4nsh no esta dentro del grupo Testing, no podra ingresar al directiro ni hacer nada sobre el:
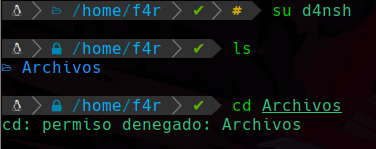
Esto es ya que el usuario d4nsh no es el propietario ni pertenece al grupo, por lo que sus permisos son los de “otros”, pero como lo configuramos sin ningun permiso entonces no podra hacer nada el usuario d4nsh sobre ese directorio.
Y por otro lado con el usuario f4r si que podremos atravesar el directorio, escribir y leer:
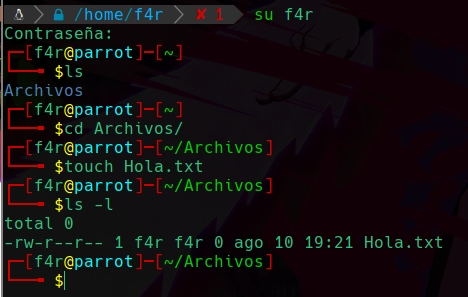
Podemos apreciar que como el usuario f4r pertenece al grupo Testing, tenemos los permisos de grupo.
Notacion octal de permisos
Ahora veremos otra manera de asignar permisos, esto se hace de la siguiente forma, por ejemplo tenemos este archivo:

Sus permisos son los siguientes:
rw- r-- r--
Ahora después de separarlos en 3 conjuntos, en una hoja o donde quieras , debes agregar los siguientes valores por debajo:
rw-ㅤㅤr--ㅤㅤr--
|||ㅤㅤ|||ㅤㅤ|||
110ㅤㅤ100ㅤㅤ100
Si hay un permiso, agregamos un “1”, y si no hay un permiso agregamos un “0”.
Después vamos a agregar unas posiciones imaginarias:
rw-ㅤㅤr--ㅤㅤr--
|||ㅤㅤ|||ㅤㅤ|||
110ㅤㅤ100ㅤㅤ100
|||ㅤㅤ|||ㅤㅤ|||
210ㅤㅤ210ㅤㅤ210
Agregamos las posiciones en orden en cada conjunto en relación a los valores de arriba, estas pociciones inician desde 0 contando hasta 2. o sea 012, pero al revés.
Ahora se elevará el numero 2 a el exonente de la posicion, pero esto solo si en esa posicion hay un permiso.
Por ejemplo:
Empezaremos con el primer conjunto para no confundirnos:
rw-
|||
110 <--- binarios.
|||
210 <--- posiciónes.
En la posición 0 no hay permiso en su binario de arriba ya que hay un 0 arriba, por lo que se ignora ya que indica que no hay un permiso ahí.
En la posición 1 si hay permiso ya que hay un 1 en su binario de arriba, lo que indica que hay un permiso, por lo que elevamos 2 a el valor de esa posición, en este caso: 2¹ que nos da: 2
Y en la posición 2 también hay un permiso, por lo que elevaremos 2 a el valor de esa posición: 2² que nos da: 4
Luego sumamos estos valores: 2 + 4 = 6.
Y haremos esto mismo con los otros 2 conjuntos restantes:
r--
|||
100 <--- Ponemos los valores en binario, recuerda, 1 se pone si encima hay un permiso, y 0 si no hay.
|||
210 <--- Agregamos las posiciones 0,1,2 pero al revés.
Ahora sigue elevar el 2 dependiendo las posiciones y que exista un permiso, en la posición 0 no hay permiso arriba en el binario, por lo que se queda vacio.
En la posición 1 tampoco hay permiso por lo que se queda vacío.
Y en la posición 2 si hay permiso, por lo que elevamos el 2 a el valor de la posición: 2² que es igual a: 4.
Y como solo había 1 permiso en este conjunto entonces ya no hay con que sumarlo y se pasa así.
El tercer conjunto es lo mismo que el anterior por lo que igual es igual a 4.
Y una vez terminado nos quedarán así los permisos ya elevados:
rw- r-- r--
6 4 4
Ahora tenemos el valor 644, este valor equivale a los permisos que vimos en un inicio dentro del archivo.
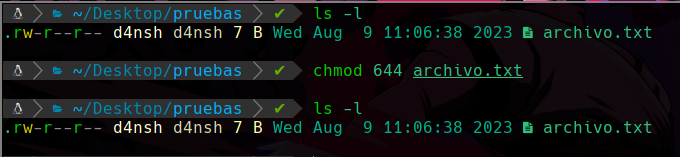
Podemos ver que aplicamos este valor usando el comando chmod, y pasandole el archivo, y al comprobar nuevamente los permisos con ls -l, vemos que no se modifico nada ya que sus permisos son los que asignamos que ya tenian.
Otro ejemplo para aclarar
Ahora supongamos que a ese mismo archivo anterior, queremos cambiarle los permisos a estos:
rwx r-x r-- <--- permisos.
Empezamos haciendo el binario dependiendo de si hay un permiso o no:
111 110 100 <--- binario.
Ahora agregamos las posiciones:
111 110 100 <--- Binario.
210 210 210 <--- Posiciones.
Ahora elevaremos el 2, a la potencia que nos indica la posición, recuerda que solo se aplica esto en caso de que haya un permiso en esa posición.
Primer conjunto:
rwx <--- permisos.
|||
111 <--- binario.
|||
210 <--- posición.
En la posición 0 hay un permiso, por lo que elevaremos 2 a la potencia de esa posición: 2⁰ que es igual a 1.
En la posición 1 hay un permiso, por lo que elevaremos 2 a la potencia de esa posición: 2¹ que es igual a 2.
Por último la posición 2 tiene un permiso, por lo que elevamos el 2 a la potencia de esa posición: 2² que es igual a 4.
Sumamos estos valores y tenemos: 7
Ya sacamos el primer valor numerico del primer conjunto, ahora sacaremos los de los otros 2 conjuntos restantes:
segundo conjunto:
r-x <--- permisos.
|||
101 <--- binario.
|||
210 <--- posición.
2 se eleva a la posición 0, ya que hay permiso en la posición: 2⁰ = 1.
En la posición 1 no hacemos nada ya que no hay permiso en la posición.
2 se eleva a la posición 2, ya que hay permiso en la posición: 2² = 4.
Al sumar esto da 5.
Hemos sacado el valor del segundo conjunto.
Por último sacaremos el tercer conjunto:
r-- <--- permisos.
|||
100 <--- binario.
|||
210 <--- posición.
Posición 0 y 1 se omiten ya que no hay permisos en sus posiciones.
La posición 2 tiene permiso, por lo que elevamos el 2 a esa posición: 2² = 4.
Y como no hay nada más con que sumarlo de este conjunto entonces ya tenemos el valor de este conjunto: 4.
Ahora ya sacamos el valor del tercer conjunto.
Y ya tenemos los valores de los 3 conjuntos, ahora simplemente los juntamos: 754
Y al asignar este valor a el archivo veremos que se asignaron los permisos deseados:
rwx r-x r-- <--- permisos deseados.
Resultado:
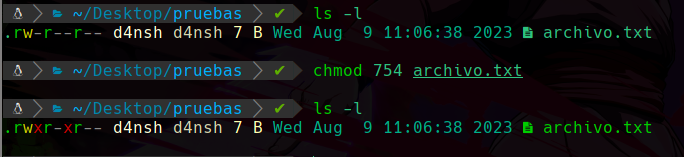
Y podemos apreciar que se aplicaron correctamente como lo deseamos.
Esto puede resultar muy tardado para algo simple pero con el tiempo, sobre todo si practicas vas a lograr hacerlo mucho más rapido y se te quedarán ciertos valores grabados.
Alternativa por si la anterior te parece complicada
Aquí veremos otra manera de hacer esto un poco más rapido.
Supongamos que tenemos la siguiente serie de permisos que queremos saber su valor numerico:

Ahora en lugar de agregar lo de binario, vamos a agregar los valores en orden: 4,2,1 , y en caso de no haber permiso no ponemos nada:
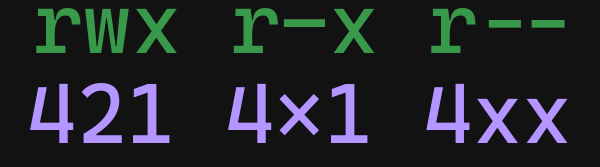
¿Y porque esto?
Esto de 421, son los valores de 2 elevado a 0,1 o 2, como lo haciamos anteriormente, pero ahora solo ponemos los resultados de cada permiso y tomamos en cuenta los que tengan permiso, y los que no les ponemos una X para saber que no hay permiso.
Sumaremos los valores del mismo conjunto siempre y cuando encima de su valor exista un permiso, entonces los que tengan permiso se sumaran con su valor que esta dentro del mismo conjunto siempre y cuando tengan un permiso arriba.
Como vemos en la imagen:
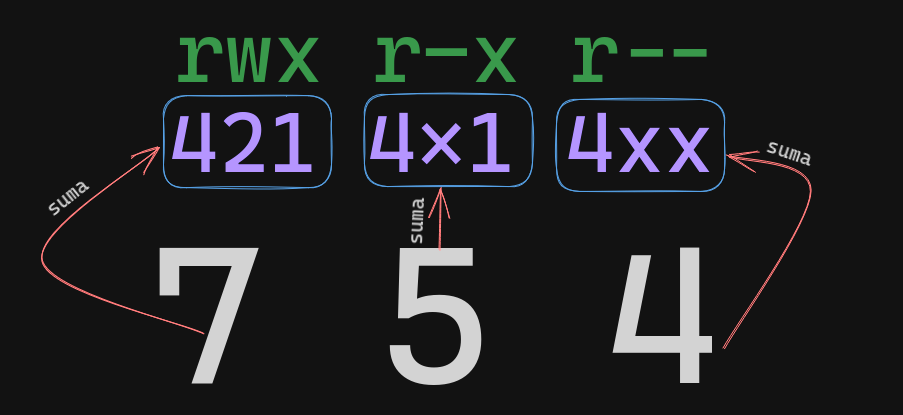
Apreciamos que en el primer conjunto, esta rwx, por lo que sus valores de abajo se sumaran entre si, dando como resultado 7, que es el primer valor que formamos en el valor numerico de esos permisos.
En el segundo conjunto esta r-x vemos que no esta el permiso de escritura, por lo que debajo de sus valores solo se sumarian el 4 y el 1 dando el resultado 5, que este es el segundo valor que se forma en el valor numerico de estos permisos.
Y en el último conjunto solo hay un permiso: r-- el cual es el de lectura, entonces su valor de abajo se pasa así ya que no hay con que sumarlo, dando resultado 4, y con esto terminamos los 3 conjuntos.
Por lo que el valor de estos permisos es: 754.
Y al asignarlos:
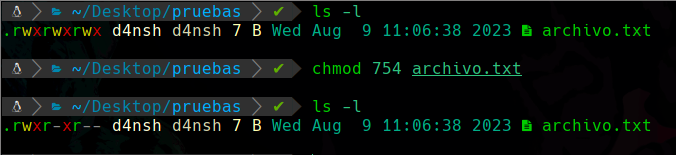
Vemos que agregamos con el comando chmod exactamente los permisos que queriamos agregar en un principio.
Esta forma de asignar permisos es la más rapida y recomendada, pero debes saber el porque del 4,2,1 por eso explique la manera compleja para que sepas que viene de ahí.
Permiso especial Sticky Bit
Pongamos una situación para entender lo que hace este permiso.
Supongamos que tenemos este directorio con estos permisos:

Vemos que el usuario propietario y grupo de este archivo es d4nsh, y este directorio vemos que tiene permisos de todos para todos.
Pero dentro de este directorio esta el siguiente archivo:

Y podemos ver que los grupos y otros solo tienen permitodo leer el contenido, y no tienen permiso de escritura ni ejecución.
Ahora migraremos a el usuario f4r:
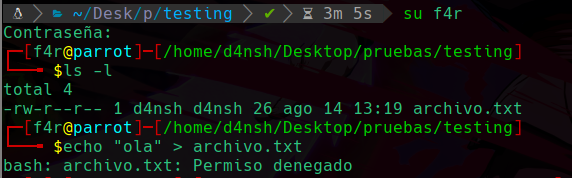
Podemos apreciar que migramos al usuario f4r, y como no es el usuario propietario ni esta en el grupo del archivo creado anteriormente entonces no podemos meter datos como vemos.
Si no tenemos permisos de modificar el archivo entonces tampoco podremos eliminarlo ¿cierto?, esto no es así:
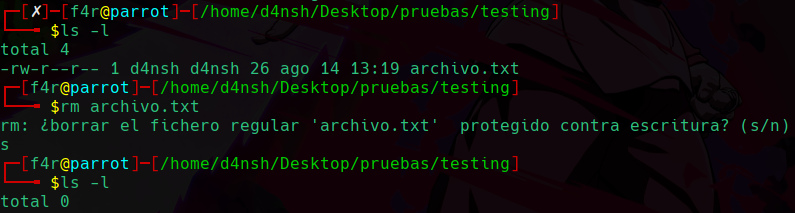
Podemos ver que pudimos eliminar el archivo al que supuestamente solo teniamos permiso de lectura, y ¿porque sucede esto?: Esto se debe gracias a que el directorio en el que se encuentra este archivo, tenemos permiso de escritura, entonces tendremos permiso de modificar dentro de los archivos de este directorio.
Por eso pudimos eliminarlo, y aunque no es seguro tener cosas con todos los permisos en todos, lo hicimos solo para entender este ejemplo.
Ahora si queremos evitar esto sin tener que cambiar los permisos de otros o grupos, podemos usar el permiso Sticky Bit en el directorio.
Ahora como el usuario d4nsh, en este caso asignamos el permiso especial sticky bit usando +t a el directorio testing en este caso:
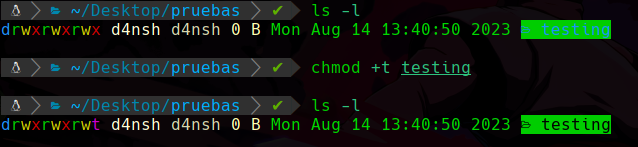
Esto nos permitira que nadie pueda modificar el archivo, ni si quiera si el que tiene permisos de escritura en ese directorio podrá, solo va a poder el propietario o el usuario root.
Y luego creamos el archivo que eliminamos anteriormente de nuevo, pero ahora para ver que ya no se puede eliminar:
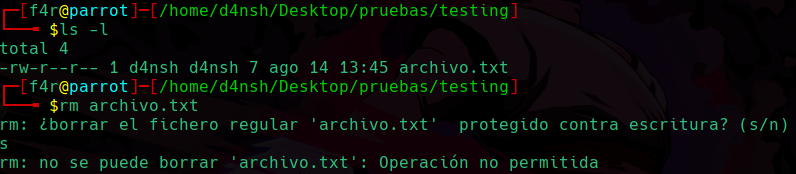
Podemos ver que no podemos eliminar el archivo, gracias al permiso especial asignado en el directorio.
Control de atributos de ficheros en Linux Chattr y Lsattr
Necesitamos un archivo para usarlo de ejemplo, por esto haremos una copia de un archivo, por ejemplo del /etc/hosts/, para copiar el archivo usaremos el comando cp:
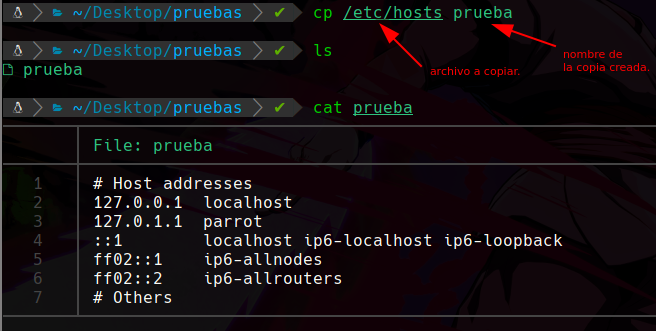
De esta forma hemos copiado el archivo hosts dentro del archivo prueba, y vemos que el contenido se guarda por lo que sabemos que se copio correctamente.
Ahora ya tenemos una copia de ese archivo para pruebas y no dañar el original.
El comando lsattr nos sirve para listar los archivos y ver los permisos especiales que estos contienen en caso de tenerlos.
Por ejemplo:

Podemos ver que hemos listado los permisos especiales de el directorio actual, y podemos ver que esta el archivo que copiamos, pero no tiene ningun permiso especial.
El permiso especial que le agregaremos será el i, que se agrega con el comando chattr +i -V archivo en este caso:
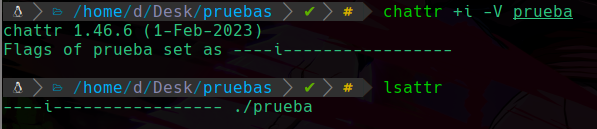
Podemos apreciar que se agrego correctamente, necesitamos estar como root para asignar este permiso especial, el +i en el comando es para agregar ese permiso especial, y el -V es para aplicar el llamado “verbose” que esto significa que nos mostrará los cambios en pantalla como se ve al momento de asignar el permiso, y volvemos a confirmar que se agrego usando el lsattr y vemos que se ha agregado el permiso “i”.
Y lo que hace este permiso especial es que no nos dejara eliminar ese archivo por nadie ni si quiera por root:
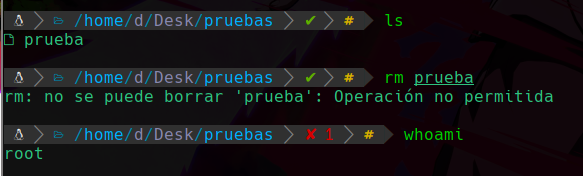
Y podemos apreciar que no podemos eliminarlo gracias a el permiso especial que hemos asignado, para eliminar el archivo tendriamos que quitar el permiso pero esta vez para quitarlo se usa un -i y no un +i:
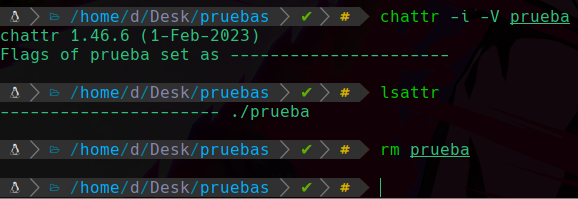
Y podemos ver que al quitarlo ya nos dejara eliminarlo, este permiso sirve para que no puedas eliminar cosas importantes por error, u otros usos más.
Permisos especiales SUID y SGID
El permiso SUID y SGID, vienen de que es un permiso especial que se proporciona a un archivo o grupo este permiso especial es el cuál nos permitirá ejecutar temporalmente ese archivo en el contexto del usuario propietario aunque no lo seamos.
Por ejemplo si tenemos el archivo ejecutable que se les llaman binarios en linux, si tenemos uno y tiene este permiso especial SUID, entonces aunque no seamos el propietario, si tenemos permiso de ejecución entonces ese archivo se ejecutará como si el usuario propietario lo estuviese ejecutando, pero en realidad lo esta ejecutando un usuario el cual no es el propietario pero tiene permiso de ejecución, entonces sucede esto gracias a este permiso.
Por ejemplo, tenemos el binario python3.9:
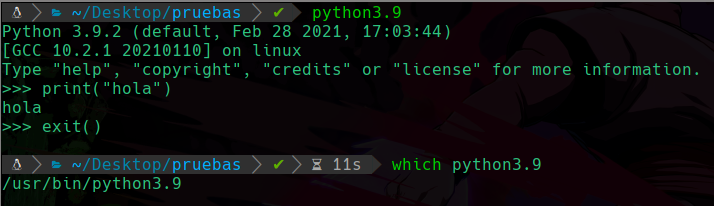
Podemos ver que nos ejecuta el binario normalmente, en este caso vemos que esta todo normal, y vemos con which su ruta absoluta.
Ahora para ver que permisos tiene ese binario de una forma diferente que ir a su ruta y hacer un ls -l, lo que podemos hacer es lo siguiente:

Vemos que estamos usando which para que nos muestre el output de la ruta absoluta de python3.9, pero lo que hacemos aparte es agregar un pipe, para que ese output se almacene para posteriormente ejecutar otro comando con el contexto de ese pipe, en este caso nos hará un ls -l a el archivo que nos dio de salida el comando which y podemos ver que nos devuelve lo que le indicamos.
Podemos ver que tiene los permisos por defecto, el propietario es root, y no tiene ningún permiso especial.
Nosotros nos convertiremos en el usuario root, le asignaremos el permiso suid para hacer la prueba:

Podemos apreciar que se agrego correctamente el permiso especial s, en este caso como lo asignamos al propietario, por eso se le llama suid ya que la s es el permiso y la u es de user.
También podemos asignar este permiso en forma numerica, por ejemplo si los permisos del archivo son 755 entonces al inicio se debe agregar el numero 4 quedando: 4755 de esta forma agregamos el permiso especial dejando el resto como estaba por defecto.
Comando find y riesgo del SUID
Ahora veamos el riesgo de tener un suid en un binario que ejecuta ordenes importantes como python, migraremos a el usuario d4nsh, y una vez lo hayamos hecho vamos a usar el comando find para encontrar todo lo que contenga permisos suid:
find / -type f -perm -4000
Lo que estamos haciendo es encontrar desde la ruta raíz que recordemos que es “/” de donde inician todos los directorios existentes en el sistema, después le diremos con el parametro -type que queremos encontrar archivos “f” de files, y que estos archivos a buscar deben contener el permiso -perm con el valor 4000 que este valor es con el que se identifica el suid.
Y al ejecutarlo veremos lo siguiente:
Vemos muchos errores ya que como no estamos como root no tenemos acceso a ciertas rutas y nos muestra muchos errores, y como no nos interesa ver el stderr, ya sabemos que hacer, vamos a redirigir los errores a /dev/null/:
find / -type f -perm -4000 2>/dev/null
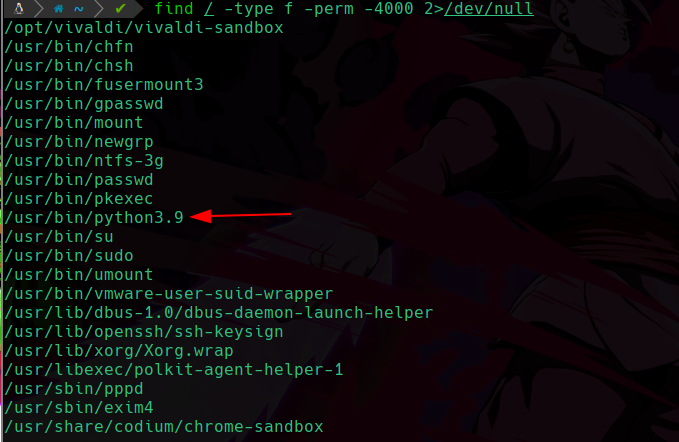
Podemos ver que nos ha encontrado el binario el cuál le asignamos el permiso suid, y como tenemos permiso de ejecución en ese binario, entonces lo podemos ejecutar y lo que hagamos será como si el usuario propietario en este caso root, estuviese haciendo con sus privilegios.
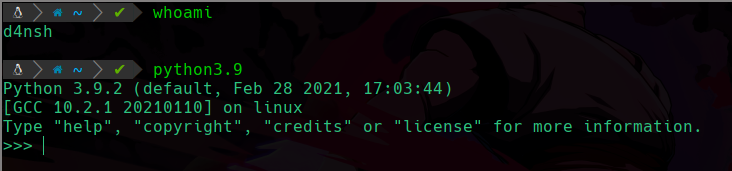
Podemos ver que estamos como d4nsh, y ejecutamos el binario normalmente, ya que tenemos permiso de ejecución, pero como este binario contiene el permiso especial suid, y todo lo que se haga en python, todas las ordenes que demos serán ejecutadas en el contexto de root, por lo que primero haremos lo siguiente:
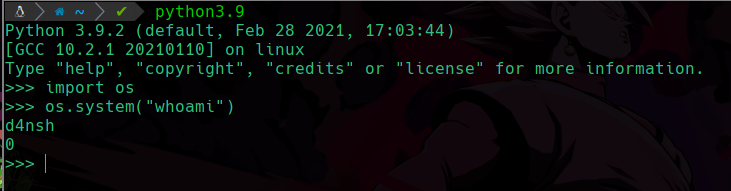
Primero estamos importando la libreria os de python, esta libreria nos permitira tener contacto con el sistema y ejecutar comandos como vemos que hicimos usando os.system("whoami") y vemos que somos el usuario d4nsh.
Pero como esto se esta ejecutando en el contexto del propietario y el propietario es root, entonces podremos modificar nuestro id de usuario y cambiarlo por el de root, y nos dejará hacerlo sin problema gracias a el permiso que nos esta permitiendo ejecutar esto ya que el mismo propietario es el que esta interpretando estas instrucciones, entonces cambiaremos nuestro id de usuario por el de root, el id de usuario root es el 0, por lo que lo asignaremos:
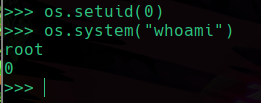
Vemos que hemos cambiado nuestro uid por el valor de 0 el cual pertenece a root, entonces al hacer nuevamente el comando whoami, vemos que nos dice root ya que hemos cambiado temporalmente nuestro uid, así que ya podemos empezar a hacer lo que queramos, por ejemplo sacar una bash para tener control del sistema:
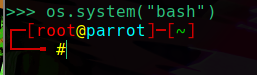
Vemos que hemos spawneado una bash como root, y apartir de aquí ya haremos lo que queramos.
Esto lo mostre para saber los peligros que hay al momento de asignar un suid a un binario que ejecuta cosas importantes como lo es python.
No olvides volver a dejar el binario de python3.9 por defecto para evitar posibles hackeos.

Podemos ver que ya hemos eliminado el permiso correctamente.
Riesgo del SGID
En esto sucede exactamente lo mismo que antes pero la diferencia es que en lugar de que el archivo con el permiso especial se ponga en el usuario propietario, se pone en el grupo de ese archivo.
chmod g+s python3.9
Y lo que sucede es que el usuario que ejecute ese archivo se ejecutará en el contexto del grupo, es decir se va a ejecutar como si el usuario perteneciera a el grupo al cuál pertenece el archivo ejecutable.
Se asigna como lo vimos anteriormente o también con su valor numerico que es 2, se agrega a los permisos que ya tiene por defecto quedando: 2755
chmod 2755 python2.9
De esta forma alternativa a la anterior, se agregará el permiso especial a la parte de grupos, así que como esto es igual a lo anterior solo cambia eso que mencione, no pondré ejemplo ya que no es algo distinto.
Ya que ahora podriamos acceder a cosas que solo el grupo tiene, etc.
Privilegios especiales Capabilities
Las capabilities en linux son atributos especiales en el kernel del sistema, que dan permisos especificos a procesos o programas.
Agregaremos una para mostrar el ejemplo del riesgo que lleva asignar una capabilitie, antes de asignarla, vemos que al ejecutar el binario de python3.9 e intentar cambiar nuestro uid como hicimos anteriormente con el suid, vemos que no podemos:
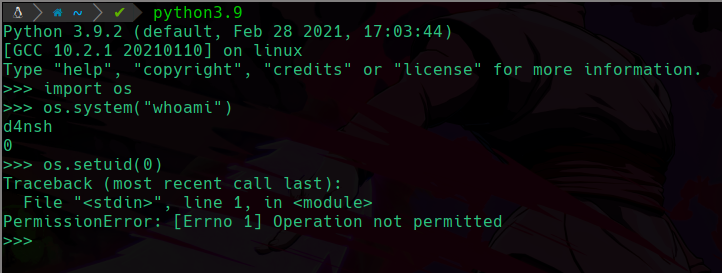
Vemos que nos da error ya que no tenemos permiso de hacer esto, pero en cambio si el binario de python tuviera la capabilitie especial que permite cambiar tu valor de uid, la cual se llama cap_setuid, que nos va a permitir asignar el uid y modificarlo.
Agregaremos esta capabilitie al binario:

Con este comando llamado setcap nos permite agregar capabilities, obviamente para esto debemos estar como root, y lo que hacemos es asignar la capabilitie cap_setuid+ep a el binario de python3.9 como vemos que le damos su ruta absoluta.
Y ahora para hacer una busqueda en el sistema de las cosas que tienen asignadas capabilities podemos usar el comando getcap para buscar:
getcap -r / 2>/dev/null
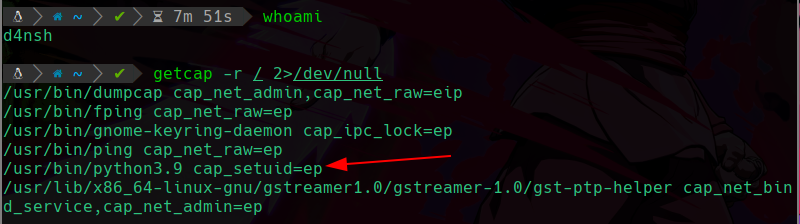
Vemos que estamos buscando de forma recursiva desde la raíz del sistema archivos que tengan capabilities y también redirigiendo los errores al /dev/null ya que ahora somos el usuario d4nsh y no tendremos acceso a todos los directorios.
Y como vemos en la imagen nos encontró el binario al cual le asignamos la capabilitie, y vemos que somos el usuario d4nsh, pero si ejecutamos este binario e intentamos cambiar nuestro uid:
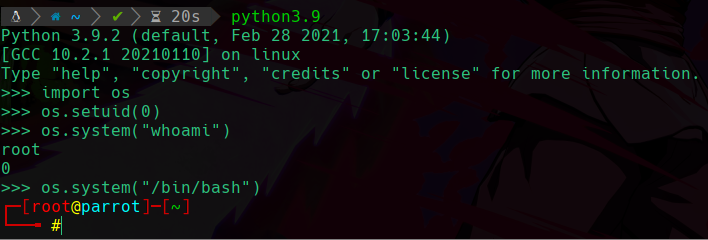
Podemos ver que ahora nos deja cambiarlo gracias a la capabilitie asignada, podemos ver que nos spawneamos una bash como el usuario root, cuando eramos d4nsh y no necesitamos la contraseña de root gracias a esta capabilitie.
Podemos ver que es un riesgo en caso de no asignarlas correctamente.
Y ahora para eliminar la capabilitie y no dejar tu sistema vulnerable por la practica, hacemos lo siguiente como root:
setcap -r /usr/bin/python3.9

De esta forma hemos quitado la capabilitie y ya ningun usuario podrá cambiarse su uid:
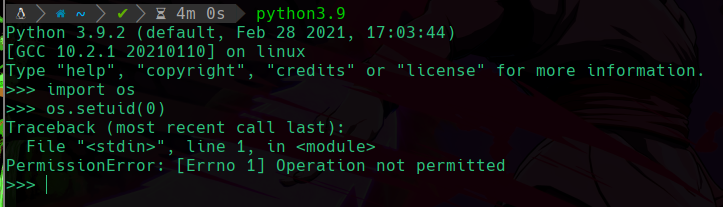
Vemos que da error ya que no cuenta con los permisos para hacer el cambio de uid.
Una página para conocer que riesgos hay en cada binario si tiene capabilities es la siguiente:
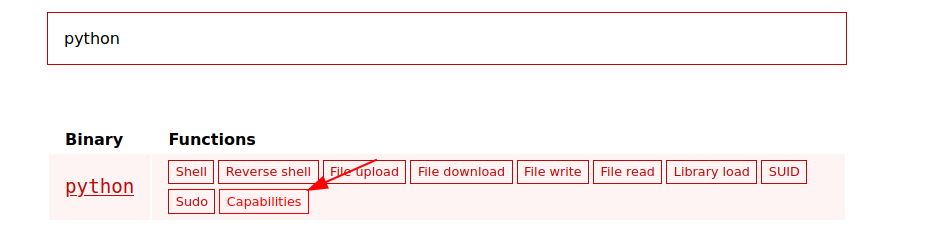
Podemos ver que al buscar el binario de python nos da una opción de que se puede hacer si hay una capabilitie asignada:
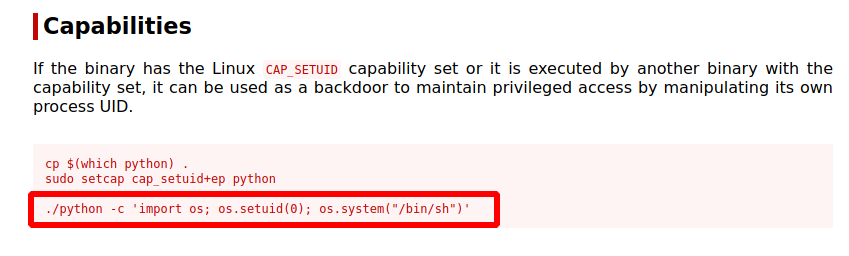
Vemos que nos dice lo que descubrimos anteriormente, que podemos migrar a root en caso de que la capabilitie cap_setuid este asignada en el binario de python.
En la imagen se muestra lo que hicimos pero en una sola linea, ejecuta lo que esta entre comillas simples interpretado con python.
Estructura de directorios en el sistema
Sabemos que el sistema Linux contiene una serie de estructura de directorios que conforman todo el sistema, veamos para que sirven las rutas más importantes, primero iremos a la raíz y veremos los siguientes directorios:
/bin/: Este directorio almacena todos los binarios/ejecutables a los que el usuario puede acceder para utilizar en el sistema.
/sbin/: Esto es similar a el anterior pero solo para el usuario root, solo que aquí los binarios son más para tareas administrativas, como configuraciones del sistema, etc.
/boot/: Dentro de este directorio se encuentran los archivos que son necesarios para que el sistema inicie correctamente, entorno grafico, configuraciones, grub, etc.
/dev/: Este directorio contiene los dispositivos de hardware que esten configurados en el sistema, en forma de archivos, nos sirve para detectar estos dispositivos y configurarlos, un ejemplo puede ser que nos detecte nuestra tarjeta de red, de sonido, etc.
/etc/: En este directorio se almacenan los archivos de configuración, como el /etc/passwd, /etc/group, y similares.
/home/: Sabemos que es donde estan las rutas personales de cada usuario, también pueden contener archivos de configuración de la shell que use el usuario como zsh, etc. Y se almacenan dentro de /home/, en el caso de root, su directorio personal no se almacena aquí sino en:
/root/: Aquí el usuario root tiene su propio directorio en la raíz y este se toma como su directorio personal.
/lib/: En este directorio se almacenan todas las librerias que necesita el sistema para que funcione correctamente.
/lib64/: Similar a el anterior pero para programas que requieren librerias de 64 bits.
/lib32/: Y esto es como lo anterior pero para programas que requieren librerias de 32 bits.
/media/: Aquí se van a montar los disopsitivos de almacenamiento que se conecten temporalmente a el sistema, discos duros, usb, cd, etc, desde aquí accederás a ellos.
/opt/: Aquí se almacenan los programas que no estan por defecto en el sistema, por ejemplo puedes encontrar dentro de /opt/ programas que instalaste que no venian con el sistema, como algún editor de videos, spotify, vivaldi, etc.
/proc/: Es una ruta que almacena logs/registros de los programas que se estan ejecutando actualmente, y nos da información de cada uno.
/srv/: Sirve para almacenar archivos que sean de servidores, http, ftp, etc.
/sys/: Almacena un registro del kernel, información de particiones, etc.
/tmp/: Almacena archivos temporales que se desaparecen en cada reinicio del equipo, se usa comunmente para ahorrar espacio y rendimiento.
/usr/: Contiene la mayor cantidad de programas instalados en el sistema.
/var/: Este directorio contiene un log de todo el sistema por así decirlo ya que contiene muchos logs de una gran cantidad del sistema.
Uso de bashrc y zshrc
Cada tipo de shell ya sea bash o zsh deben tener un archivo de configuración para configurar la shell como deseas.
Por defecto en el directorio personal de tu usuario siempre hay un archivo de configuración ya sea de bash “.bashrc” o de zsh “.zshrc”, estos archivos son ocultos por lo que incian con un punto.
Podemos ver al hacer un ls -a:
Podemos apreciar el archivo de configuración de la shell que uso, en este caso es una zsh, si tienes una bash que es la que viene por defecto y no existe el archivo puedes crearlo con touch .bashrc.
Al entrar al .zshrc con nano vemos lo siguiente:
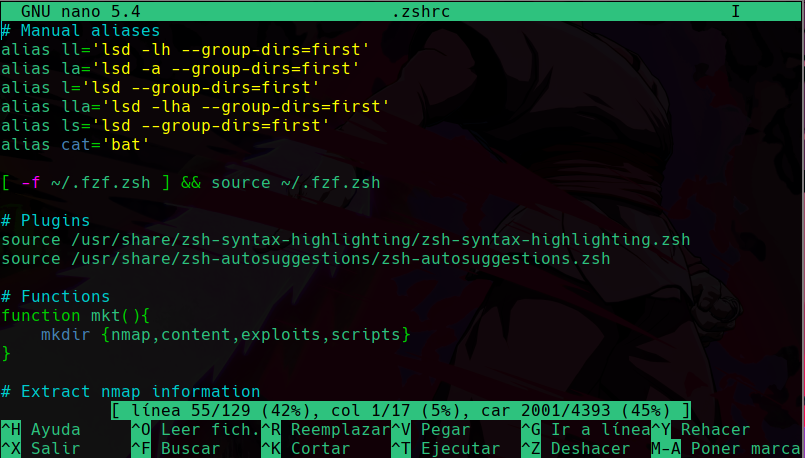
Podemos ver que estan las configuraciones que he hecho, como instlar plugins, agregar nuestras propias funciones, aliases, etc.
Recomiendo el uso de zsh en lugar de bash, ya que zsh te permite instalar plugins muy utiles y bash no, ademas de muchas cosas más.
Agregando una funcion a el zshrc
Agregaremos una función para ver como funciona el zshrc, en este caso haré una función que me diga cual es mi ip local.
Primero construiremos el comando el cual nos va a reportar la ip.
hostname -I Con este comando podremos ver las diferentes ip en el sistema:

La primera ip es la que nos interesa, ya que es la que nuestro equipo tiene en la red local, así que solo queremos ver el primer valor y no el que esta alado.
Entonces para ello usaremos el comando awk, este comando nos permitira filtrar información mediante una output dado, en este caso haremos lo siguiente:
hostname -I | awk '{print$1}'
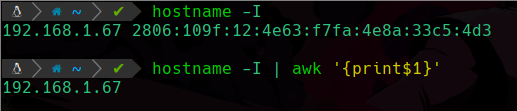
Lo que hacemos en el comando es decirle que con awk, nos imprima el primer valor que esta en el output anterior dado con el comando hostname -I, y le decimos la instrucción en medio de llaves {} y dentro le decimos que nos imprima el primer valor iniciando desde la derecha, por eso usamos el $1, para indicarle que el primer valor, ya que de poner $2 nos pondría el valor que no nos interesa, awk usa los espacios como delimitadores/separadores de los valores para identificar hasta donde debe filtrar la información.
Este fue un uso rapido de awk pero profundizaremos más adelante sobre esto y muchos más comandos.
Ahora que ya tenemos el comando que nos da solo lo que nos interesa, lo agregaremos a una impresion de pantalla con texto:
echo "Tu ip local es: $(hostname -I | awk '{print$1}')"

Lo que estamos haciendo aquí es que ya tenemos lo que hará la función que agregaremos al zshrc, y lo que hace esta función es imprimir el texto que dice “Tu ip local es”, y justo después de eso agregamos la linea de comando que creamos anteriormente para filtrar la ip local, para indicar que es una instrucción en bash/zsh debemos usar el signo de dolar encerrado en () y dentro meter las instrucciones que creamos, y el resultado de la salida de este comando se ve como se muestra en la imagen.
Ya ahora que tenemos todo lo que necesita la función simplemente la vamos a crear dentro del zshrc, abriremos el zshrc:
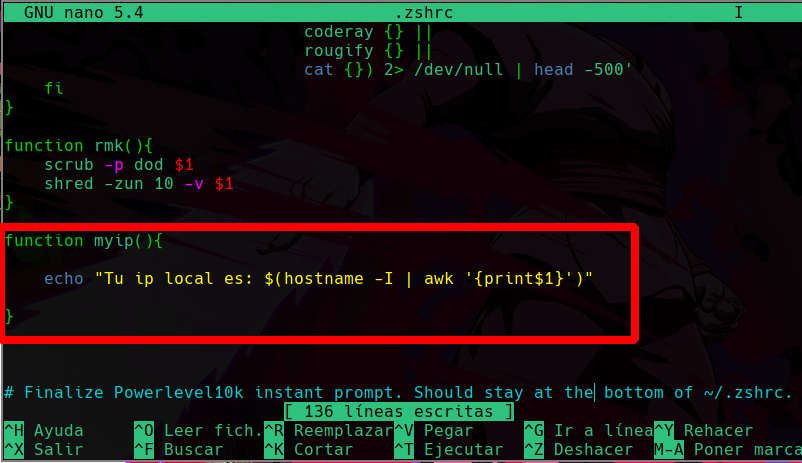
Vemos que creamos una función llamada myip y después definimos su instrucción, que es lo que creamos anteriormente.
Al guardar el archivo, como estamos en nano usaremos ctrl + s, habremos escrito los cambios en el archivo de configuración de la shell zsh.
Y ahora si abrimos una nueva terminal, y ponemos el comando: myip el zsh lo encontrará en su archivo de configuración y ejecutará su función:

Y podemos ver que se ha creado y funciona correctamente la función que hemos agregado a el zshrc.
Esto es un uso muy básico de todo lo que podemos hacer, pero es muy importante saber como funciona esto.
Actualizacion del sistema
Para actualizar los paquetes de tu sistema y buen funcionamiento debemos actualizar el sistema cada cierto tiempo, podemos hacerlo usando el comando:
sudo apt update
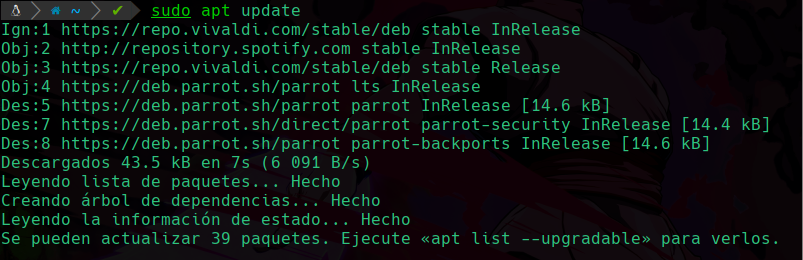
Nos dice que se pueden actualizar 39 paquetes, y para actualizarlos usaremos el comando: sudo parrot-upgrade en caso de tener parrot os, si tienes alguna distro basada en debian como kali puedes usar sudo apt upgrade, en este caso usaré la de parrot:
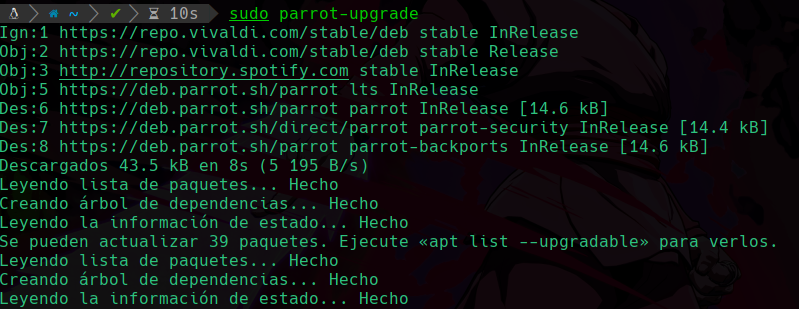
Y vemos que han empezado a instalarse las actualiazciones que obtuvimos anteriormente.
Nunca debes usar el sudo apt upgrade en parrot OS ya que de ser así te dará un error grave y puede que no puedas usar el sistema, en su lugar debes usar como ya dije, el sudo parrot-upgrade.
Se recomienda reinciar el sistema una vez se actualizó todo el sistema.
Uso y manejo de tmux (OhMyTmux)
Ohmytmux es una herramienta que nos va a servir para trabajar de una manera mucho más organizada, y ademas muchas funciones extras para un mejor uso de las terminales.
Para instalar ohmytmux primero debemos tener tmux instalado, que se instala con sudo apt install tmux.
Una vez instalado, vamos a instalar el ohmytmux que se descarga desde su repositorio en github:
git clone https://github.com/gpakosz/.tmux
Después de clonar el repositorio en tu terminal, que clonar un repositorio es descargar el repositorio en tu equipo usando git clone, la url es lo que va a descargar.
Una vez se descargue haremos los siguientes comandos:
Después de ejecutar estos comandos, tanto como el usuario que usas y como root, ahora ejecutamos el comando:
tmux new -s Prueba
Y se nos abrira el tmux con ohmytmux instalado, esto creara una sesión llamada Prueba:
Y en la parte de abajo vemos el nombre de la sesión, las terminales en pestañas abiertas, etc.
Ahora mencionare los atajos basicos que se deben conocer para manejarse por tmux:
Renombrar terminal actual
ctrl + b + ,: Renombrar la pestaña actual en la terminal:

Vemos que hemos renombrado la terminal actual por “Testing”.
Crear nueva terminal en pestaña
ctrl + b + c: Con esto vamos a crear una nueva terminal:

Vemos que se ha creado otra terminal que se llama “zsh”.
Cambiar de terminal en pestaña
ctrl + b + Numero de la posición de la terminal a la que queremos ir: Por ejemplo, queremos ir a la primera que creamos que se llama Testing, entonces hacemos ctrl + b + 1:

Y ya estaremos en la terminal deseada.
Eliminar la terminal actual
ctrl + b + x: Con esto podemos eliminar la terminal actualmente posicionada:

Podemos ver que hemos eliminado la terminal llamada “Testing”.
Dividir el panel actual en más
ctrl + b + %: Dividir el panel verticalmente:
Podemos ver que la dividimos verticalmente y en cada una podemos ejecutar comandos.
ctrl + b + ": Dividir el panel horizontalmente:
De este modo lo dividimos horizontal en lugar de vertical.
Viajar de un panel/terminal a otra
ctrl + b + dirección: Ejemplo, si queremos ir a la terminal de arriba en el ejemplo anterior, usaremos: ctrl + b + flecha de arriba:

Ahora estaremos en el panel/terminal de arriba.
De la misma forma podemos usar las flechas en caso de encontrarse en otro lugar, abajo, izquierda, derecha, etc.
Modo mouse
Este modo nos va a servir para desplazarnos con el scroll o rueda del mouse en caso de querer ver contenido más arriba de la terminal, ya que si queremos ir para arriba de la terminal para leer algun contenido o algo este nos mostrara el historial de comandos anteriores en lugar de ir hacía arriba con la rueda del mouse, para ello se activa este modo para que nos permita ir hacía arriba:
ctrl + b + m: Modo mouse.
De este modo podremos desplazarnos, vuelve a hacer la combinación de teclas cuando hayas terminado de ir a donde querias ir.
Modo copia
Este modo nos pone en modo copia para copiar cualquier texto de la terminal, se activa con:
ctrl + b + [: Modo copia.
Con la rueda del mouse podemos ir a el inicio de lo que queremos copiar y con las flechas ir a exactamente el punto que queremos copiar, en este caso copiare desde mysql hasta sshd:
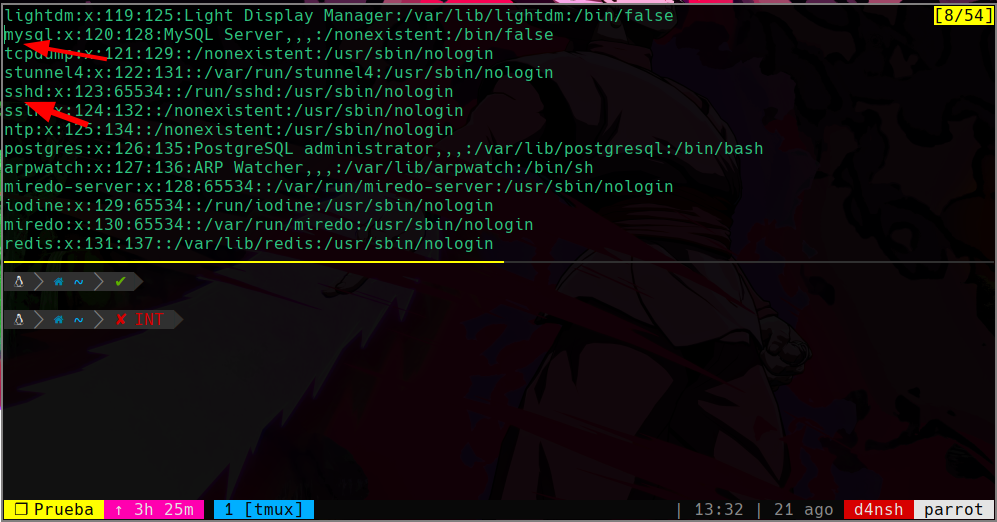
Vemos que donde esta el cursor es desde donde empezaremos a copiar hasta donde señalamos.
Ahora para seleccionar esto, haremos una selección:
Selección
ctrl + espacio: Iniciar modo selección y con las flechas ir seleccionando lo que nos interesa copiar.
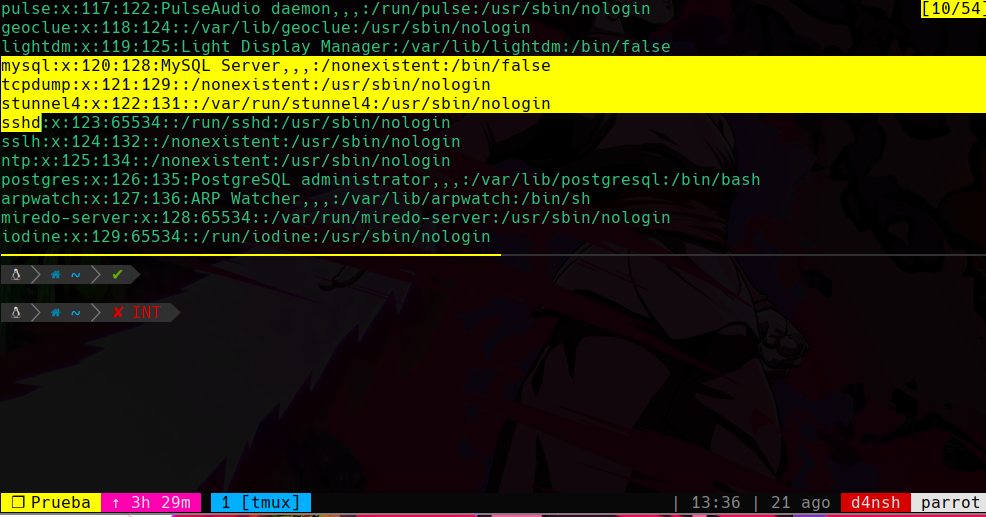
Si presionas la tecla fin, te va a seleccionar toda la linea donde se encuentra el cursor actualmente.
Copiar la selección
alt + w: Copiamos lo que tenemos seleccionado el el modo anterior.
Pegar la selección
Ahora para pegar lo que tenemos copiado usamos:
alt + b + ]: De este modo pegaremos lo que hemos copiado de la terminal.
Esto de copiar y pegar solo funciona si es de copiar algo de tmux y pegarlo en otro tmux, ya que usa un portapapeles del propio tmux.
Cambiar tamaño de las terminales/paneles
Si tenemos varios paneles y queremos cambiar el tamaño de alguno, simplemente entramos a el modo mouse como ya sabemos con ctrl + b + m y justo en la parte de enmedio de las terminales con el mouse podremos redimensionar el tamaño de ellas.

En esa parte en el modo mouse, al darle click y arrastrar podremos ir ajustando el tamaño de nuestras terminales, al terminar desactiva el modo mouse para continuar con tu trabajo.
Otros
ctrl + b + {: Mover el panel actual de posicion a la izquierda.
ctrl + b + }: Mover el panel actual de posicion a la derecha.
Busquedas a nivel de sistema
Es necesario saber hacer busquedas a profundidad en el sistema ya que esto es importante para encontrar archivos vulnerables cuando veamos pentesting.
Buscar elementos por nombre
Si queremos saber donde se ubica un archivo, directorio, ejecutable, etc. Que conocemos su nombre podemos buscarlo desde la raíz del sistema así:
find / -name whoami 2>/dev/null

De este modo estamos buscando desde la raíz del sistema, los elementos que se llamen whoami, y redirigir los errores al /dev/null ya que no tendremos acceso a todas las carpetas del sistema como un usuario de bajos privilegios.
Vemos que solo encontramos el binario del comando whoami, y de este modo podemos conocer su ruta absoluta.
Tratar el output
Como recordamos podemos tratar el outuput que recibimos, como en este caso queremos hacer un ls -l de cada archivo que encuentre nuestra busqueda, usaremos xargs:
find / -name whoami 2>/dev/null | xargs ls -l

Y podemos ver que en base al output de cada resputado le aplica un ls -l, pero en este caso solo nos muestra uno ya que es el único que encontramos en el sistema, pero en caso de ser más igual se aplicaría el ls -l.
Buscar elementos con permiso especial SUID y SGID
Para buscar elementos con el permiso especial SUID usaremos:
find / -perm -4000 2>/dev/null
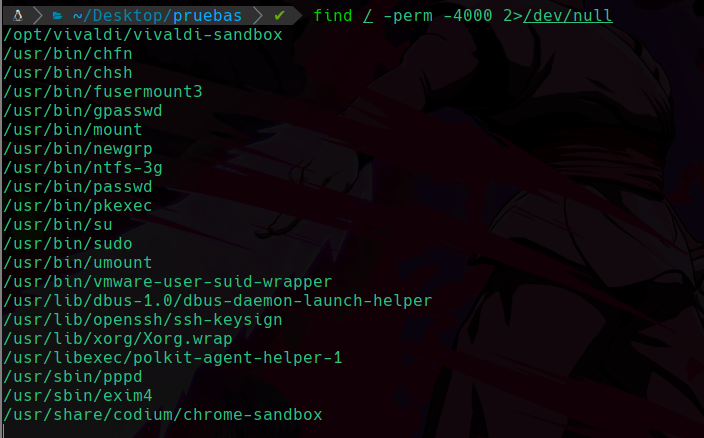
Vemos que buscamos desde la raíz del sistema el permiso con el valor 4000 el que equivale a el SUID, y redirigimos los errores.
Y podemos ver que nos muestra todos los archivos a los cuales tenemos permisos SUID.
Recuerda que el valor del SGID es 2000 en caso de que quieras buscar elementos con ese permiso especial asignado.
Buscar elementos que sean parte de un grupo en especifico
Ahora para buscar elementos que formen parte de un grupo hacemos lo siguiente:
find / -group d4nsh 2>/dev/null
Esto nos va a buscar cualquier cosa que pertenezca al grupo d4nsh, ya sea directorio, archivo, ejecutable, etc.
Pero si queremos solo filtrar por archivos:
Filtrar elementos solo que sean archivos
find / -group d4nsh -type f 2>/dev/null
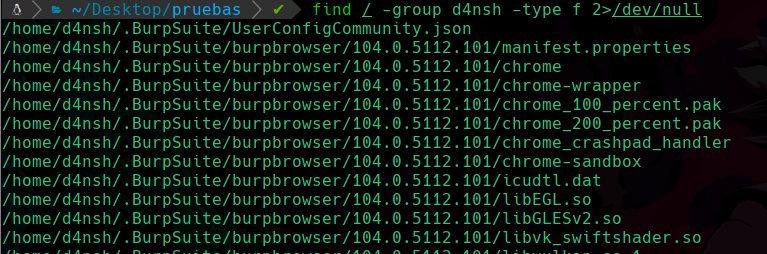
Y esto nos va a mostrar solo los que sean archivos, en cambio si queremos que sean solo directorios se cambia el valor del parametro -type por una d de directorio:
Filtrar elementos solo que sean directorios
Y con este parametro solo veremos los directorios que pertenezcan al grupo d4nsh:
find / -group d4nsh -type d 2>/dev/null
Filtrar elementos que sean de un usuario en especifico
Para filtrar elementos que sean de un usuario en especifico, en este caso queremos ver elementos que pertenecen al usuario root podemos usar:
find / -user root 2>/dev/null
Imaginemos que estamos intentando hackear un equipo al que hemos logrado entrar y ahora debemos escalar privilegios, entonces lo que nos interesaria seria encontrar tal vez archivos que pertenecen a root en los cuales tenemos permisos de escritura:
Filtrar elementos que sean de un usuario en especifico y que tengamos permiso de escritura sobre esos archivos encontrados
find / -user root -writable 2>/dev/null
Y podemos ver que nos muestra todo lo que tenemos permiso de escritura, ya podriamos ir viendo en caso de una prueba de pentesting ver cuál archivo esta mal configurado o nos permite escalar privilegios etc.
Pero por ahora solo se muestra el uso del comando find.
Recuerda que podemos mezclar parametros, por ejemplo si queremos esto mismo pero que solo queremos ver archivos entonces agregariamos el parametro -type -f a el comando quedando: find / -user root -writable -type f 2>/dev/null o como nosotros queramos realizar las busquedas.
Más permisos en la busqueda y ejecutables
No solo podemos buscar archivos con escritura con el parametro -writable, obviamente también estan:
-readable — Para archivos a los que tenemos permiso de lectura. -executable — Archivos ejecutables a los que tenemos acceso.
Por ejemplo si queremos ver ejecutables del propietario root, los cuales tenemos permiso de lectura, escritura y ejecución entonces usamos:
find / -user root -executable -writable -readable 2>/dev/null
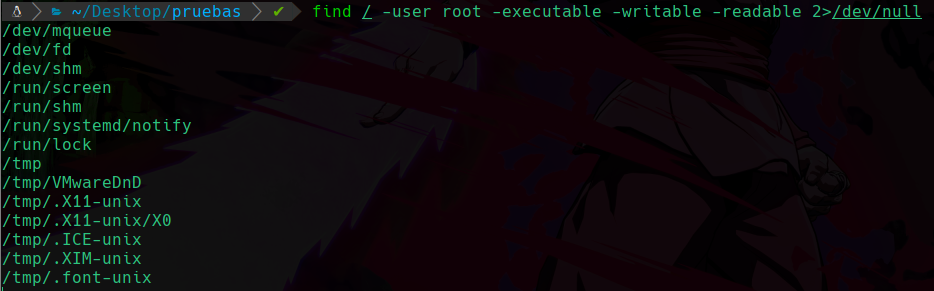
Y vemos que nos muestra los resultados, recuerda que algunos directorios tienen permisos de ejecución que significa que los podemos atravesar o estar en ellos, por lo que nos muestra tanto archivos como directorios con permisos de ejecución.
Busqueda con expresiones regulares (regex)
Ahora mostraremos un uso básico de busqueda usando expresiones regulares, ya que más adelante profundizaremos en esto más cuando toquemos bash scripting.
Las expresiones regulares son una serie de caracterés que nos van a permitir darle instrucciones a un comando, para que este nos vaya filtrando lo que queremos exactamente.
Buscar por primeras letras
Por ejemplo, supongamos que queremos encontrar algun archivo o algo que no recordamos su nombre completo, supongamos que del binario “whoami” solo recordamos que iniciaba con “whoa” y no recordamos lo demas por ejemplo.
Aquí es donde entran las expresiones regulares para esto:
find / -name whoa\* 2>/dev/null
El * indica que continue con lo que sea, le estamos diciendo que inicie buscando algo que inicie con la palabra whoa y que el resto es lo que sea, entonces nos mostrará todo lo que inicie con whoa:

La barra invertida la ponemos para evitar que se tome como parte del nombre que buscamos, y que funcione como expresión.
Y podemos ver que nos ha encontrado en todo el sistema archivos que contienen esa palabra y también nos muestra su ruta donde se ubican.
Buscar por palabra no especifica sin inicio
Ahora si no conocemos como inicia algo ni como termina, pero recordamos alguna palabra clave, supongamos que queremos encontrar “d4nsh” pero solo recordamos “4n”, entonces usaremos la siguiente expresión regular en la busqueda:
find / -name \*4n\* 2>/dev/null
De esta forma buscara cualquier elemento que incluya esa palabra indicada, ya que no conocemos como inicia ni como termina usamos estas expresiones al inicio y al final:
Vemos que nos filtra la mayoria de cosas de d4nsh y entre otras cosas, y de este modo podemos archivos,directorios, ejecutables, cosas que busquemos.
Recuerda que puedes combinar parametros, como agregar el parametro -type f para filtrar solo archivos, o más parametros como los de permisos, etc.
Como en este ejemplo:
find / -name \*4n\* -type f -writable 2>/dev/null

Que estamos buscando algo que inicie con algo y que contenga “4n” y también que termine con algo, que nos muestre solo archivos con permisos de escritura redirigiendo los errores.
Primer encuentro con Bash scripting
En esta parte crearemos un script en bash ya que con lo que ya sabemos podremos hacer ciertas cosas basicas con bash scripting, y algunas otras cosas más que explicaré ahora.
El script que haré lo explicaré pero si puedes intenta algo distinto siguiendo la misma lógica para que intentes algo nuevo.
En este caso primero crearemos un archivo de tipo bash, su extensión es .sh, por lo que lo crearemos con ese nombre:
touch scipt.sh
Y también le agregamos permisos de ejecución, cuando no se asigna especificamente a que conjunto se agregará ese permiso entonces por defecto los agrega en todos:
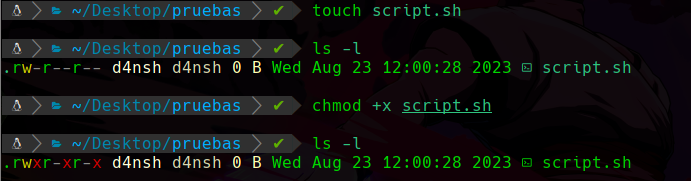
Como vemos en la imagen ya tiene permisos de ejecución.
¿Y para qué necesitamos que tenga permiso de ejecución?
Necesitamos que nuestro script contenga este permiso para que podamos ejecutar las instrucciónes, recuerda que este permiso en los directorios indica que podemos atraversarlos, pero en caso de archivos/binarios, es para que nos permita ejecutar sus instrucciones.
Para iniciar con un script en bash siempre es necesario agregar la cabezera:
#!/bin/bash
Esto es para que el sistema detecte que esto será ejecutado con bash.
Y seguido de esto ya podemos ir programando el script, como por ejemplo, una impresión de pantalla:
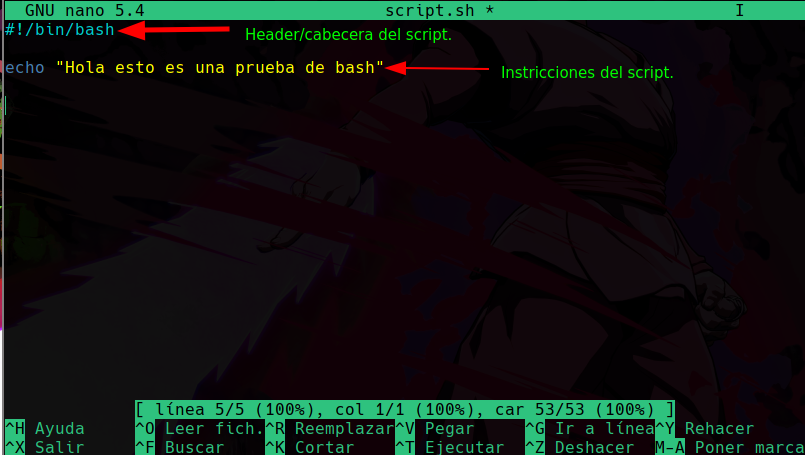
Estamos usando el editor nano pero puedes usar el que quieras.
Y ahora al guardar este archivo, en este caso estamos con nano así que será con ctrl + s, ahora vamos a ejecutar nuestro script:
Ejecutaremos el script con ./script.sh, el punto y barra es porque estamos ejecutando este archivo en el directorio actual, el cual se representa con un punto y la barra es para seleccionar el script que ejecutaremos.
Y podemos ver que hemos ejecutado las instrucciones de bash en nuestro script simple.
Ahora modificaremos este script para hacer algo un poco más útil como el que hicimos para saber nuestra ip que agregamos a el zshrc.
Pero en este caso será en el script.
En este caso haré un script de cuanto tiempo ha durado la PC encendida, para saber esto existe un comando llamado uptime:

Pero solo nos interesa el valor que señale con un recuadro rojo en la imagen, el cual indica las horas y minutos que lleva encendida la PC, así que haremos uso de comandos para ir filtrando lo que solo nos interesa.
uptime | awk '{print$3}'

Vemos que con awk hemos filtrado por el campo 3, ya que como recordamos, awk detecta los espacios como separador de valores, así que seleccionamos el valor 3 que es el que nos interesa, y lo imprimimos con el signo de dolar para apuntar a la posición 3.
Una vez tenemos esto ahora vemos que hay una comilla, podemos removerla con el comando tr:

Con el comando tr ',' ' ' estamos cambiando el caracter de comilla por un espacio.
Y nos mostrará como se ve en la imagen el output, vemos que desaparecio la comilla, pero como quedo un espacio en lugar de la comilla, vamos a volver a usar el comando awk para esta vez quedarnos con el primer campo tomando como separador el espacio:

El output se ve igual que el anterior, pero ahora ya no hay un espacio demas innceserario.
uptime | awk '{print$3}' | tr ',' ' ' | awk '{print$1}'
Ahora que ya tenemos el oneliner que creamos, osea el comando en una sola linea que queremos que nos muestre lo que queremos, ahora lo agregaremos a el script dentro de un mensaje:

Podemos ver que agregamos el comando que creamos anteriormente en el script, dentro de un mensaje, el cual nos dice que hemos durado cierto tiempo en la PC, recuerda que se usa $(aqui van comandos…..) para que se ejecute un comando de bash y no se tome como texto.
Y al ejecutar este script veremos lo siguiente:

Vemos que nuestro script se ha ejecutado correctamente, ahora si queremos darle colores para que se vea mejor podemos hacer lo siguiente:
Agregar colores y saltos de linea al script
Primero copiaremos estas variables en el script:
#Colours
greenColour="\e[0;32m\033[1m"
endColour="\033[0m\e[0m"
redColour="\e[0;31m\033[1m"
blueColour="\e[0;34m\033[1m"
yellowColour="\e[0;33m\033[1m"
purpleColour="\e[0;35m\033[1m"
turquoiseColour="\e[0;36m\033[1m"
grayColour="\e[0;37m\033[1m"
Estas variables son colores a nivel de sistema pero para simplificar su uso se crean variables que podamos identificar para hacerlo más rapido.
Una vez los tengamos en el script se verá algo así:
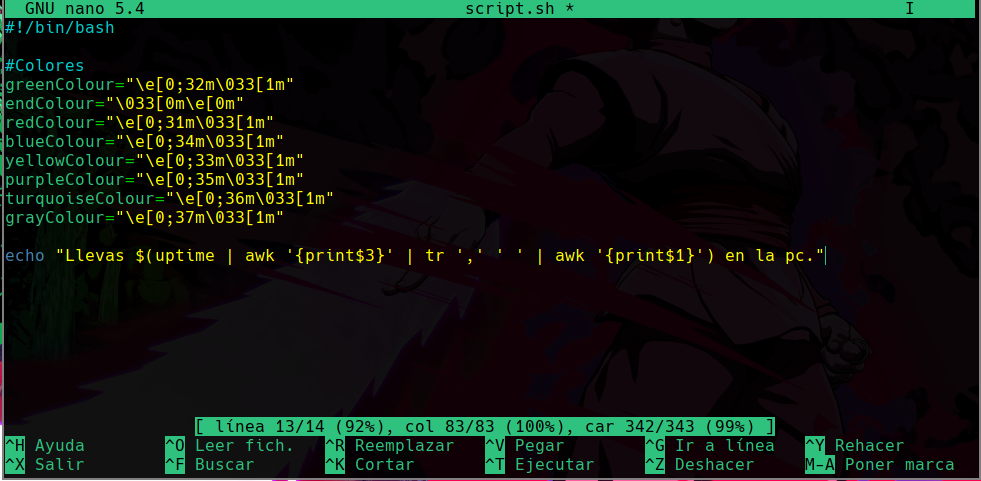
Y para usar estos colores en nuestro script, se usan llamando a el contenido de la variable, por ejemplo si queremos llamar al color rojo usamos ${redColour} y pintaremos de color rojo desde donde pusimos el color y hasta donde lo finalizamos que para finalizar un color se usa ${endColour}, así que yo he asignado estos colores:

Vemos que hemos asignado el color rojo solo a el output que mostrará el comando ejecutado, y agregamos el paramtero -e a el echo para que nos interprete los colores, pero también puede interpretar saltos de linea entre más cosas que nos serán útil, así que se verá algo así al ejecutarse:

Vemos que se ha coloreado correctamente y se ve mejor de esta forma.
Uso y configuracion de la kitty
Si no te sentiste comodo usando tmux, tal vez kitty te resulte mejor, y yo recomiendo usar kitty ya que tiene más ventajas, pero si te quieres quedar en tmux no hay problema.
Para instalar la kitty desde sistemas basados en debian como kali,parrot,ubuntu etc, podemos instalarla usando:
sudo apt install kitty
Y si usas arch:
sudo pacman -S kitty
Ya que debian usa el gestor de paquetes apt y arch usa pacman.
Una vez tengamos la kitty y la ejecutemos desde el menú de programas, veremos la kitty algo así:
Vemos que se ve muy básica a simple vista pero esto no es así, ya que vamos a configurarla a nuestro gusto.
Vamos a ir a la ruta ~/.config/kitty
Si no existe esa ruta la creamos.
Kitty tomará esta ruta como los archivos de configuración que debe leer, primero vamos a crear un archivo llamado kitty.conf:
Y dentro de este archivo de configuración meteremos las siguientes configuraciones:
kitty.conf
enable_audio_bell no
include color.ini
font_family HackNerdFont
font_size 12
disable_ligatures never
url_color #61afef
url_style curly
map ctrl+left neighboring_window left
map ctrl+right neighboring_window right
map ctrl+up neighboring_window up
map ctrl+down neighboring_window down
map f1 copy_to_buffer a
map f2 paste_from_buffer a
map f3 copy_to_buffer b
map f4 paste_from_buffer b
cursor_shape beam
cursor_beam_thickness 1.8
mouse_hide_wait 3.0
detect_urls no
repaint_delay 10
input_delay 3
sync_to_monitor yes
map ctrl+shift+z toggle_layout stack
tab_bar_style powerline
inactive_tab_background #e06c75
active_tab_background #98c379
inactive_tab_foreground #000000
tab_bar_margin_color black
map ctrl+shift+enter new_window_with_cwd
map ctrl+shift+t new_tab_with_cwd
background_opacity 0.95
shell zsh
Estas configuraciones son las que quiero en mi kitty, pero tu puedes modificar las que gustes o agregar más, puedes ver todas las configuraciones en su página web: Kitty Web.
Algunas de las configuraciones que asignamos son:
- zsh por defecto.
- Opacidad al 0.95.
- Definir atajos para crear nuevas ventanas de terminal.
- Desactivar las URL que si estan en la terminal te llevan al navegador.
- Colores.
- Forma del cursor.
- Definimos las teclas f1,f2 para que f1 sea copiar y f2 pegar, esto es dentro del portapapeles interno de la kitty.
- Igual definimos otras teclas iguales para esto pero son f3 y f4.
- Configuramos la fuente como “HackNerdFont”. (Que debes instalarla en caso de no tenerla).
Estas son unas configuraciones importantes que asignamos a la kitty con el contenido del archivo, cuando metamos las configuraciones a el archivo ~/.config/kitty.conf:
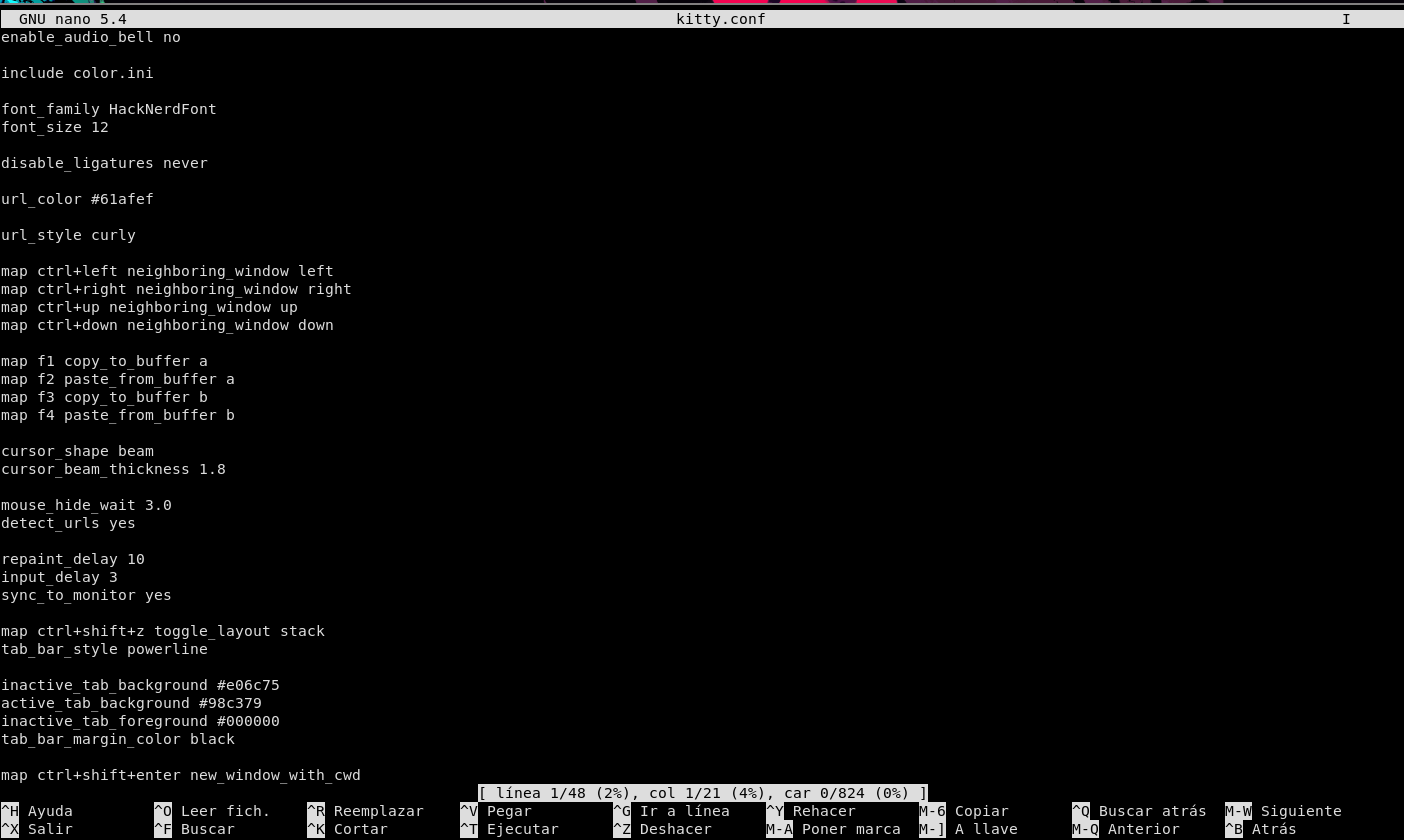
Una vez peguemos las configuraciones en el archivo guardaremos, y ahora vamos a crear otro archivo llamado color.ini:
Y dentro de este archivo meteremos lo siguiente:
cursor_shape Underline
cursor_underline_thickness 1
window_padding_width 20
# Special
foreground #a9b1d6
background #1a1b26
# Black
color0 #414868
color8 #414868
# Red
color1 #f7768e
color9 #f7768e
# Green
color2 #73daca
color10 #73daca
# Yellow
color3 #e0af68
color11 #e0af68
# Blue
color4 #7aa2f7
color12 #7aa2f7
# Magenta
color5 #bb9af7
color13 #bb9af7
# Cyan
color6 #7dcfff
color14 #7dcfff
# White
color7 #c0caf5
color15 #c0caf5
# Cursor
cursor #c0caf5
cursor_text_color #1a1b26
# Selection highlight
selection_foreground #7aa2f7
selection_background #28344a
Que son parte de config.ini, ya que si vemos en las configuraciones de config.ini importamos un archivo llamado color.ini el cuál es este.
Una vez guardemos este archivo y ahora abramos una nueva terminal de kitty, se verá algo así:
Podemos ver que se ve mucho mejor que como estaba anteriormente, y ahora que ya tenemos este emulador de terminal que a mi parecer es mejor que tmux.
Ya que también contiene crear nuevas pestañas de terminales, sesiones, y mucho más.
Atajos de la kitty
Ahora que hemos configurado nuestra kitty, mostraremos como se usan las configuraciones que definimos para crear y modificar terminales entre otras cosas.
Renombrar ventana actual de trabajo
ctrl + shift + alt + t Con esto vamos a poder renombrar la ventana actual:
Al hacer esa combinación de teclas nos mostrara este mensaje diciendo que por que nombre queremos renombrar la ventana actual, una vez le digamos el nombre en este caso le puse “Prueba”, damos enter para que se guarden los cambios.

Y de primero no veremos nada, ya que no hay otra ventana, así que para ver esto agregaremos otra ventana con:
Agregar una nueva ventana de trabajo
ctrl + shift + t Con esto agregaremos una nueva ventana de trabajo:

Y podemos ver que hemos podido agregar una nueva ventana, y ya aparece la que habiamos creado anteriormente.
Podemos ir cambiando de ventana de trabajo dando click en el nombre de la que queremos ir, o si queremos por atajos:
Cambiar de ventana con atajo de teclado
ctrl + shift + izq o derecha Con esto podremos cambiar de ventana de trabajo rapidamente desde el teclado.
Abrir nueva terminal en la ventana actual
ctrl + shift + enter Con esto vamos a crear una nueva terminal en la ventana actual:

Y podemos ver que hemos creado una nueva terminal dentro de la ventana actual.
Cambiar de posición la terminal actual
ctrl + shift + l Con esto vamos a cambiar de lugar la terminal:

Y podemos ver que se ha cambiado de posición.
Cambiar de terminal a otra
ctrl + izq o derecha Con esto vamos a cambiar de terminal actual a otra.
O también haciendo click en la terminal que queremos usar podemos hacerlo.
Cerrar terminal actual
ctrl + shift + w Con esto cerraremos la terminal actual en uso.
Cambiar lugar de terminal actual
ctrl + shift + f Con esto podemos cambiar de lugar una terminal, por ejemplo tenemos esta:
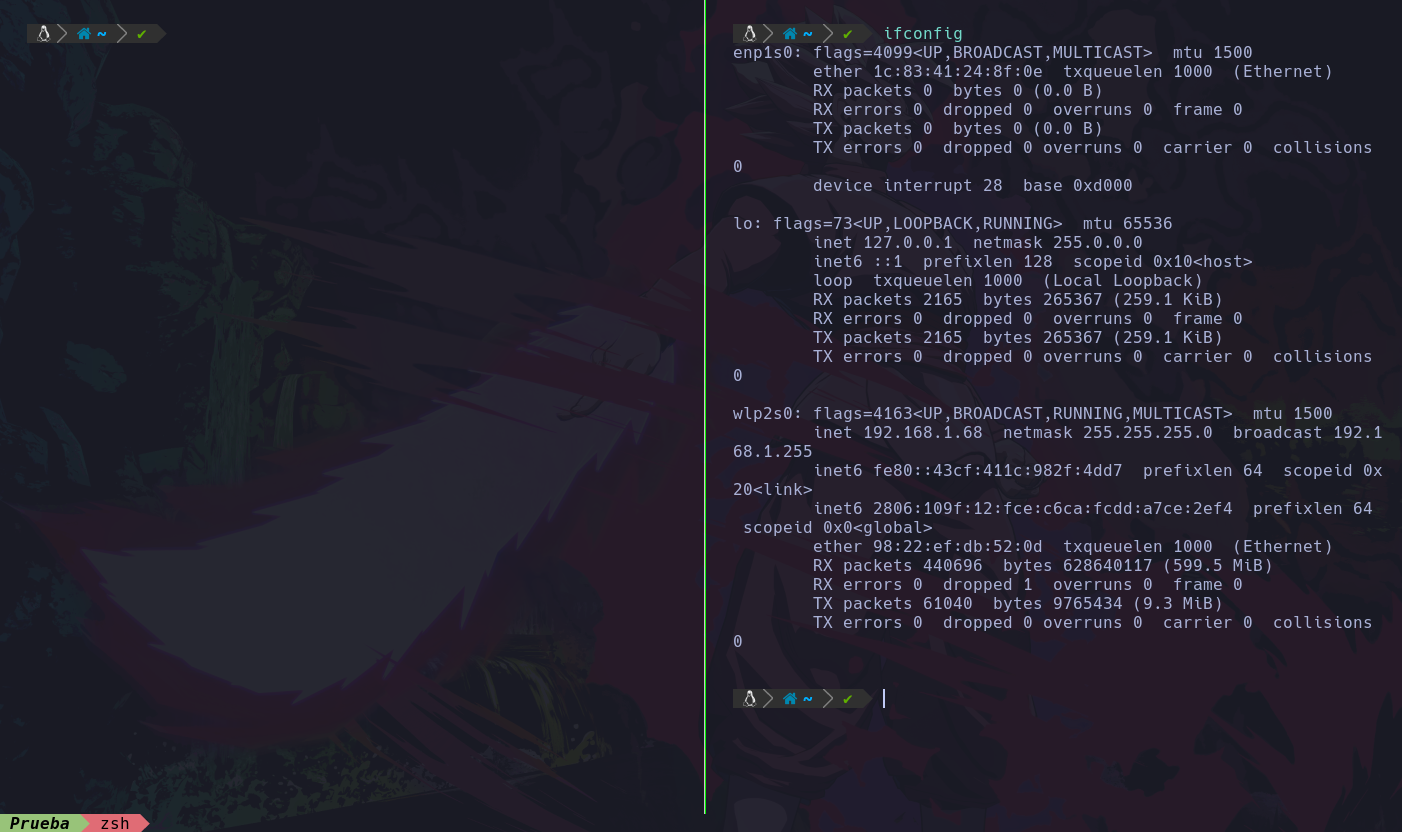
Y al hacer la combinación veremos esto:
Vemos que hemos cambiado de lugar la terminal con la otra.
Redimensionar tamaño de la terminal actual
ctrl + shift + r Con esto entraremos a el modo de redimensionar de la terminal actual y nos saldra este aviso:
Y nos dice que con la w,n,t,s podemos cambiar el tamaño en proporciones de la terminal, y con r la restablecemos a su tamaño original, en este caso por ejemplo la redimensioné así:
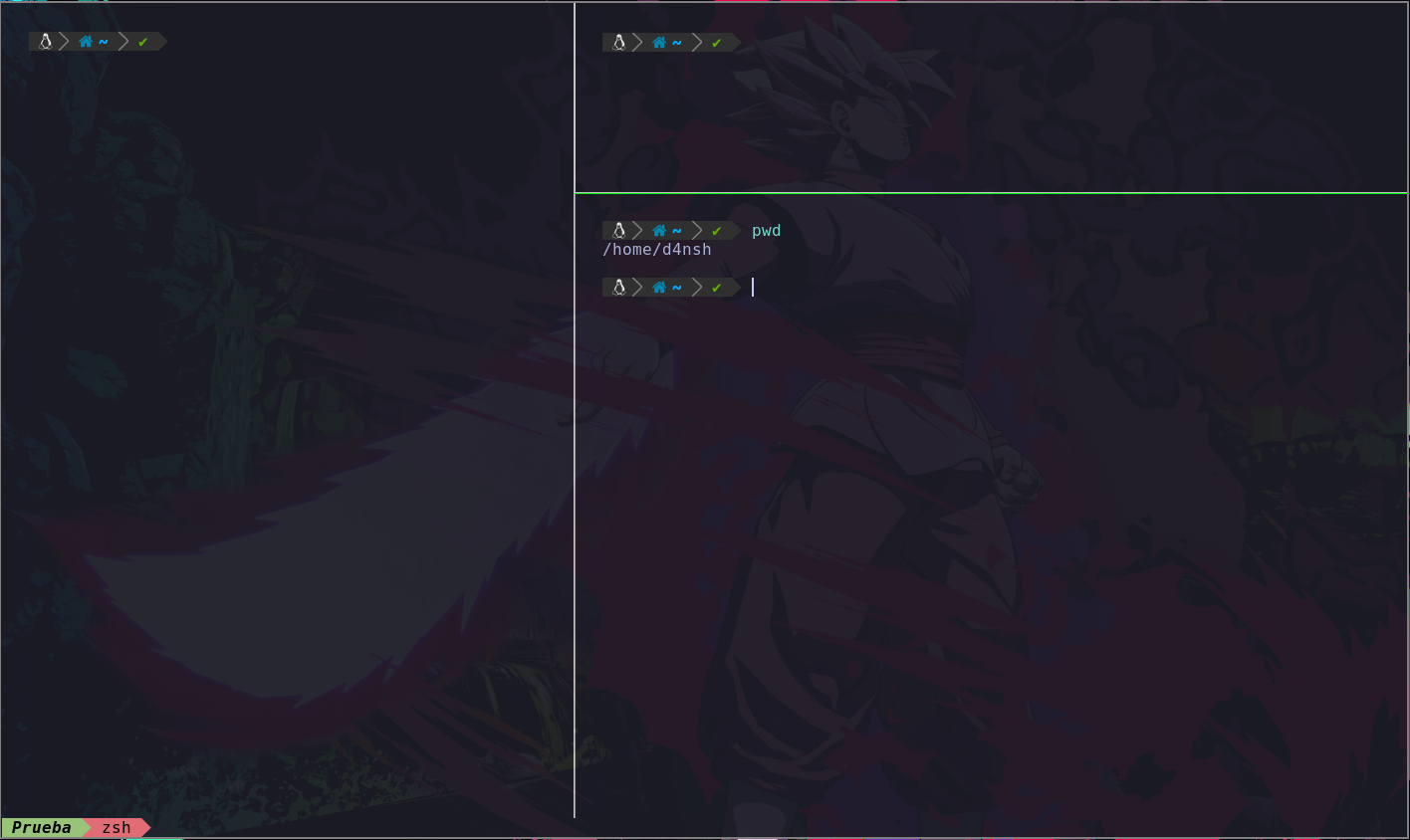
Vemos que la he redimensionado de esta forma, con esc guardamos los cambios.
Mover ventana de trabajo actual a otra posición
ctrl + shift + , Con esto vamos a cambiar la ventana de trabajo actual a la izquierda o si queremos a la derecha es con el punto en lugar de la coma.
Selección de texto eficaz
Si queremos seleccionar un texto pero hay un elemento que no queremos copiar, por ejemplo aqui:
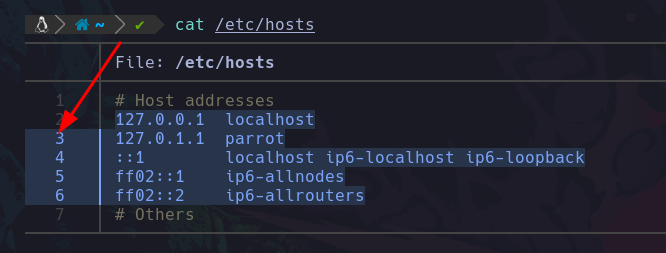
Podemos ver que queremos copiar solo el contenido pero en la izquierda vemos que se esta copiando también los elementos que cuentan las lineas y eso no lo queremos.
Entonces para solucionar esto podemos usar:
ctrl + alt + seleccion de texto Con esto se va a mantener el cursor y lo que seleccionemos en la misma linea:
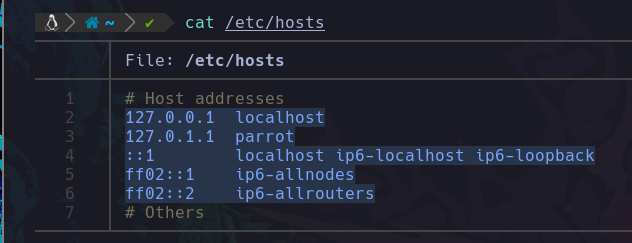
Y podemos ver que ya podemos seleccionar esto y copiarlo, ya sea en la clipboard/portapapeles del sistema como ya sabemos con ctrl + shift + c ya que estamos en terminal, esto para copiarlo a nivel global y pegarlo no solo de terminal a terminal.
Pero si queremos copiar algo y pegarlo de terminal a terminal podemos usar las teclas que asignamos como copiar y pegar de la kitty:
Copiar y pegar usando el portapapeles/clipboard de kitty
Ahora si queremos copiar algo dentro de la kitty y lo vamos a pegar dentro de una misma terminal de kitty entonces podemos usar f1 que asignamos esta tecla en las configuraciones anteriormente. Esto nos permitira copiar algo, y con f2 lo pegaremos.
La misma funcion tienen las teclas f3 y f4 para copiar y pegar 2 contenidos a la vez.
Instalación de nvim(nvchad).
Por defecto en algunos sistemas ya viene instalado nvim, pero vamos a eliminarlo ya que queremos la versión más reciente y no esta.
Lo borraremos con: sudo apt remove neovim:
Vemos que ya lo hemos eliminado, ahora vamos a la web de instalación de nvchad:
Vemos que nos pide los siguientes requisitos, primero tener la última versión de nvim o neovim, por lo que al darle al enlace nos llevará a su ultima versión, y una vez estemos dentro del repositorio de nvim,vamos hasta la parte de abajo y descargaremos esto:
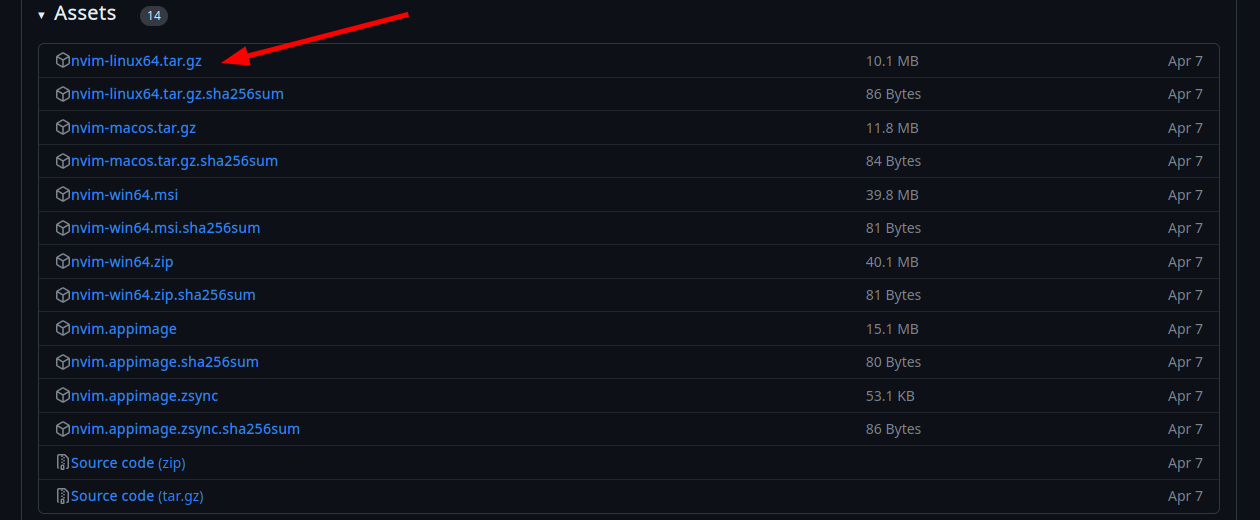
Una vez lo tengamos en descargas, vamos a la ruta /opt/ y desde aquí moveremos el archivo comprimido:
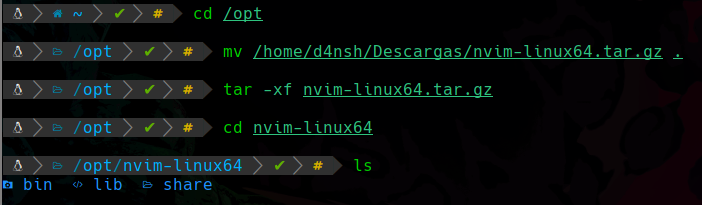
Vemos que primero nos convertimos en root, después vamos a la ruta /opt, después movemos el archivo que descargamos hacía el directorio actual, por eso ponemos un punto.
Y usando tar vamos a descomprimir el archivo comprimido.
Una vez se descomprima entarmos a la ruta que nos deja el archivo descomprimido, y encontraremos 3 carpetas, iremos a la de bin y encontraremos el binario de nvim más reciente:
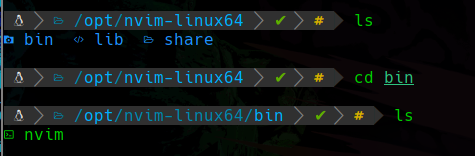
Ahora lo que haremos es asegurarnos de que el directorio ~/.config/nvim del usuario que usara nvim en este caso d4nsh, no exista, en este caso migraremos a d4nsh ya que solo ocupmaos root para mover cosas a /opt y vemos que esta ruta no existe:

Vemos que no existe la ruta de configuración de nvim del usuario que usara nvim.
Una vez aseguremos que ese directorio no exista, clonaremos el repositorio de nvchad:
git clone https://github.com/NvChad/NvChad ~/.config/nvim --depth 1
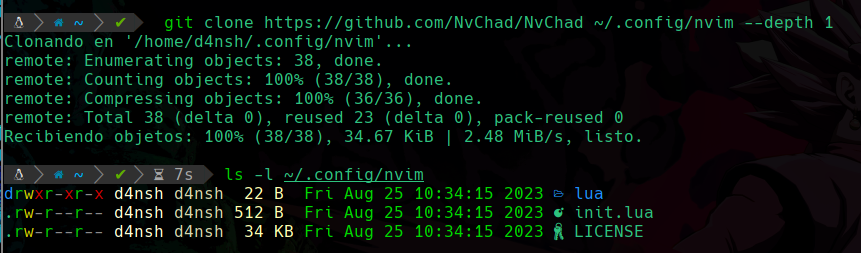
Podemos ver que al clonar este repositorio, se clono dentro de la ruta nueva ~/.config/nvim y esta nueva ruta tiene el contenido que necesitamos, esta vez si ocupamos esta configuración nueva.
Ahora iremos a la ruta del nvim:
Y vamos a ejecutar este binario.
Como al ejecutarlo detectará que en su ruta de configuración hay configuraciones entonces las aplicará y nos mostrará un mensaje de que si queremos instalar la configuración, daremos que yes y enter, y empezará a configurarse todo, y al terminal nos pedirá salir , que lo hacemos con esc + : + teclear "q!" y enter.
De este modo salimos de nvim.
Ya estará configurado y ahora simplemente agregaremos esta ruta a la variable de entorno $PATH para que al momento de ejecutar el comando nvim nos detecte este nuevo nvim.
Por lo que vamos a el .zshrc del usuario que tiene nvim:

Y ubicaremos la variable PATH, y vamos a agregar la ruta donde se encuentra el nuevo nvim:

Vemos que la hemos agregado, y obviamente respetaremos la separación usando los dos puntos como se ve que lo hicimos.
Y ahora al abrir una nueva terminal y ejecutar nvim, nos abrira nvchad:
En este caso abrimos un script de bash con nvim y podemos ver que se ve muy bien sus colores y detecta la sintaxis.
Uso de Nvim(Nvchad)
Ahora que lo hemos instalado, vamos a a aprender a usarlo:
En vim al entrar nos pondrá en el modo de texto normal:
En este modo es donde podemos hacer atajos para ciertas cosas que veremos más adelante que se hacen en este modo, y si queremos poder ingresar datos en el archivo, presionaremos la tecla i de este modo entraremos a el modo de insert y ya podremos meter contenido al archivo:
Podemos ver que al presionar la tecla “i” entramos a el modo insert y pudimos agregar contenido, si queremos guardar el archivo sin salir de nvim debemos volver a el modo normal, que se hace con: esc.
Una vez en el modo normal, lo que haremos será presionar:
Todos estos atajos se hacen en el modo NORMAL
: + w: Guardar cambios sin salir.
Pero si queremos guardar y salir hacemos:
: + wq: Guardar archivo y salir.
Salir
: + q: Salir cuando ya no hay cambios por guardar.
: + q!: Salir descartando los cambios sin guardar.
Otros importantes atajos
Seleccionar texto + y: Con esto vamos a copiar el texto seleccionado.
Seleccionar texto + d: Eliminar texto seleccionado.
alt + u: Deshacer cambios recientes.
Si quieres saber todos los atajos que hay puedes visitar la cheat sheet de nvim: Cheat Sheet Nvim.
Autocompletado de nvim
Si estamos escribiendo un código y queremos ejecutar algo que el nvim detecta nos dará opción de autocompleatarlo:
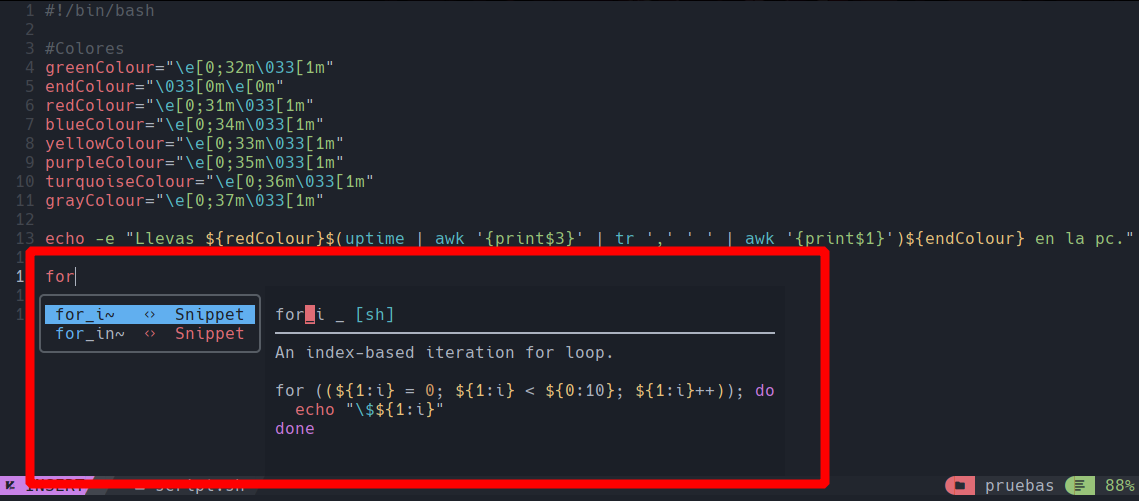
Vemos que nos da una sugerencia de la posible opción que vayamos a ocupar, pero puede ser molesto, y podemos desactivar esto eliminando la linea en la configuración de ese plugin, iremos a la ruta: ~/.config/nvim/lua/plugins
Y encontraremos los siguientes archivos:

Abriremos el init.lua:
Y vamos a eliminar desde donde dice “ – load luasnips + cmp related in insert mode only” hasta que termine ese apartado osea hasta acá:
Y una vez eliminemos eso quedará esto sin esa parte:
Esto quedará así ya sin ese apartado que eso era lo que nos sugeria el autocompletado, y ahora al guardar esto y volver a abrir nvim ya no te sugerira esas cosas.
Reparar cursor al cerrar nvim
Si al cerrar nvim nuestro cursor se cambia a el de bloque, debemos agregar esta función a el zshrc o bashrc depende lo que uses:
# Change cursor shape for different vi modes.
function zle-keymap-select {
if [[ $KEYMAP == vicmd ]] || [[ $1 = 'block' ]]; then
echo -ne '\e[1 q'
elif [[ $KEYMAP == main ]] || [[ $KEYMAP == viins ]] || [[ $KEYMAP = '' ]] || [[ $1 = 'beam' ]]; then
echo -ne '\e[5 q'
fi
}
zle -N zle-keymap-select
# Start with beam shape cursor on zsh startup and after every command.
zle-line-init() { zle-keymap-select 'beam'}
La vamos a pegar en el .zshrc o .bashrc, y al guardarlo ya no deberiamos tener ese problema.
Conexion por SSH a laboratorios de practica
Ahora que ya sabemos las bases aprenderemos más pero ahora haciendo laboratorios de prueba en forma de retos, para ello iremos a la web que nos proporciona estos niveles: OverTheWire-Bandit0.
Una vez dentro vamos a elegir “Level 0” veremos lo siguiente:
Aquí estamos en el nivel 0 donde nos dan instrucciones para conectarnos por ssh.
¿Qué es ssh?
La conexión SSH nos sirve para conectarnos a servidores por medio de una terminal, en este caso los creadores de los retos tienen un servidor ssh llamado bandit.labs.overthewire.org por el cuál nos vamos a conectar para empezar a hacer los retos.
Este servidor se ejecuta en el puerto 2220, por lo que para iniciar la conexión con el nivel 0, haremos lo siguiente:
ssh bandit0@bandit.labs.overthewire.org -p 2220
Con este comando vamos a conectarnos por ssh, nos conectaremos como el usuario bandit0, ya que así nos dicen las instrucciones del nivel 0, y el arroba indica que entrara ese usuario a el servidor que esta después del arroba.
Y le decimos que se conecte por el puerto 2220 con el parametro -p.
Una vez nos conectemos veremos esto:
Primero nos pedirá una confirmación si es la primera vez que nos conectamos a este servidor, le diremos yes y daremos enter, luego nos pedira la contraseña, la cuál nos la dan en el nivel 0 para poder empezar desde aquí.
Y una vez la ponemos nos daran una bash como el usuario dentro de ese servidor:
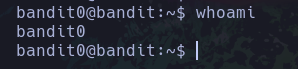
Reparar clear
Aveces no nos dejará usar el comando clear:
![]()
Ya que entra en conflicto con el tipo de terminal, así que vamos a modificar la variable de entorno llamada TERM:

Podemos ver que al hacerle un echo a esa varible de entorno nos dice que usamos una “xterm-kitty” así que con el comando export vamos a modificar la variable de entorno:
export TERM=xterm
De este modo ya no tendremos conflicto al hacer clear, esto paso porque la conexión remota no tiene una xterm-kitty, así que asignamos la que esta por defecto.
Así que una vez arreglamos esto, leemos en las instrucciones del nivel0 a nivel 1 lo siguiente:
Dice que la contraseña del siguiente nivel esta en un archivo llamado readme dentro del directorio personal de el usuario en este caso es bandit0, y que usemos esa password para conectarnos como bandit1 y hacer el siguiente nivel.
Así que al hacer un ls en el directorio personal de nuestro usuario vemos lo siguiente:
Vemos que encontramos el archivo llamado readme y como recordamos en los permisos, este archivo tiene de propietario a bandit1, pero de grupo tiene a el grupo de bandit0, por lo que tenemos permiso de lectura, así que podemos leer el archivo y contiene la contraseña del siguiente nivel. la cuál es: “NH2SXQwcBdpmTEzi3bvBHMM9H66vVXjL”.
Y podemos ver que salimos de la conexión ssh del usuario bandit0 para acceder al usuario bandit1:
Podemos ver que ya estamos conectandonos a el siguiente nivel ya que hemos conseguido la contraseña para acceder al siguiente nivel y se la ponemos, y una vez hecho esto nos dará la conexión ssh:

Vemos que ya estamos en el nivel 1, y ahora debemos encontrar la contraseña para acceder al nivel 2 y así continuamente.
Bandit 1-2: Lectura de archivos con nombre especial
Este nivel nos dice que la contraseña se almacena en un archivo llamado “-“, pero si le hacemos un cat no podremos:
Vemos que no nos deja leer el contenido.
¿Porqué sucede esto?
Esto sucede porque cat detecta el guion como si fuese un parametro vacio, y no lo entiende como archivo, por esto no nos deja leerlo.
Hay multiples formas de leer estos archivos:
Desde su ruta absoluta
cat /home/bandit1/-
De este modo estaremos indicandole la ruta absoluta del archivo y ya no se confundira como antes, y vemos la contraseña.
Indicandole la ruta actual
cat ./-
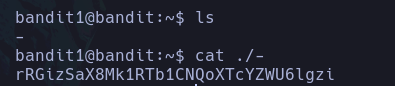
De este modo le estamos diciendo que en la ruta actual nos lea ese archivo.
Con xargs
echo $(pwd)/- | xargs cat
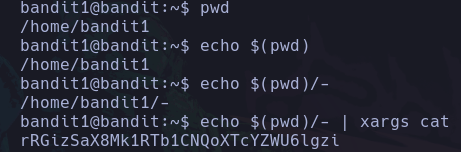
Con esto primero vemos que estamos usando echo e indicandole un comando a nivel de bash, en este caso es pwd, y hacemos esto con echo para poder agregar datos, en este caso estamos agregando a el output esto: /-
Y de este modo nuestro ouptut se verá algo así: /home/bandit1/- y ahora con este output, le diremos a xargs que nos haga un cat en base a la ruta anterior, y le agregamos el /- para apuntar a el archivo llamado guion en la ruta que se encuentra.
Y vemos que de este modo nos muestra la contraseña de igual forma.
También funcionaria si hubiesemos puesto: cat $(pwd)/-
Pero la idea es que practiques de muliples formas para no olvidar los comandos ya que hay muchas formas de hacerlo.
Flag: rRGizSaX8Mk1RTb1CNQoXTcYZWU6lgzi
Bandit 2-3: Lectura de archivos con espacios
Una manera para conectarnos de una forma más rapida es usando sshpass:
sshpass -p "rRGizSaX8Mk1RTb1CNQoXTcYZWU6lgzi" ssh bandit2@bandit.labs.overthewire.org -p 2220
Esto sirve para ingresar la contraseña ya que el comando sshpass tiene un parametro -p para password y la indicamos en medio de comillas dobles, y ya después de esto se usa ssh con los datos del siguiente nivel, en este caso bandit2.

Y ya estaremos dentro de la conexión ssh del serivdor, en este caso vemos un archivo con espacios:

Y para leer archivos con espacios no se usa: cat spaces in this filename ya que nos daría error, porque estaría tomando en cada espacio como un archivo separado y nos daría un error.
En cambio se puede usar:
cat "spaces in this filename"

Podemos ver que podemos leerlo si metemos el nombre del archivo entre comillas dobles, ya que de esta forma le indicamos que solo será uno.
Con escape de espacios
cat spaces\ in\ this\ filename

De esta forma estaremos escapando cada espacio para evitar que se tome como archivo separado.
Autocompletado
cat spa*

Estamos usando el simbolo de asterisco que como recordamos nos sirve para autocompletar automaticamente lo que sigue, como no hay un archivo más aparte de este que se empiece con “spa” entonces nos mostrará el único que hay con ese inicio de letras.
Flag: aBZ0W5EmUfAf7kHTQeOwd8bauFJ2lAiG
Bandit 3-4: Arcivo dentro de directorio oculto
Este nivel nos dice que la contraseña para el siguiente nivel esta dentro de un archivo oculto:
Hemos encontrado el archivo dentro de un directorio llamado inhere, y con ls -a listamos los archivos ocultos y simplemente le hicimos un cat y ya tenemos la contraseña del siguiente nivel.
Flag: 2EW7BBsr6aMMoJ2HjW067dm8EgX26xNe
Bandit 4-5: Deteccion de tipo de archivo y formato.
En este nivel nos dice que la contraseña de almacena entre uno de los tantos archivos disponibles dentro del directorio inhere.
Vemos que hay los siguientes:

Y como nos dice que no todos los vamos a poder leer ya que no todos son texto, lo que haremos será saber que tipo de contenido es ese archivo con el comando file:
Lo vamos a mezclar con find, ya que le diremos lo siguiente a find:
Primero estamos viendo que con el comando find en la ruta actual nos liste todos los archivos que hay.
Y nos los muestra como podemos ver en la imagen.
Y ahora como por cada archivo nos muestra su ruta del directorio actual, simplemente agregaremos un xargs con el comando file para que nos muestre que tipo de archivo es cada uno:
find . | xargs file
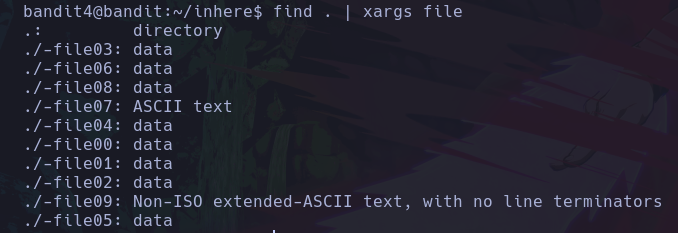
Y podemos ver que el -file07 contiene Texto, por lo que le haremos un cat:

Y ya tenemos la contraseña del siguiente nivel.
Flag: lrIWWI6bB37kxfiCQZqUdOIYfr6eEeqR
Bandit 5-6: Detectar archivo por peso
Este nivel nos dice que la contraseña se almacena dentro del directorio inhere y dentro de este directorio hay mas directorios con archivos diferentes, y en uno de ellos esta la contraseña del siguiente nivel, pero nos dan las siguientes pistas:
- human-readable
- 1033 bytes in size
- not executable
Nos dice que se entiende en humanos por lo que no es algo diferente a texto o numeros, y que pesa 1033 bytes, y no es ejecutable.
Así que con el comando find haremos lo siguiente:
find . -type f -readable ! -executable
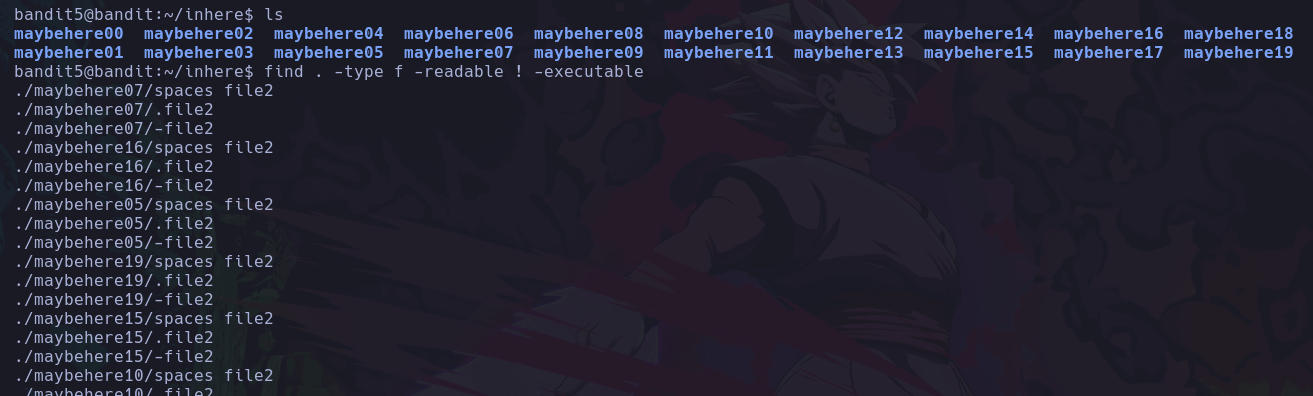
Lo que le estamos indicando es que nos encuentre empezando desde el directorio actual, que nos encuentre archivos, y que tengan permiso de lectura, y que no tengan permiso de ejecución, esto se lo indicamos con el signo de exclamación, indicandole que no sea ejecutable, y nos mostrará unos cuantos como se ve en la imagen.
Pero podemos ver que aún son muchos, por lo que aplicaremos el último filtro por tamaño de bytes:
find . -type f -readable ! -executable -size 1033c

Vemos que agregamos el parametro -size a find , le indicamos el tamaño y con “c” le indicamos que serán bytes.
Y vemos que nos mostro un único archivo, así que este es el que buscamos, le haremos un cat:
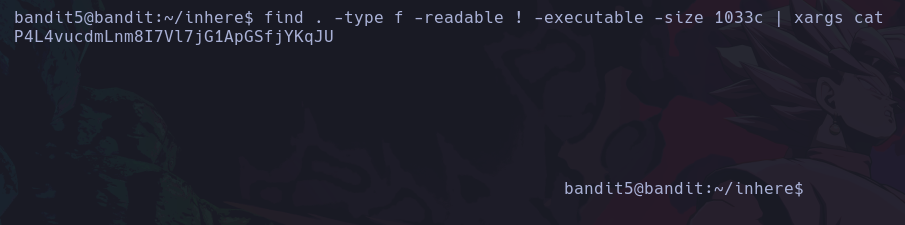
Y vemos que tenemos la contraseña del siguiente nivel, pero vemos que nos hace muchos espacios y nos mueve la terminal, para evitar esto simplemente agregaremos un xargs vacio al final:

Y ya hemos terminado este nivel.
Flag: P4L4vucdmLnm8I7Vl7jG1ApGSfjYKqJU
Bandit 6-7: Busqueda por mas caracteristicas
Nos dice que dentro del sistema existe un archivo con las siguientes caracteristicas:
- owned by user bandit7
- owned by group bandit6
- 33 bytes in size
Que el propietario es bandit7, y pertenece al grupo bandit6, y tiene 33 bytes de tamaño.
Como no nos dice en que directorio se encuentra iremos hasta la raíz y desde aquí buscaremos en todo el sistema archivos con estas caracteristicas:
find . -type f -readable -user bandit7 -group bandit6 -size 33c 2>/dev/null
Vemos que una vez en la raíz vamos apartir de aquí buscar archivos con permiso de lectura, que pertenezcan al usuario bandit7, y a el grupo bandit6 y por último que que tenga de tamaño 33 bytes, y redirigimos los errores al /dev/null ya que habrá directorios a los que no tendremos acceso ya que no somos root:

Y nos muestra la ruta “./var/lib/dpkg/info/bandit7.password” por lo que vamos a leer el contenido:

Y vemos que tenemos la contraseña del siguiente usuario, ya que hemos encontrado su ruta en base a los datos que nos dieron sobre el archivo.
Flag: z7WtoNQU2XfjmMtWA8u5rN4vzqu4v99S
Bandit 7-8: Filtrado de datos con awk
Este nivel nos dice que existe un archivo de texto, pero este archivo contiene demasiado texto que se pierde el que nos interesa.
Pero que esta cerca de la palabra “millionth”, por lo que usaremos grep para filtrar esta parte:
cat data.txt | grep "millionth"

Y vemos que esta alado de esa palabra la contraseña que nos interesa, así que nos quedaremos con el segundo argumento:
cat data.txt | grep "millionth" | awk '{print$2}'
Y vemos que ya nos da la flag para el siguiente nivel.
O también si queremos quedarnos con el último argumento podemos usar:
cat data.txt | grep "millionth" | awk 'NF{print $NF}'

De esta forma podemos imprimir el ultimo argumento de una salida de datos.
Flag: TESKZC0XvTetK0S9xNwm25STk5iWrBvP
Bandit 8-9: Filtrado de datos con sort
En este nivel nos muestra un archivo con demasiado texto:

Como podemos ver, y debemos encontrar la linea que no se repita en el texto, primero ordenaremos por orden cada linea usando el comando sort:
Y podemos ver que se ordenaron todas las lineas por orden numerico y alfabetico, vemos que inician los que tienen 0 al inicio y después seguiran ordenados en forma ascendente.
Y una vez que tenemos ordenado esto simplemente usaremos el comando uniq con el parametro -u para indicarle que nos muestre la linea que no se repite:

Y podemos ver que nos muestra el único valor que no aparece más de una vez en el texto, y podemos ver que ya tenemos la flag del siguiente nivel:
Flag: EN632PlfYiZbn3PhVK3XOGSlNInNE00t
Bandit 9-10: Filtrar strings de un binario
En este nivel encontramos el siguiente archivo:
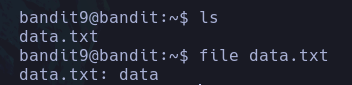
Este archivo aparenta ser un .txt pero si vemos con el comando file, nos damos cuenta que no nos muestra que es “ASCII TEXT” ya que no es texto legible lo que contiene, si no que se puede tratar de un binario.
Ya que al hacerle un cat:

Podemos ver que no se logra entender esto ya que al ser un binario esto es código que a nivel humano no se puede interpretar.
Pero existe un comando llamado strings para que nos muestre las partes del código que son texto y se pueden mostrar que existen entre todo este desorden de caracteres, así que usaremos el comando strings:
Podemos ver que nos ha filtrado las cadenas que son de texto, y aunque en su mayoría no se entiende, podemos ver una que dice “the”, y como el nivel nos decia, que la contraseña estaba en un valor con signos de igual, así que filtraremos con grep las lineas que tengan simbolos de igual:
strings data.txt | grep "======"

Vemos que estamos filtrando por los valores que contengan 6 simbolos de igual y vemos que nos muestra esos valores, vemos que la contraseña es el último valor así que para quedarnos con el último valor de una salida de datos podemos usar el comando tail:
strings data.txt | grep "======" | tail -n 1

Y podemos ver que con el comando tail le hemos dicho que en la linea 1 contando desde la última queremos que nos filtre ese contenido, así que ya nos da de salida solo el último valor, y como en esta linea hay 2 argumentos nos quedaremos con el segundo usando awk como ya sabemos:
strings data.txt | grep "======" | tail -n 1 | awk 'NF{print $NF}'

Y vemos que ya nos hemos quedado solo con la contraseña así que pasaremos al siguiente nivel.
Flag: G7w8LIi6J3kTb8A7j9LgrywtEUlyyp6s
Bandit 10-11: decodificacion y codificacion en base64
En este nivel encontramos un archivo que vemos que tiene texto gracias a el tipo de archivo, y al momento de leerlo nos salta esto:

Nos damos cuenta que es un texto codificado en base64, ya que podemos intuirlo al ver que termina con 2 simbolos de igual.
Y para decodificar un base64 a texto normal podemos usar el comando base64 indicandole que queremos decodificar:

Y podemos ver que ya nos ha decodificado el base64 ya que le hemos pasado la salida del comando cat y con base64 usamos el parametro -d indicandole que decodifique esa salida de datos.
Y por otro lado, para codificar un texto si queremos hacerlo podemos hacerlo de la siguiente manera:

Le pasamos simplemente el comando base64 sin parametros y ya nos ha codificado el texto deseado.
Flag: 6zPeziLdR2RKNdNYFNb6nVCKzphlXHBM
Bandit 11-12: Cifrado cesar
¿Qué es el cifrado cesar?
Este cifrado es confuso al inicio pero cuando lo entiendes es fácil, consiste en lo siguiente:
Supongamos que tenemos la palabra “Hola”, Pero esta palabra cifrada con una rotación de 5 posiciones queda así:
codificar manualmente un texto con cifrado cesar
Primero como son 5 posiciones para invertir en este caso (pueden ser las posiciones que quieras), haremos lo siguiente:
De la primera letra de la palabra que en este caso es “H”, lo que haremos será cambiarla a 5 posiciones a la derecha empezando desde la H y avanzando hacía la derecha en el abecedario dichas posiciones:

En esta imagen que he creado, se nota más detalladamente como codificar esto, y así se hará con cada letra de la palabra.
Y al final quedará la palabra “Mtpf”, que es “Hola” Pero en su valor cifrado cesar.
decodificar manualmente un texto con cifrado cesar
Y ahora en este caso será exactamente lo mismo, pará saber lo que significa la palabra “Mtpf” que esta codificada 5 posiciones en este caso, y saber lo que significa haremos exactamente lo mismo pero esta vez contando en dirección contraria, osea a la izquierda:

Y de este modo haremos con el resto de letras, y obtendremos “Hola”.
Así que una vez entendido el cifrado cesar, pasaremos a como hacerlo automatizadamente:
Vemos el siguiente archivo en el bandit:

Vemos que nos dan el valor: Gur cnffjbeq vf WIAOOSFzMjXXBC0KoSKBbJ8puQm5lIEi
Por lo que haremos lo siguiente:
cat data.txt | tr '[G-ZA-Fg-za-f]' '[T-ZA-St-za-s]'
Lo que estamos haciendo en el primer parametro: [G-ZA-Fg-za-f] es que primero se tomará la primera letra del texto que se pase como salida de datos, y verá si existe en el rango de la G hasta la Z tanto en minusculas como mayusculas y es G ya que es la primera letra con la que empieza el texto cifrado, y de la , y en caso de que exista, lo que hará el siguiente parametro es lo siguiente:
[T-ZA-St-za-s] Como en el primer parametro empezamos desde la G ahora contaremos 13 hacia atrás ya que en este caso son 13 rotaciones, asi que si contamos de la G hacia atrás 13 posiciones llegamos a la T, así que contaremos desde la T hasta la Z y desde la A a la F (antes de nuevamente la T), y de este modo englobaremos todo el abecedario invertido en 13 posiciones, así que simplemente se reemplaza la primera letra por su valor invertido 13 posiciones.
Y así se iran invirtiendo 13 posiciones anteriores por cada letra y será reemplazada por su valor invertido, y esto nos dará la contraseña del siguiente nivel:

El valor actual va a ser reemplazado por el valor que esta a 13 rotaciones atrás de nuestro valor actual.
Flag: JVNBBFSmZwKKOP0XbFXOoW8chDz5yVRv
Bandit 12-13: Hexdump y creacion de un script para automatizar el reto
En este nivel nos piden lo siguiente:
“La contraseña para el siguiente nivel se almacena en el archivo data.txt, que es un hexdump de un archivo que se ha comprimido repetidamente. Para este nivel puede resultar útil crear un directorio en /tmp en el que pueda trabajar utilizando mkdir. Por ejemplo: mkdir /tmp/minombre123. Luego copie el archivo de datos usando cp y cámbiele el nombre usando mv (¡lea las páginas de manual!)”.
¿Qué es un hexdump?
Un hexdump(volcado hexadecimal), es una vista en hexadecimal de los datos de un elemento, como un archivo.
Ahora al entrar al nivel y lo primero que vemos es un archivo .txt que contiene esto:
Vemos que contiene todo este valor, el cual es un tipo de archivo con x contenido.
Primero, para saber que tipo de archivo es esto, revisaremos los magicnumbers.
¿Qué es un magicnumber?
Los magicnumber son un conjunto de bytes que indica el tipo de archivo que estamos analizando.
Por ejemplo, en este archivo analizaremos los primeros numeros que describen el tipo de archivo que contiene el resto de datos:
Podemos ver que este archivo inicia con “1f8b”, y al buscar esto en una web que contiene magicnumbers y su tipo de archivo, encontramos lo siguiente:
Y podemos ver que se trata de un archivo comprimido con extensión .gz.
Constryendo el hexdump a archivo comprimido
Como ya vimos que este hexdump es de un archivo comprimido .gz, lo que haremos es transformarla en eso:
Primero copiaremos el contenido del archivo que contiene el hexdump:
y lo pegaremos en un nuevo archivo en nuestro equipo local, y una vez ya tengamos un archivo con el hexdump pegado en nuestro equipo se verá así:
Aquí hemos creado un archivo llamado data y con nano le metemos el contenido anteriormente copiado del hexdump.
Y ya tendremos este archivo:
Ahora que ya tenemos el archivo como estaba en el nivel de bandit, lo que haremos ahora será meter el valor hexadecimal pero de forma interpretada, por lo que de cierta forma se transforma en el archivo que en realidad es, y esto lo haremos así:
cat data | xxd -r | sponge data

Lo que hacemos es que le pasamos el contenido de data a el comando xxd -r que lo que hace esto es convertirnos el hexadecimal pasado a su valor transformado, y con sponge lo que hacemos es reemplazar el valor que tenia ese archivo por el nuevo valor, que en este caso será el binario ya transformado de hexdump a .gz.
Y podemos ver que ya hemos convertido el hexdump en un binario que en este caso es un archivo comprimido .gz.
La herramienta sponge se instala con: sudo apt install moreutils si estas en sistema basado en debian. O pacman -S moreutils si tu sistema esta basado en arch Linux.
Y ahora que ya tenemos el archivo .gz listo, lo que haremos será crear un script ya que el nivel nos dice que este archivo comprimido contiene dentro otro comprimido el cual contiene otro comprimido y así hasta llegar a un archivo final que es la contraseña.
Para ahorrarnos este trabajo vamos a crear un script.
Primero le cambiaremos el nombre al archivo data ya que sabemos que es un .gz y se lo asignamos tal y como es:
Ahora, con la herramienta 7z podemos saber más sobre el archivo comprimido y saber que contiene antes de extraerlo.
Listar contenido sin extraer
7z l data.gz
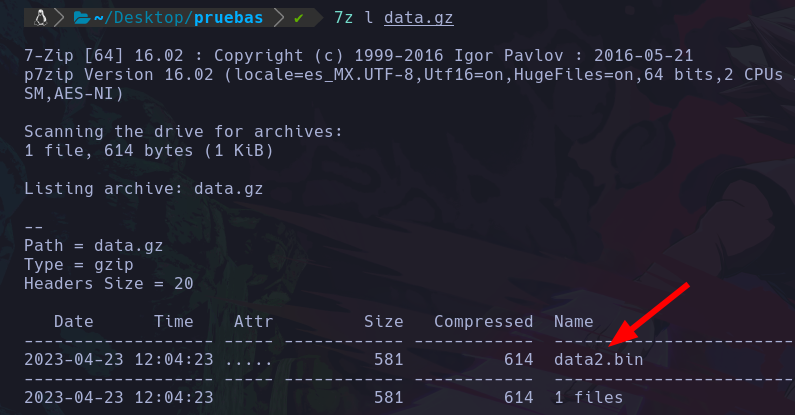
Con el parametro l de 7z podemos listar lo que contiene el archivo data.gz pero solo veremos el nombre del contenido que existe no el contenido en si.
Extraer contenido
Y ahora para extraer el contenido del data.gz lo que haremos será:
7z x data.gz
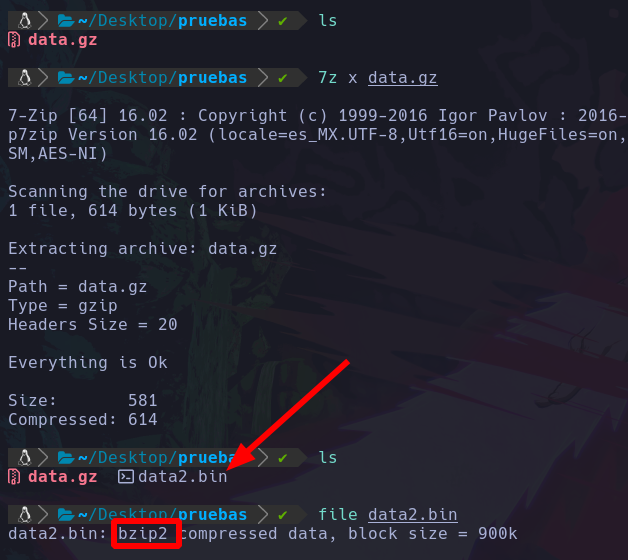
De este modo ya hemos extraido el contenido del data.gz y vemos que nos dejo un archivo llamado “data2.bin”, el cual es un archivo ahora comprimido en bzip2.
Y al leer su contenido vemos que contiene otro archivo:
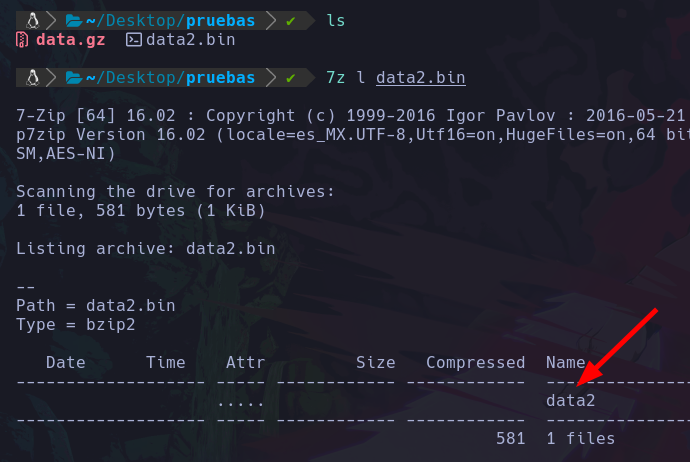
Y vemos que contiene un archivo llamado “data”, y este archivo será un comprimido que contendra otro tipo de comprimido etc.
7z nos permite extraer muchos formatos de comprimido por eso al hacer 7z x nos extrae comprimidos que no necesariamente son .gz.
Y como seguramente ese archivo será un comprimido que contendrá otro:
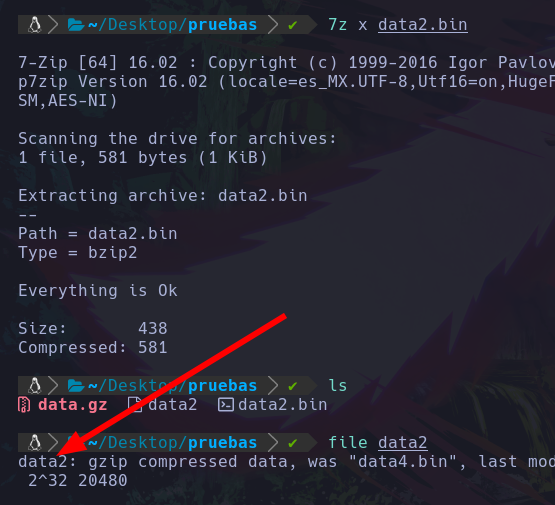
y asi sucesivamente extraer y extraer hasta llegar a el archivo final que es la contraseña, pero haremos un script para automatizar esto y no hacerlo de esta forma tan cansada.
Creacion de un script para automatizar la extraccion de archivos recursivamente
Primero eliminaremos los archivos menos el original:
Una vez eliminados, crearemos un archivo shell, en este caso será “extractor.sh”:
Y ya le dimos permisos de ejecución y podremos empezar a escribir nuestro script.
Creando la funcion de salida
Primero vamos a crear una función que nos permita salir del programa en caso de que no queramos que se siga ejecutando, para ello hacemos lo siguiente:
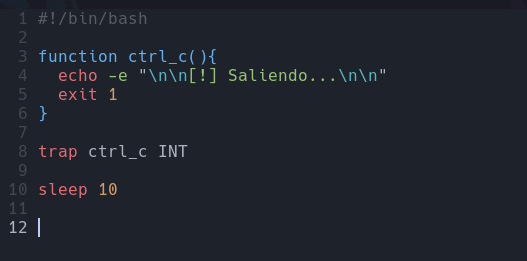
#!/bin/bash
function ctrl_c(){
echo -e "\n\n[!] Saliendo...\n\n"
exit 1
}
trap ctrl_c INT
sleep 10
Primero agregamos la cabecera, después definimos la función que se llama ctrl_c en este caso, y dentro del contenido de esta función hacemos un echo con el parametro -e para que nos lea caracteres especiales como los saltos de linea. Y lo que hará este echo será mostrarnos el texto “[!] Saliendo…” pero con 2 saltos de linea al inicio y al final que se definen con \n.
Y despúes de imprimir el aviso, hacemos el comando para cerrar el programa, en este caso hacemos exit con el estado de error 1, ya que no fue una ejecución exitosa del script.
trap ctrl_c INT Esto lo pusimos para que cuando se presione ctrl + c se va a llamar la función ctrl_c que definimos anteriormente.
sleep 10 Esto no forma parte del código pero lo agregamos para probar que nos funcione la funcion que queremos, ya que si no hacemos una pausa el script se ejecutara en menos de un segundo y no tendremos tiempo de probar hasta ahora si el ctrl_c funciona, así que lo agregamos temporalmente solo para verificar que funcione nuestra función.
Y cuando ejecutemos el script esperara 10 segundos que podemos aprovechar para presionar ctrl + c y ver si funciona la función:
Podemos ver que ha funcionado correctamente.
Agregando colores al script
Ahora agregaremos colores para que se vea mucho mejor nuestro script, ya hicimos esto antes en un script pequeño que creamos anteriormente, y como recordamos usamos la siguiente paleta de colores en variables:
#Colours
greenColour="\e[0;32m\033[1m"
endColour="\033[0m\e[0m"
redColour="\e[0;31m\033[1m"
blueColour="\e[0;34m\033[1m"
yellowColour="\e[0;33m\033[1m"
purpleColour="\e[0;35m\033[1m"
turquoiseColour="\e[0;36m\033[1m"
grayColour="\e[0;37m\033[1m"
Y una vez los agreguemos a el script vamos a llamarlos como recordamos:
#!/bin/bash
#Colours
greenColour="\e[0;32m\033[1m"
endColour="\033[0m\e[0m"
redColour="\e[0;31m\033[1m"
blueColour="\e[0;34m\033[1m"
yellowColour="\e[0;33m\033[1m"
purpleColour="\e[0;35m\033[1m"
turquoiseColour="\e[0;36m\033[1m"
grayColour="\e[0;37m\033[1m"
function ctrl_c(){
echo -e "\n\n${redColour}[!] Saliendo...${endColour}\n\n"
exit 1
}
trap ctrl_c INT
sleep 10
Vemos que hemos agregado esto, recordamos que llamamos a un color llamandolo en su variable con ${redColour} y lo cerramos con {endColour} en este caso usamos el rojo pero puedes usar el que quieras.
Y el resultado será algo así:
Vemos que se ve mucho mejor.
Definiendo las variables
Como recordamos el objetivo del script, que es descomprimir multiples veces un archivo, primero crearemos una variable que almacene el nombre del archivo, recordamos que se llama “data.gz” por lo que haremos una variable con ese nombre para después ir manejando el archivo con ese nombre.
primer_archivo="data.gz"
Una vez agregamos esta variable llamada primer_archivo almacenamos el nombre del archivo.
Y esto lo hacemos para después saber si este archivo contiene otro archivo dentro, recordamos el comando 7z con el parametro -l que nos lista y ver si existe un archivo dentro de ese comprimido en ser el caso.
Como recordamos el archivo que contiene el archivo principal se puede ver como acabo de decir, con 7z l data.gz, pero como será un script entonces nos interesa quedarnos con el puro nombre del siguiente archivo, para ello usaremos comandos para ir filtrando lo que nos interesa:

Podemos ver que con el comando tail y su parametro -n 3 lo que hicimos fue ir a la ultima linea y que nos muestre las ultimas 3 lineas en este caso, y ahora ya solo tenemos las 3 ultimas lineas pero nos interesa quedarnos con el purno nombre, por lo que ahora:
Nos vamos a quedar con la primera linea usando head con su parametro -n 1 que head es lo contrario a tail, nos muestra desde la primera linea las que le indiquemos para abajo, en este caso nos interesa solo la linea 1:

Y ya simplemente nos quedaremos con el último argumento usando awk:

Y ahora ya nos hemos quedado con el valor que nos interesa.
Ahora esta linea creada de comandos la meteremos a una variable que nos almacene el nombre del siguiente archivo a descomprimir en caso de haberlo, y la función quedaría algo así:
function ctrl_c(){
echo -e "\n\n${redColour}[!] Saliendo...${endColour}\n\n"
exit 1
}
trap ctrl_c INT
primer_archivo="data.gz"
siguiente_archivo="$(7z l $primer_archivo | tail -n 3 | head -n 1 | awk 'NF{print $NF}')"
Vemos que creamos la variable siguiente_archivo que va a almancenar en forma de string/cadena de texto, el valor que obtengamos de la salida de comando ejecutado usando bash a nivel de sistema el cuál explicamos anteriormente, y lo almacenamos en una string gracias a que guardamos entre comillas dobles la ejecución del comando, osea su salida que será el nombre del siguiente archivo en caso de haberlo.
Y vemos que en la variable siguiente_archivo usamos 7z l $primer_archivo en lugar de 7z l data.gz ya que ahora estamos usando la variable primer_archivo ya que por algo la creamos, y para llamar al contenido de una variable se usa el signo de dolar como cuando llamamos a los colores.
Y el código se verá algo así:
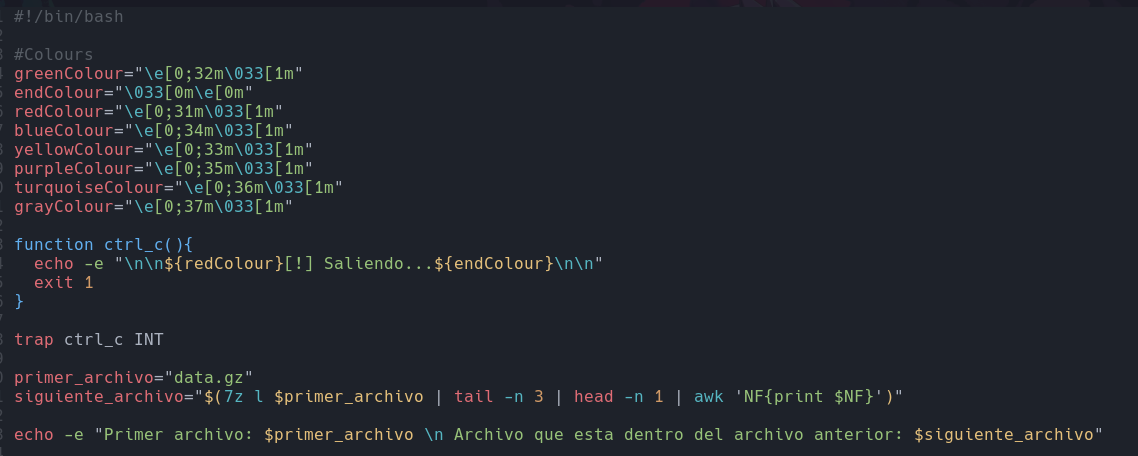
Vemos que agregamos un echo solo para comprobar que las variables estan correctamente definidas en la ejecución del script:

Y vemos que funciona, esta linea que nos imprime el contenido de las variables solo lo hicimos para comprobar que funcionará , y ahora que vemos que todo esta bien, quitaremos ese echo y ahora seguiremos con el script.
Extraer el primer archivo comprimido
Ahora vamos a extraer el primer archivo comprimido , por lo que agregaremos esta instrucción, y redirigiremos el stderr y el stdout a el /dev/null para que no nos muestre nada en pantalla sobre esta ejecución.
7z x $primer_archivo &>/dev/null
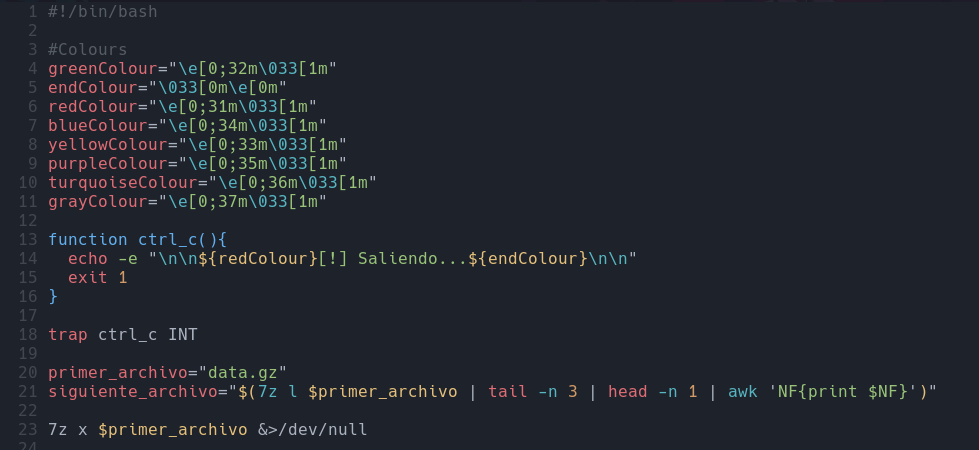
Vemos que le indicamos que queremos descomprimir el primer archivo, y apartir de este vamos a realizar un ciclo while que nos va a extraer el resto de archivos:
while [ $siguiente_archivo ]; do
echo -e "\nEl archivo actual descomprimido es: $siguiente_archivo\n"
7z x $siguiente_archivo &>/dev/null
siguiente_archivo="$(7z l $siguiente_archivo 2>/dev/null | tail -n 3 | head -n 1 | awk 'NF{print $NF}')"
done
Primero, usamos while que esto es un ciclo que nos va a repetir las instrucciones dentro del while, siempre y cuando una condicion sea verdadera, en este caso la condicion es: [ $siguiente_archivo ]; que lo que hace esto es que si le pasamos solo una variable, quiere decir que se va a repetir en ciclo mientras la variable $siguiente_archivo tenga contenido.
Y después con el primer echo, mostramos en pantalla que el archivo actual que se va a descomprimir es el que esta en la variable siguiente archivo.
Y después con 7z extraemos ese archivo actual.
Y por último vamos a actualizar la variable siguiente_archivo, ya que ahora va a guardar el nombre del siguiente archivo y como el while se va a repetir, ahora comprueba que $siguiente archivo contenga datos, como acabamos de guardar un valor entonces pasará y ahora imprimira de nuevo pero ahora nos mostrará el siguiente archivo y ahora extraera ese nuevo archivo, y por ultimo vuelve a actualizar el nombre del siguiente archivo.
Y así sucesivamente hasta llegar a el último archivo que no es un comprimido, entonces dará error y ya no guardará un valor dentro de la variable siguiente_archivo, por lo que el while se dentendra justo en el último archivo.
Y así se ve el script terminado:
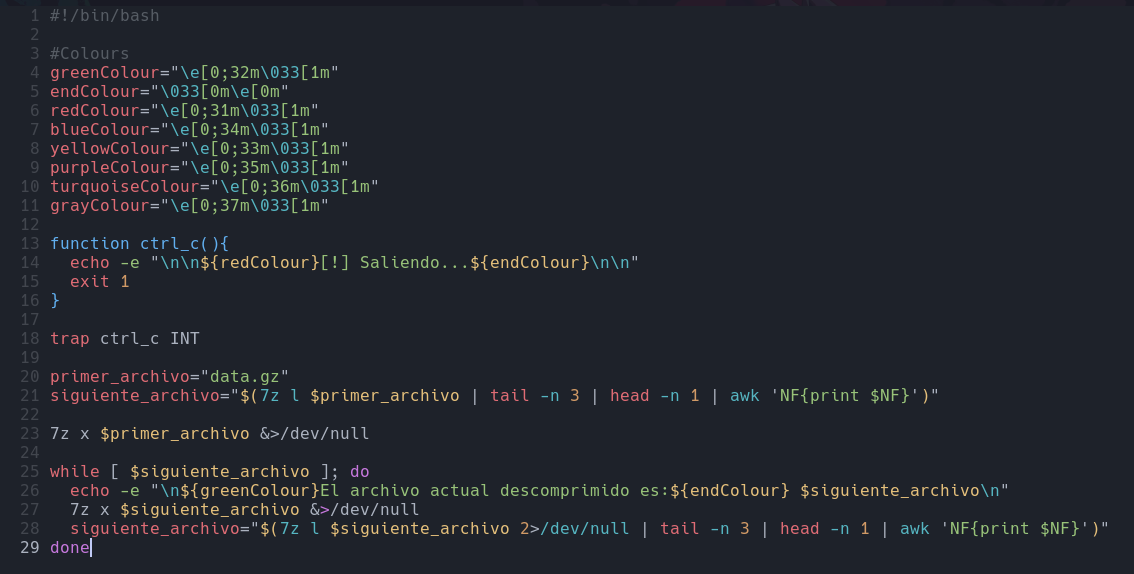
#!/bin/bash
#Colours
greenColour="\e[0;32m\033[1m"
endColour="\033[0m\e[0m"
redColour="\e[0;31m\033[1m"
blueColour="\e[0;34m\033[1m"
yellowColour="\e[0;33m\033[1m"
purpleColour="\e[0;35m\033[1m"
turquoiseColour="\e[0;36m\033[1m"
grayColour="\e[0;37m\033[1m"
function ctrl_c(){
echo -e "\n\n${redColour}[!] Saliendo...${endColour}\n\n"
exit 1
}
trap ctrl_c INT
primer_archivo="data.gz"
siguiente_archivo="$(7z l $primer_archivo | tail -n 3 | head -n 1 | awk 'NF{print $NF}')"
7z x $primer_archivo &>/dev/null
while [ $siguiente_archivo ]; do
echo -e "\n${greenColour}El archivo actual descomprimido es:${endColour} $siguiente_archivo\n"
7z x $siguiente_archivo &>/dev/null
siguiente_archivo="$(7z l $siguiente_archivo 2>/dev/null | tail -n 3 | head -n 1 | awk 'NF{print $NF}')"
done
Y en su ejecución se verá algo así (Yo le he agregado colores):
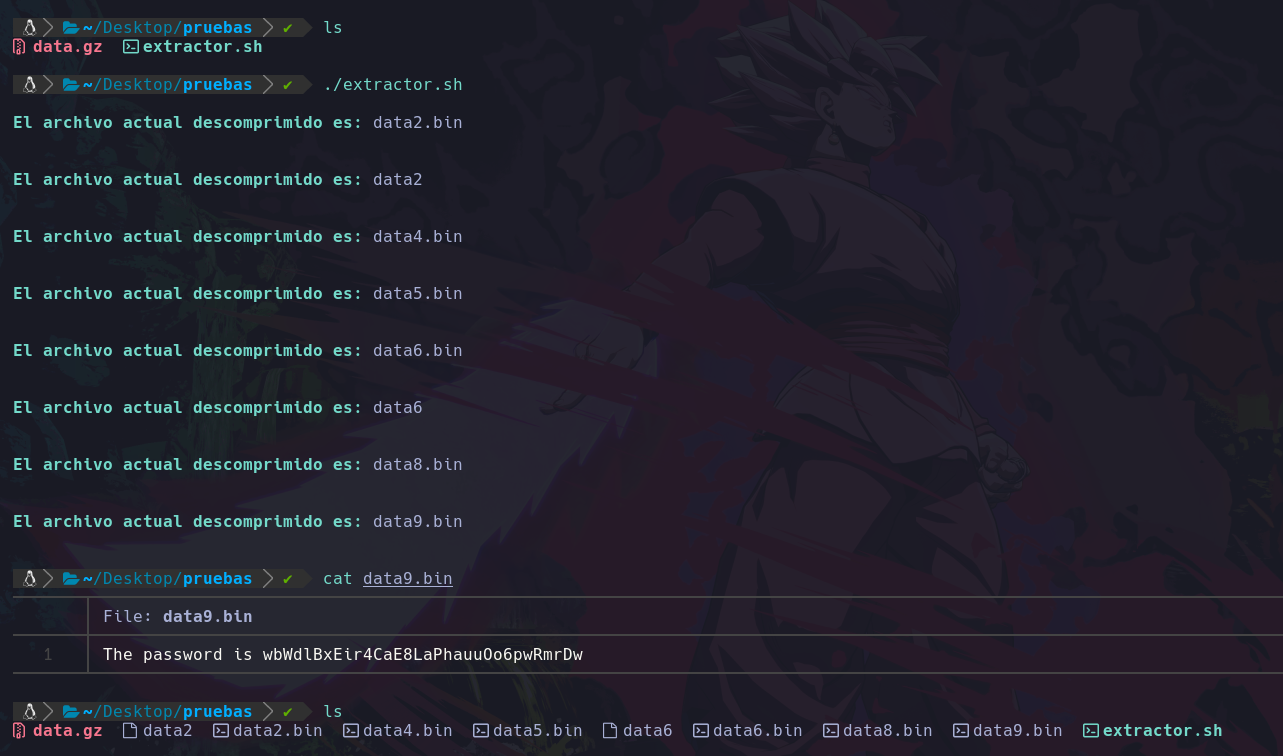
Y podemos ver que ha funcionado correctamente, como el último archivo fue data9.bin entonces ese es el final que no es un comprimido.
En pocas palabras lo que hace el while es ir extrayendo el archivo actual en base a su variable, e ir actualizando el siguiente archivo en la varible para que se extraiga el siguiente en la siguiente repeticion del while y así hasta llegar al que no es un comprimido.
Flag: wbWdlBxEir4CaE8LaPhauuOo6pwRmrDw
Bandit 13-14: Uso de pares de claves y conexiones SSH
Ahora aprenderemos a hacer uso de las conexiones ssh, que sabemos que es para conectarnos a un servidor o maquina.
Si queremos conectarnos a una maquina por medio de SSH, podemos hacerlo de la siguiente forma:
Primero debemos encender el servicio ssh:
sudo systemctl start ssh
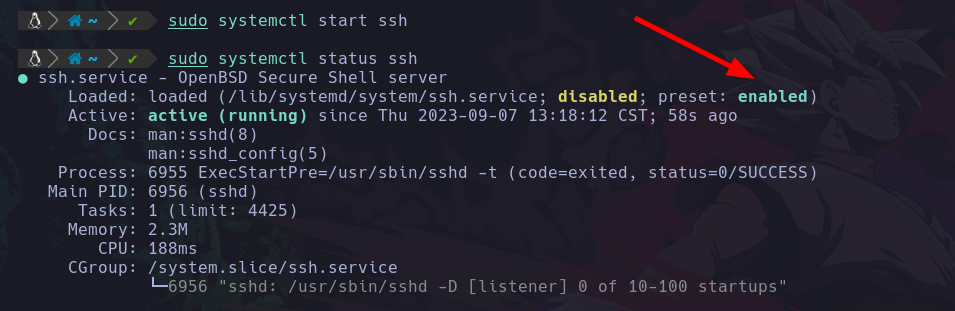
De este modo estamos encendiendo el puerto 22(ssh), para poder tener conexiones por medio de esta.
Y vemos que al activar el servicio vemos su status y nos dice que esta activo.
Así que ya podremos hacer una conexión normal.
Conexion normal
Supongamos que queremos hacer una conexión normal, entonces haremos lo siguiente:
ssh f4r@localhost
Estamos intentando acceder a una shell del usuario f4r en la red “localhost”, que es mi propia red local pero en caso real se usaría una IP del objetivo a donde quieres conectarte y al hacerlo te pedirá la contraseña del dicho usuario en este caso f4r, y al ingresarla obtendremos una shell por medio de ssh:
Podemos ver que hemos establecido una conexión con ese usuario, ya que la maquina actual es la que existe ese usuario y tiene el puerto ssh habilitado.
Para cerrar una conexión ssh simplemente ejecutamos “exit”.
Conexion SSH por medio de la clave publica
Esta conexión nos sirve para conectarnos a un equipo que tenga almacenada nuestra clave publica en su servidor y podrmeos acceder sin proporcionar contraseña ya que estaremos identificados dentro del sistema destino.
Osea en pocas palabras, si existe nuestra llave en el servidor al que queremos conectarnos, entonces podremos hacerlo sin proporcionar contraseña.
Por ejemplo, primero iremos a la ruta oculta: “/home/d4nsh/.ssh” y una vez dentro de aquí, vamos a generar una par de claves usando:
ssh-keygen
Al generarlas, dejaremos todo por defecto por lo que solo damos enter a lo que nos muestre hasta que se generen y una vez generadas vemos que nos dejo 2 archivos.
Uno llamado id_rsa y otro llamado id_rsa.pub.
En este caso empezaremos con id_rsa.pub, ya que esta es la llave pública.

Al final de la llave podemos ver que esta llave publica permite al usuario d4nsh conectarse a este equipo.
Para que esto funcione el archivo de llave publica debe llamarse authorized_keys y debe estar en el directorio “/home/d4nsh/.ssh” que sabemos que se encuentra oculto dentro de nuestra carpeta personal en este caso.
Así que hacemos una copia que se llame authorized_keys:
Y vemos que ya hemos creado una copia de id_rsa.pub por authorized_keys.
Y ahora como ya tenemos nuestra clave publica que generamos y esta dentro del directorio ssh oculto, entonces ya podremos acceder a esta maquina, que en este caso es la misma pero ya no nos pedirá contraseña:
Podemos ver que nos ha dejado ingresar sin proporcionar la contraseña ya que como dije, anteriormente hemos generado nuestra llave publica y almacenamos en el servidor al cual queremos conectarnos sin proporcionar contraseña, en este caso el servidor es nuestra propia maquina.
Otro ejemplo mas descriptivo
Supongamos que queremos que el usuario f4r se conecte sin proporcionar contraseña a el usuario d4nsh y nos muestre una shell, para ello usaremos la llave publica.
Primero, como el usuario f4r, vamos a generar nuestras llaves:
Hemos generado nuestras llaves, ahora vamos a copiar el contenido de esta llave publica, y almacenarlo en el directorio ~/.ssh del usuario d4nsh.
Para ello vamos a crear un archivo llamado authorized_keys dentro del directorio ~/.ssh de d4nsh, y le meteremos los datos de la llave publica de f4r:
Vemos que ya tenemos el archivo con la llave de f4r, así que f4r podrá acceder a d4nsh por medio de ssh y desplegar una shell como el usuario d4nsh:
Y podemos ver que entablamos una conexión en la maquina con el usuario d4nsh ya que en su usuario, en su directorio .ssh se encuentra nuestra llave publica, por lo que logramos la conexión sin proporcionar la contraseña.
Recuerda eliminar las llaves que no vayas a usar.
Conexion SSH por medio de la clave publica
Ahora si queremos que por medio de una llave que nosotros tengamos puedan acceder a nuestro equipo las personas que tengan esta llave ya sea porque se las pasamos o por otra razón.
Para eso usaremos la llave que se llama id_rsa:
Usaremos esta ya que queremos que los que tengan esta llave se conecten a nuestro equipo como el usuario d4nsh.
Y para habilitar esto debemos hacer lo siguiente:
ssh-copy-id -i id_rsa d4nsh@localhost
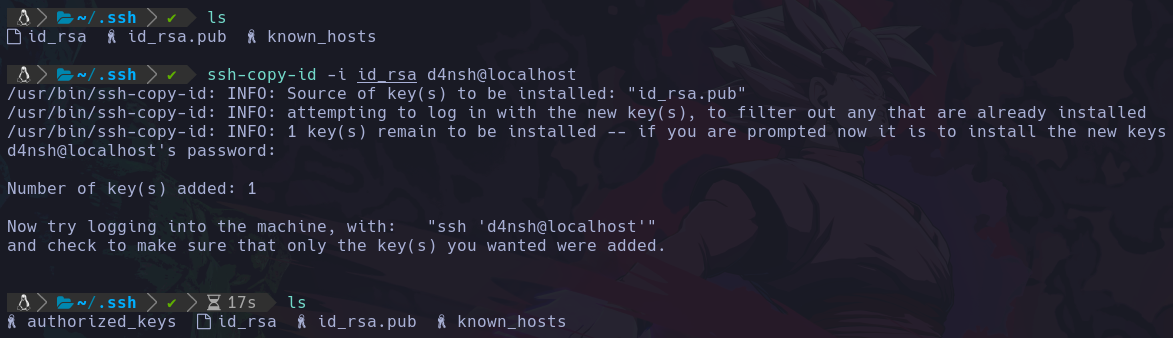
Una vez habilitamos esto, ahora cualquiera que tenga el archivo id_rsa, podrá conectarse a nuestro equipo como d4nsh.
Por ejemplo copiaremos el contenido del id_rsa de d4nsh:
Copiamos el contenido del id_rsa que tiene el usuario d4nsh dentro de su llave privada, y como ya habilitamos que cualquiera que tenga esta llave privada pueda conectarse a la maquina como el usuario d4nsh, ya que autorizamos la llave id_rsa.
Entonces ahora si estamos como otro usuario como f4r y creamos un archivo que se llame id_rsa y contenga esto que copiamos:
Y ahora como el usuario f4r, creamos el archivo id_rsa con el contenido que copiamos del id_rsa de d4nsh, una vez lo hayamos creado, cambiaremos su permiso a 600:
chmod 600 id_rsa
Esto es ya que el 600 es el permiso que tienen las llaves id_rsa para que funcionen, y ahora simplemente usaremos ssh llamando a esa llave usando el parametro -i y pasandole la llave privada, y diciendo el usuario al cual nos queremos conectar, como en este caso d4nsh admite esta llave ya que el la creo, nos conectaremos sin contraseña y solo con su llave privada:
ssh -i id_rsa d4nsh@localhost
Y vemos que ya ha funcionado, y estas han sido las 2 explicaciones de la conexión por llaves usando SSH.
Recuerda eliminar las llaves si no las usaras y detener el servicio ssh si no se usara con: sudo systemctl stop ssh.
Resolviendo el nivel
Ahora que ya entendimos esto, era fundamental aprender esto ya que este bandit trata sobre ssh, nos dicen que al entrar no habrá contraseña pero si habrá una llave privada para acceder al siguiente nivel.
Al entrar encontramos la siguiente llave:
Vemos que se trata de una llave privada, por lo que intuimos que es del usuario bandit 14 y usamos esta llave para ingresar:

Y podemos ver que ya nos ha entrado a el usuario bandit14:
Recuerda que en niveles donde se salte leer la flag podemos leerla desde la ruta:
cat /etc/bandit_pass/bandit14
Flag: fGrHPx402xGC7U7rXKDaxiWFTOiF0ENq
Bandit 14-15: Conexiones TCP/UDP con netcat
Netcat nos sirve para realizar conexiones TCP(Transfiere los datos más lentos pero seguro), Y UDP (Transfiere los datos más rapido pero con mayor riesgo de perder paquetes).
Y este nivel nos dice que desde la maquina del usuario actual osea bandit14, debemos hacer una conexión con el servidor usando netcat por medio del puerto 30000.
Y que para hacer esta conexión y obtener una respuesta debemos enviar la contraseña del usuario actual para recibir la del siguiente nivel.
Así que al entrar al nivel actual, usaremos netcat de la siguiente forma:
nc bandit.labs.overthewire.org 30000
Podemos poner su DNS que es bandit.labs.overthewire.org, o la ip del localhost 127.0.0.1.
nc es netcat y le estamos indicando que atienda a la conexión que esta en el servidor, y el puerto el cual nos indico el nivel que esta habilitado para recibir un valor, en este caso este valor es la contraseña del usuario actual, ya que recordamos que debemos ingresarla para recibir la del siguiente nivel.
Por eso vemos en la imagen que se queda en espera , y esto es porque detecta que necesita un valor para responder, así que meteremos la contraseña del usuario actual:

Y vemos que se ha realizado la conexión por netcat por lo cúal recibimos la respuesta del servidor y tenemos la contraseña.
Flag: jN2kgmIXJ6fShzhT2avhotn4Zcka6tnt
Contenido extra: Como saber que puertos estan abiertos en mi equipo
Para esto hay multiples formas, supongamos que tenemos el servicio ssh habilitado, por lo que nos debe abrir el puerto 22 ssh, lo activaremos:
sudo systemctl start ssh

Y vemos que con el comando: ss -nltp podemos ver los puertos abiertos en nuestra red.
Y vemos que el puerto 22 esta abierto.
Otra forma de ver los puertos abiertos es leyendo el archivo de sistema que se encuentra en la ruta /proc/net/tcp, le haremos un cat y veremos lo siguiente:
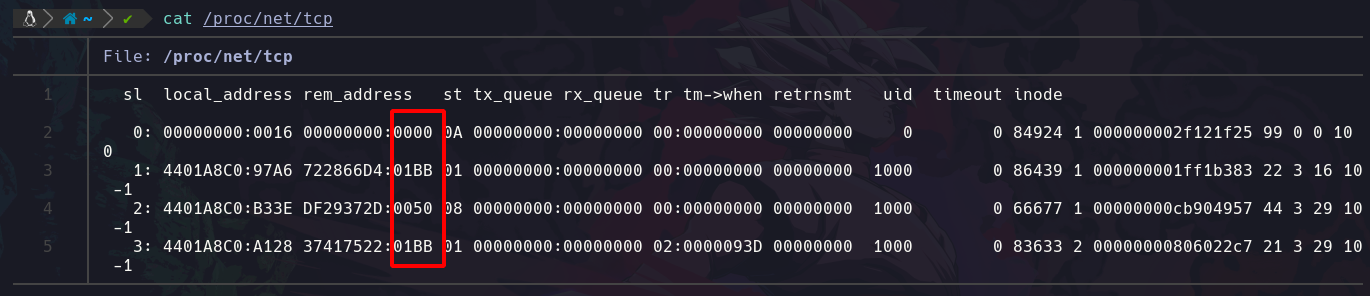
Y podemos ver una serie de elementos en hexadecimal, los puertos en hexadecimal son los que estan encerrados en el recuadro rojo.
Creando un one-liner para traducir los puertos hexadecimal a sus valores en texto claro
Primero hemos separado los puertos hexadecimal en lineas separadas:
Ahora vamos a usar el ciclo while para ir iterando sobre cada linea:

Lo que esta haciendo el while:
while read line; do echo "[*] Puerto actual $line"; done
Es que este ciclo se va a repetir mientras haya algo que leer en la linea actual, y después si hay algo que leer entonces ejecutará las instrucciones después de do, y lo que hará esto es que lo que hay en la linea actual, que en este caso es el primer valor que pasamos en la primera linea, lo guarda en la variable line, y después mostramos un mensaje que diga que puerto es el actual y para mostrar esto en pantalla mandamos a llamar a la variable line con $line, y terminamos con done. Y así seguira con las siguientes lineas hasta que no haya que leer va a terminar.
Y podemos ver en la ejecución que nos mostro todo correctamente cada linea, ya que este ciclo while read line, va iterando sobre cada linea del texto pasado como parametro.
Ahora pasaremos esto pero para traducir su valor hexadecimal a texto claro.
Ahora que ya entendimos el while read line, veamos esta linea que con bash nos traduce elementos en hexadecimal:
| ` echo “obase=10; ibase=16; “0050”” | bc` |
Lo que hace es establecer los valores que maneja hexadecimal y después le pasamos el valor que queremos traducir, en este caso es “0050”, y por ultimo usamos el bc para que nos interprete lo que le hemos indicado:

Y vemos que nos traduce el valor, así que agregaremos esto a el one-liner que teniamos anteriormente quedandonos así:
echo "01BB
0050
01BB" | while read line; do echo "[*] Puerto $line -> $(echo "obase=10; ibase=16; $line" | bc) - ABIERTO"; done

Podemos ver que usamos la variable de la linea actual para pasarsela a la instruccion ejecutada por bash que nos traduce el valor hexadecimal, y mostramos un mensaje en pantalla de el puerto normal y el traducido con una flechita.
Recuerda usar sort -u al final si no quieres que se vean puertos repetidos y solo te muestre los unicos:

Y con el comando lsof -i:22 podemos ver en este ejemplo que servicio esta corriendo el puerto 22, pero puedes poner el que deseas y ver.
Bandit 15-16: Conexion TCP/UDP con encriptacion SSL usando ncat
Ahora nos piden mandar la contraseña del usuario actual a el servidor por el puerto 30001 pero ahora de forma que la informacion que mandemos este encriptada en SSL.
Para ello usaremos ncat, no netcat.
Podemos instalar ncat usando sudo apt install ncat.
Y lo haremos de la siguiente forma desde el nivel actual de bandit:
ncat --ssl bandit.labs.overthewire.org 30001
Y de este modo la información viajara protegida con la encriptacion SSL, así que al meter la contraseña del usuario actual recibimos la del siguiente nivel:

Y hemos recibido la respuesta del servidor.
Flag: JQttfApK4SeyHwDlI9SXGR50qclOAil1
Bandit 16-17: Creando un script para detectar puertos abiertos
Primero, para saber que puerto esta abierto en un host, podemos enviar un paquete y en base a su respuesta saber si esta abierto o cerrado, para ello usaremos un one liner que nos permita hacer esto.
Primero abriremos el puerto 22 en nuestro equipo para hacer la prueba:
sudo systemctl start ssh
Y ahora que lo hemos abierto vamos a ver como podemos saber si este puerto esta abierto.
Primero ocupamos la IP a donde mandaremos una consulta y en este caso como es nuestro propio equipo, con el comando hostname -I podremos ver nuestra propia IP:

En este caso la IP privada de mi equipo es: 192.168.1.68
Y ahora vamos a hacer el one-liner que nos permitira saber si el puerto esta cerrado o abierto, migraremos a una bash para evitar un error que provoca zsh en este caso.
Y lo que haremos será lo siguiente:
echo '' > /dev/tcp/192.168.1.68/22
De este modo estamos enviando una cadena vacia a el host de nuestra ip por el puerto 22 en este caso:
Y vemos que al hacer esto no nos muestra nada, pero esto significa que ese puerto en el host esta abierto, ya que el paquete vacio se ha enviado correctamente, ya que si ponemos un puerto que no este abierto como el 40:
Vemos que inmediatamente nos arroja un error de que no se pudo conectar a ese puerto, lo que indica que esta cerrado.
Y sabiendo esto vamos a crear un script que indique que puertos estan abiertos en un host.
Como en total existen 65535 puertos, usaremos una utilidad llamada seq que nos permite crear secuencias de un numero a otro, tal que así:
seq 1 30

Y esto lo que hará es imprimirnos en lineas separadas una secuencia de numeros del 1 hasta el 30 en este caso.
Pero obviamente en el script pondremos el numero total de puertos (65535).
Y como ya vimos esta utilidad vamos a pasar a el one liner, por ejemplo:
(echo '' > /dev/tcp/192.168.1.68/22) &>/dev/null && echo "[!] El puerto esta abierto" || echo "[x] El puerto esta cerrado"
| Primero enviamos una cadena vacia a el host deseado junto con el puerto deseado en este caso el host es el 192.168.1.68 y el puerto es el 22, y esto esta encerrado en parentesis para separar la primera instruccion del resto, y redirigimos tanto el stderr y el stdout a el /dev/null, y en caso de que la instrucción anterior sea verdadera entoces se ejecutara el operador AND(&&), y lo que hará es mostrarnos un mensaje que imprime en pantalla que ese puerto esta abierto, y de lo contrario si no se cumple la condición del AND, entonces pasaremos a el OR ( | ) que nos muestra en pantalla que el puerto esta cerrado ya que no hemos recibido una respuesta con valor verdadero(true) en la primera instrucción. |
Y esto se vería algo así en ejecución:

Vemos que funciona la lógica del one-liner en bash, si el puerto responde la cadena vacia enviada con echo entonces nos muestra el mensaje que esta abierto ya que el operador AND ha detectado que esa instruccion anterior fue correcta por lo que ejecutara la siguiente que es mostrar el aviso de que esta abierto, de lo contrario si no se cumple entonces pasará a el OR que nos imprime que el puerto esta cerrado.
Y ahora pasaremos esta misma lógica pero ahora en un script y englobando los 35535 puertos existentes.
Primero creamos un archivo bash en este caso lo llamaré scanner.sh y recuerda darle permisos de ejecución:
Vemos que ya lo hemos creado y ahora pasaremos a programar el script.
Primero haremos un test de como lo haremos:
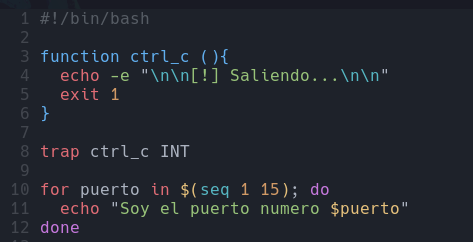
Primero definimos la función ctrl_c que sabemos que hace y como funciona, pero aquí lo nuevo es el for, que el for es un ciclo que se va a repetir una determinada cantidad de veces que le indiquemos, pero en este caso estamos usando un for que va a tomar como veces que se ve a repetir cada linea que hay en la ejecucion del comando a nivel de sistema: $(seq 1 15), recordemos que esto nos va a mostrar una lista en lineas separadas del 1 hasta el 15, así que este ciclo se va a repetir 15 veces, pero aparte de eso, nos va a guardar el valor de cada linea actual en la variable puerto, y nos va a mostrar el mensaje en pantalla del puerto actual gracias a la variable que almacena dicho puerto.
Por ejemplo en la primera ejecucion guardara el valor “1” en la variable puerto y nos va a mostrar en pantalla: “Soy el puerto numero 1”, y cuando se ejecute esto ahora se va a repetir pero ahora con el siguiente valor de la siguiente linea del comando seq, por lo que ahora tomara el “2”, y mostrara en pantalla “Soy el puerto numero 2”, y así irá con la cantidad de lineas restantes del comando ejecutado a nivel de sistema seq.
Y ahora lo que haremos es adaptarlo:
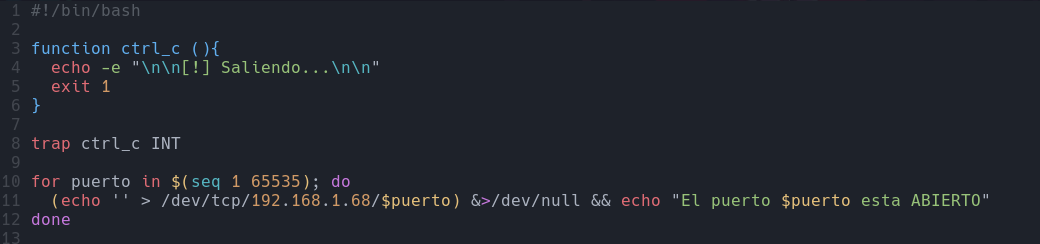
#!/bin/bash
function ctrl_c (){
echo -e "\n\n[!] Saliendo...\n\n"
exit 1
}
trap ctrl_c INT
for puerto in $(seq 1 65535); do
(echo '' > /dev/tcp/192.168.1.68/$puerto) &>/dev/null && echo "El puerto $puerto esta ABIERTO"
done
Lo que hicimos fue ahora si agregar la cantidad existente de puertos que son 65535 en el ciclo for.
Y ahora indicamos la instrucción que nos permite saber si el puerto esta abierto, y en este caso en el lugar donde va el puerto ponemos el valor de la variable puerto esto para que en cada iteracion vaya probando cada uno de los puertos, y en los casos que la instruccion ejecutada a nivel de sistema sea verdadera, quiere decir que el puerto esta abierto, entonces va a tomar el operador AND (&&) y mostrarnos en pantalla el puerto actual que esta abierto.
Este script en teoria funciona, pero como son muchas consultas las que debe hacer, haremos uso de threads (Hilos), para acelerar mucho más el proceso.
Y esto lo hacemos agregando al script lo siguiente:
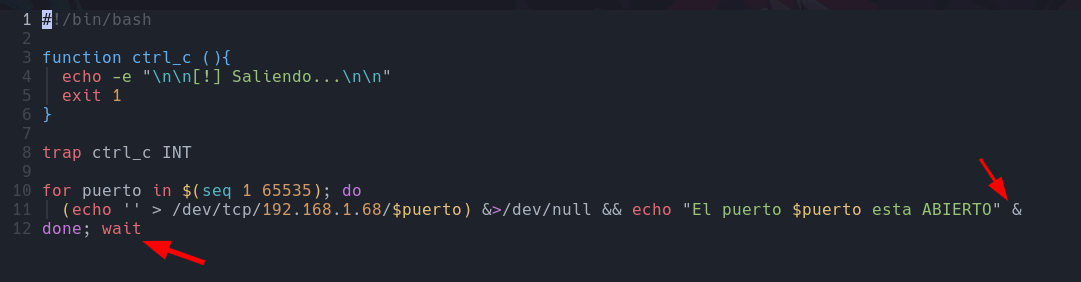
#!/bin/bash
function ctrl_c (){
echo -e "\n\n[!] Saliendo...\n\n"
exit 1
}
trap ctrl_c INT
for puerto in $(seq 1 65535); do
(echo '' > /dev/tcp/192.168.1.68/$puerto) &>/dev/null && echo "El puerto $puerto esta ABIERTO" &
done; wait
Esto lo que significa es que nos va a ejecutar multiples consultas a la vez, y de este modo va a ir mucho más rapido ya que una consulta no va a esperar a que una se ejecute para después seguir ella, lo que hace esto es que se lanzan multiples a la vez acelerando el proceso.

Y al ejecutar el script podemos ver que funciona correctamente y nos detecta que el puerto 22 esta abierto, no muestra más ya que en mi equipo solo tengo el puerto 22 abierto.
Ahora en este conexto, vamos a ejecutar este script pero en el nivel de bandit que nos dice que debemos enviar un valor a la red por el puerto que esta abierto pero no nos dicen cual solo que esta en el rango del puerto 31000 al 32000, y que debemos enviar la contraseña a dicho puerto para recibir la del siguiente nivel, y debemos hacerlo usando la encriptación SSL por lo que será con ncat, pero primero debemos saber que puertos estan abiertos y usaremos este scanner que hemos creado anteriormente para saberlo.
Así que una vez dentro del nivel, tenemos que crear el script, como no tenemos permiso de escritura en nuestro directorio personal, lo que haremos será crear un directorio temporal:
mktemp -d

Y nos ha dado una ruta donde esta el directorio temporal creado, así que iremos y aqui vamos a crer el script:

Y una vez esto vamos a copiar el script que creamos anteriormente:
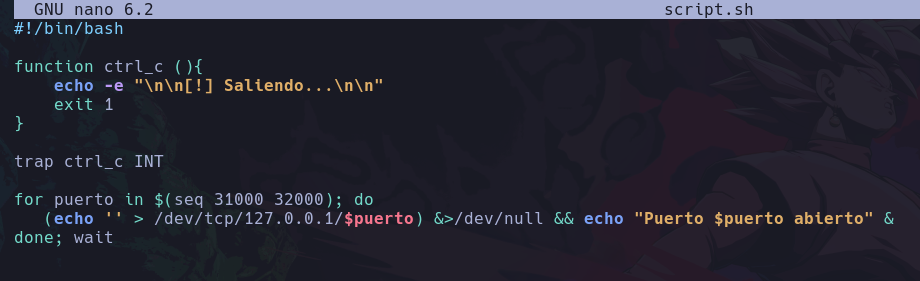
En el for la parte del seq es en el rango del puerto 31000 hasta el 32000 ya que esto nos lo indica el nivel, que el puerto que nos interesa se encuentra entre este rango.
Como queremos detectar los puertos abiertos de este mismo host usamos 127.0.0.1 que es lo mismo que localhost.
Y al ejecutarlo vemos los siguientes puertos abiertos:
Nos detecto 5 puertos abiertos:
- 31046
- 31518
- 31691
- 31790
- 31960
Y uno de estos debe ser el cual enviaremos una cadena y nos va a responder la contraseña del siguiente nivel.
Y después de intentar con cada puerto descubrimos que el 31790 es el que responde:
Vemos que recibimos una clave privada, así que creamos un archivo llamado id_rsa y metimos el contenido de la llave:
Recuerda darle los permisos 600 con chmod a esta llave id_rsa.
Y ahora la usaremos:
ssh -i id_rsa bandit17@localhost -p 2220

Recuerda que con el parametro -i de ssh indicamos la clave privada, después le indicamos como que usuario queremos ingresar así que suponemos que esta llave es para ingresar como el usuario bandit17, y accederemos a el servidor local, como estamos por ssh en el usuario bandit16 entonces el localhost en este contexto es bandit.labs.overthewire.org por eso solo indicamos localhost, o bien podriamos 127.0.0.1 que es el localhost en su valor ip.
Y al hacer esto obtenemos una conexión del siguiente nivel:

Recuerda que algunos niveles al llegar no es por medio de su flag, así que la sacamos manualmente de la ruta /etc/bandit_pass/bandit17 con cat.
Flag: VwOSWtCA7lRKkTfbr2IDh6awj9RNZM5e
Contenido extra: Creando un script para detectar que host estan en la red
Para saber si un host esta activo en la red podemos saberlo con un ping que esto envia un paquete icmp a el host y si hay respuesta quiere decir que esta activo ese host.
Recordamos que nuestra ip la podemos ver con hostname -I y es la primera:

“192.168.1.68” , Vemos que esta 192.168.1. y el 68, en este caso el numero final indica el equipo actual, el limite es 255 equipos , ahora haremos un ping a nuestro propio host:
Y vemos que el servidor en este caso nosotros mismos, responde al ping que hicimos, y se eviaron varios paquetes y en cada uno nos da detalles como el tiempo que tardo en responder, el ttl que luego veremos para que puede servirnos, etc.
Así que vemos que lanza varios paquetes pero solo queremos lanzar 1 ya que si responde quiere decir que ese host esta abierto.
así que podemos hacerlo usando:
ping -c 1 192.168.1.68
Y como esta ip este host esta activo en la red vemos que nos muestra que se envio 1 paquete y recibimos 1, por lo que hay conexión.
Y de lo contrario si ponemos un host que no esta activo:
Vemos que nos responde que se envio un paquete pero no recibimos una respuesta, por lo que ese host esta inactivo.
Y como al mandar un ping responde muy rapido pero cuando no hay tarda un par de segundos en mostrarnos error, así que si tarda más de 1 segundo indica que no hay conexión.
Así que podemos hacer lo siguiente:

timeout 1 bash -c "ping -c 1 192.168.1.68 &>/dev/null" && echo "[+] El host esta activo" || echo "[x] El host esta apagado"
Lo que hicimos fue agregar un limite de tiempo de 1 segundo usando timeout 1 y después la instrucción que le damos 1 segundo de ejecución es en bash y con el parametro -c indicamos dentro el ping que envia 1 paquete a una ip, y mandamos tanto el stderr como el stdin al /dev/null ya que no queremos ver eso en pantalla.
Y con el operador AND (&&) en caso de que la instrucción anterior sea exitosa osea que haya respondido al ping nos va a mostrar el mensaje en pantalla de que el host esta abierto, de lo contrario nos muestra que esta cerrado como se ve en la imagen con un host que no esta activo.
Así que ahora que ya entendimos esto, vamos a crear un script que por medio de un ciclo vaya ejecutando esto y que lo haga por cada ip diferente del ultimo digito de la ip.
Primero crearemos el script:
Y ahora vamos a empezar defindiendo la función ctrl c que ya conocemos y agregar el one liner adaptado:
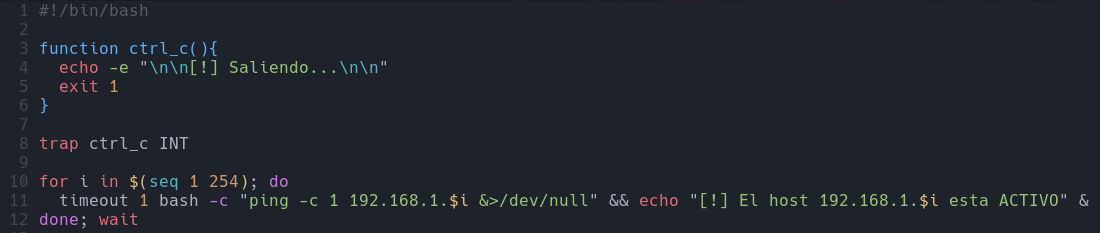
#!/bin/bash
function ctrl_c(){
echo -e "\n\n[!] Saliendo...\n\n"
exit 1
}
trap ctrl_c INT
for i in $(seq 1 254); do
timeout 1 bash -c "ping -c 1 192.168.1.$i &>/dev/null" && echo "[!] El host 192.168.1.$i esta ACTIVO" &
done; wait
Primero definimos la función ctrl + c, después iniciamos un bucle for que nos va a guardar en la variable “i” , el valor de la linea actual del output del comando ejecutado a nivel de sistema seq del 1 al 254, que establecemos este rango ya que el limite es 255 de hosts que pueden haber en el primer segmento de red.
Y en cada iteración lo que hará es con 1 segundo de limite ejecutar la instrucción en bash que envia un paquete ICMP a el host actual, ya que la ip queda igual y lo unico que cambia son los ultimos digitos que son los que van a ir iterando, derigimos errores y stdin al /dev/null, y en caso de ser exitoso vamos a mostrar el host actual que esta activo con un echo.
Y también usamos threads (hilos) en este script para que vaya mucho más rapido.
Y al ejecutar el script vemos lo siguiente:
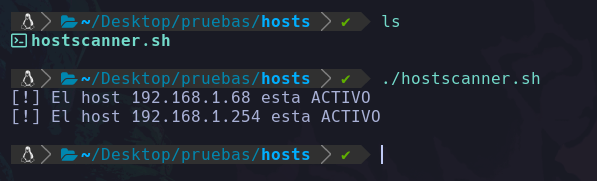
En este caso encontramos 2 host en la red que estan activos en este momento.
Y terminaremos este script de practica.
Bandit 17-18: Encontrar diferencias entre 2 archivos
En este nivel nos dice que existen 2 archivos uno llamado passwords.old y otro passwords.new, y que la contraseña del siguiente nivel es la única diferencia entre los 2 archivos:

Y vemos estos archivos, y para encontrar diferencias entre estos 2 archivos usaremos el comando diff:
Y podemos ver que nos muestra que se ha removido < el valor “glZreTEH1V3cGKL6g4conYqZqaEj0mte” y se ha agregado en su lugar el valor > “hga5tuuCLF6fFzUpnagiMN8ssu9LFrdg”.
Y como nos dice que el valor es el nuevo, entonces la contraseña es la del valor agregado.
Flag: hga5tuuCLF6fFzUpnagiMN8ssu9LFrdg
Bandit 18-19: Ejecutar comandos por medio de SSH
Al intentarnos conectar a bandit 18 ocurre lo siguiente:

Y al intentar entrar:
Vemos que nos expulsa automaticamente del SSH.
Y esto el nivel nos dice que sucede porque el .bashrc del sistema esta configurado para que cuando ingresemos nos expulsen automaticamente.
Intentaremos inyectar un comando que se ejecute antes de que nos expulsen agregandolo a el ssh:

vemos que lo hemos agregado al final y al dar enter:
Podemos ver que antes de que la conexión se cierre nos ha ejecutado el comando, esto es buena señal.
Ya que ahora en lugar de whoami, vamos a spawnear una bash:
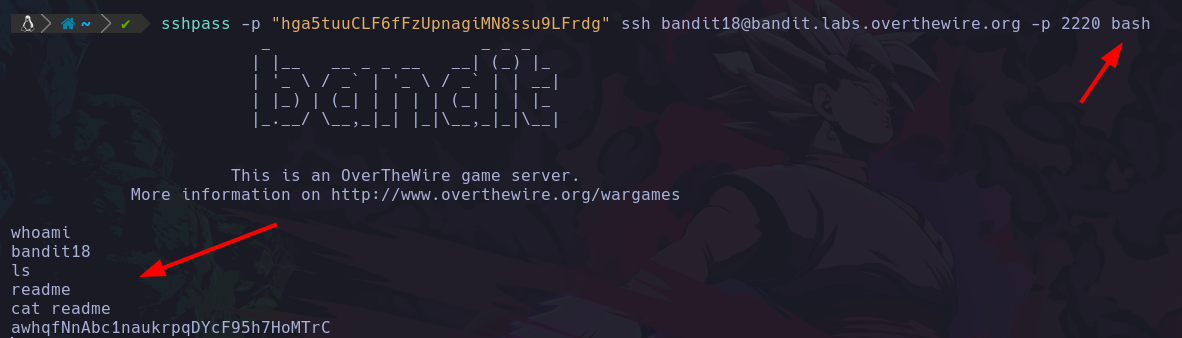
Y vemos que al ejecutar esto se quedo en espera, pero esto es porque la bash se invoco correctamente y podemos ejecutar comandos, en este caso encontramos un readme y al leer el contenido vemos la contraseña del siguiente nivel.
Flag: awhqfNnAbc1naukrpqDYcF95h7HoMTrC
Bandit 19-20: Abusando de un privilegio SUID para migrar de usuario
Ahora al entrar a este nivel, encontramos un archivo llamado bandit20-do, y al ver sus permisos vemos lo siguiente:
Podemos ver que este archivo tiene un permiso SUID, que como recordamos, este permiso permite que el que lo ejecute pueda ejecutar el binario en el contexto del usuario propietario de este archivo, en este caso se ejecutará en el contexto de bandit20 ya que el es el propietario.
Y al ejecutar este binario nos dice lo siguiente:

Este binario nos dice que podemos ejecutar comandos como otro usuario, osea bandit20, así que le pasaremos como parametro de entrada el comando bash para que nos de una bash como bandit20:

Vemos que ejecutamos el comando pero le agregamos un parametro -p, este parametro nos permite poder atender al SUID y obtener la bash como el bandit20, si no ponemos este parametro, por seguridad no nos va a dejar migrar al usuario 20, así que debemos asignarlo.
También podemos spawnear una sh o alguna otra terminal en caso de que este instalada.

Y podemos leer la flag del siguiente nivel que aunque ya tenemos una bash como bandit20 igual pondré la flag:
Flag: VxCazJaVykI6W36BkBU0mJTCM8rR95XT
Bandit 20-21: Entablando conexion con un puerto en escucha usando netcat
Este nivel nos dice que hay un binario el cuál al ejecutarlo nos pide un puerto como argumento, y lo que hará este binario es enviar una petición a ese puerto, y en esa petición si se pone la contraseña del nivel actual entoces recibiremos la del siguiente nivel.
Así que primero entraremos y vemos el binario:
Podemos ver que ejecutamos el binario y le dimos como argumento el puerto 80 pero como no esta abierto nos da error.
Así que usando netcat vamos a abrir un puerto y dejarlo en escucha, para ello abriremos otra terminal igual conectada por ssh a este nivel:
Vemos que abajo hemos abierto otra sesión de ssh hacía este mismo nivel.
Esto lo hacemos para que en una terminal abramos el puerto y lo dejemos en escucha en espera de algo, esto lo haremos con:
nc -nlvp 4040
Vemos que al abrir el puerto 4040 con netcat, se queda en espera de una conexión.
El -n del comando de netcat indica que no aplique resolución DNS, esto para evitar lentitud, el -l es para dejar en escucha ese puerto (listening), el parametro -v es para verbose que indica que veamos en pantalla lo que va sucediendo a tiempo real, y la -p es para indicar el puerto, en este caso el 4040.
Y ahora que ya tengamos abierto el puerto en el localhost del nivel actual, con la otra terminal ejecutaremos el binario y le pasaremos como argumento el puerto que hemos abierto:
Podemos ver que ha llegado una conexión hacía el puerto que dejamos en escucha, así que ahora que tenemos la conexión con netcat, pasaremos la password del nivel actual y en teoria recibiremos la del siguiente nivel:
Vemos que hemos enviado la contraseña del nivel actual y recibimos como respuesta la del siguiente nivel.
Por lo que hemos logrado este nivel.
Si pones en escucha puertos inferiores a el puerto 1024 te pedira permisos root, por lo que intenta siempre poner en escucha puertos arriba del puerto 1024.
Flag: NvEJF7oVjkddltPSrdKEFOllh9V1IBcq
Bandit 21-22: Tareas Cron
¿Qué es una tarea cron?
Cron es un servicio que utiliza linux para ejecutar ciertas instrucciones en cada cierto tiempo.
Por ejemplo, podemos tener una tarea cron que ejecute cierto comando a cada hora de cada dia por ejemplo.
Lectura de las tareas cron
Podemos ver en la siguiente imagen la sintaxis de las tareas cron:
Por ejemplo, en la tarea cron de la imagen se va a ejecutar tiene la siguiente sintaxis:
55 23 * * 0 root comando
Se va a ejecutar un comando como el usuario root, a las 23:55, de cada dia de cada mes, pero solamente los dias que sean domingos.
El asterisco indica todo sobre ese valor, por ejemplo vemos que hay 2 asteriscos en el valor del dia de mes y mes, por lo que se ejecutara todo el año ya que estamos indicando que cada dia del mes, y como indicamos todos los meses será todo el año.
Recuerda que el primer valor es el minuto, seguido de la hora, después el dia del mes, y el mes, y al final el dia de la semana.
Por ejemplo en este otro:
* 14 15 9 5 root apt update && parrot-upgrade
Lo que hará es que cada minuto de cuando sean las 14 horas, de cada 15 de septiembre que caiga en el dia 5 de la semana que es viernes, entonces va a ejecutar las instrucciones que es actualizar el sistema.
Si el 15 de septiembre no cae en viernes entonces no se va a ejecutar.
Veamos otro ejemplo:
15 21 * 1 * root comando
En este, a el minuto 15 de las 21 horas, de todos los dias del mes de enero y como pusimos un asterisco en el dia de la semana entonces será en todos los dias de la semana de enero, va a ejecutar un comando como root.
Tarea cron con valores de paso
Ahora si queremos que una tarea cron se ejecute cada algo, podemos usar el valor “/” de este modo:
*/5 14 * * * root comando
Esto lo que hará es que cada 5 minutos de las 14 se ejecutará algo, osea ahora con el / le estamos indicando que cada cuando, ya no que a ese valor especifico, ya que sin el / le estariamos diciendo que nos ejecute algo a el minuto 5 de las 14 horas, pero como le pusimos el guion, significa que cada 5 minutos mientras sean las 14 horas va a ejecutarse algo todos los dias del mes cada mes y cada dia de la semana.
Otro ejemplo:
* */2 * 12 1 root comando
Esto va a ejecutar en todos los minutos(59), de cada 2 horas del mes de diciembre los dias que sean lunes, ejecutará algo. lógicamente cuando deje de ser lunes dejará de ejecutar esto.
Así que cuando pasen 2 horas va a ejecutar la tarea durante todos los minutos que son 59, y después de esto al pasar estos minutos esperara 2 horas para volver a hacer lo mismo, obviamente solamente en el mes de diciembre los dias lunes.
Web para practicar tareas cron
Ahora que entendimos la sintaxis de las tareas cron vamos a el nivel de bandit, que nos dice que atraves de una tarea cron descubriremos la contraseña.
La ruta donde estan las tareas cron por defecto es /etc/cron.d/ así que al ir a esa ruta encontramos lo siguiente:

encontramos todas estas tareas cron, nos llama la atencion la que se llama “cronjob_bandit22” ya que ese es el usuario al que queremos migrar.
Y al hacer un ls -l:
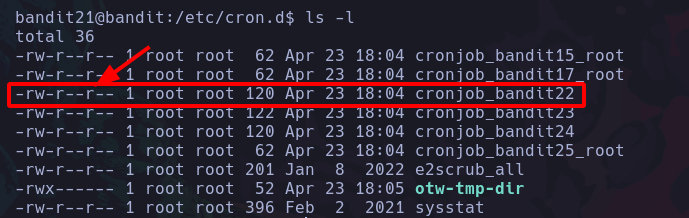
Podemos ver que tenemos permiso de lectura a ese archivo, por lo que leeremos esa tarea cron para ver que es lo que hace:

Podemos ver que lo que hace esta tarea es que al iniciar por primera vez el equipo se ejecuta algo, por esto se usa @reboot, lo que indica que se ejecute algo cada que el equipo se encienda.
Y también ejecuta lo mismo en la siguiente linea:
* * * * * bandit22 /usr/bin/cronjob_bandit22.sh &> /dev/null
Pero esta vez ejecuta algo cada minuto de cada hora de cada dia de cada mes de cada semana, lo que hará es ejecutar como el usuario bandit22, un script el cual esta en la ruta “/usr/bin/cronjob_bandit22.sh”.
Así que veremos que contiene ese script que se ejecuta:

Vemos que este script de bash, lo que hace es asignar el permiso 644 a el archivo t7O6lds9S0RqQh9aMcz6ShpAoZKF7fgv que esta dentro de la ruta /tmp/.
Y luego en la siguiente linea lo que hace es hacerle un cat a la contraseña de bandit22, y redirige el output a este mismo archivo anterior.
Y como el permiso 644 es:
-rw-r–r–

Podemos ver que tenemos permiso de lectura, así que vamos a leer ese archivo:

Y vemos que ya hemos conseguido la flag del nivel 22.
Flag: WdDozAdTM2z9DiFEQ2mGlwngMfj4EZff
Bandit 22-23: Abusando de una tarea cron para seguir la password
En este nivel nos dice que también trataremos con una tarea cron, por lo que al entrar iremos a la ruta donde se almacenan las tareas cron /etc/cron.d/ y veremos lo que hay:

Vemos que estan todas estas tareas cron, como el siguiente nivel es el 23, nos llama la atención esa tarea, por lo que vemos que tenemos permisos de lectura y la leeremos:

Y podemos ver que esta tarea cron nos esta ejecutando en cada que se inicia el sistema y después cada minuto, un script que se aloja en la ruta “/usr/bin/cronjob_bandit23.sh” este script es ejecutado por el usuario bandit23, que es el que nos interesa migrar.

Como vemos este script pertenece al grupo bandit22 el usuario que estamos actualmente, por lo que tenemos permiso de lectura y ejecución.
Primero leeremos lo que contiene:
Vemos que contiene este pequeño script en bash:
#!/bin/bash
myname=$(whoami)
mytarget=$(echo I am user $myname | md5sum | cut -d ' ' -f 1)
echo "Copying passwordfile /etc/bandit_pass/$myname to /tmp/$mytarget"
cat /etc/bandit_pass/$myname > /tmp/$mytarget
Lo que esta haciendo esto es que primero guarda en una variable llamada “myname” el output del comando whoami, como este script se ejecutará como bandit23 entonces el whoami almacenará bandit23.
Después en otra variable llamada “mytarget” guarda el oputput de un comando ejecutado a nivel de sistema, este comando es un echo el cual imprime la palabra “I am user $myname” como el valor de esa variable es bandit23 entonces dirá “I am user bandit23”.
Pero también vemos que se usa un pipe para usar md5sum, y veamos un ejemplo de md5sum y que es, por ejemplo tengo el texto:

Lo que hace es mostrarnos un valor hash, que por medio de este valor podremos saber si algo ha sido modificado, si por ejemplo tienes un archivo y le haces un md5sum pero luego es modificado y le haces un md5sum este hash ya no será el mismo y te podrás dar cuenta que ha sido aletrado.
Y con el otro pipe de cut simplemente se estaba quedando con el primer argumento así:

Esto es para que se almaecene el hash sin el guion que salia antes de hacerlo sin cut.
Ahora que entendimos esto, vemos que al final del script ejecuta 2 ultimas lineas, la primera es:
echo "Copying passwordfile /etc/bandit_pass/$myname to /tmp/$mytarget"
Que lo que hace es mostrar en pantalla que esta copiando el valor del archivo /etc/bandit_pass/$myname como la variable myname es bandit23 entonces se leerá como /etc/bandit_pass/bandit23 y también muestra otro mensaje que es to /tmp/$mytarget, y como ya sabemos que la variable de mytarget almacena un hash entonces sabemos que es.
Y por último en la ultima linea nos dice cat /etc/bandit_pass/$myname > /tmp/$mytarget, esto esta haciendo un cat del archivo de contraseña donde se almacenan en este caso será de bandit23, y redigira la salida del cat a la ruta /tmp/$mytarget , y como el target descubrimos que es “8ca319486bfbbc3663ea0fbe81326349”, gracias a que copiamos las instrucciones en nuestra terminal.
entonces sabemos que en /tmp/ hay un archivo con el nombre del hash que contiene la contraseña del siguiente nivel.

Vemos que hemos encontrado el archivo, y tenemos permisos de lectura, por lo que leeremos la contraseña:

Flag: QYw0Y2aiA672PsMmh9puTQuhoz8SyR2G
Bandit 23-24: Abusando de una tarea cron con seguimiento de script
En este nivel es similar, vamos a la ruta de /etc/cron.d y vemos los siguientes archivos:

Como el siguiente nivel es el bandit24, leeremos su tarea cron:

Nuevamente vemos que ejecuta en cada inicio del sistema y cada minuto ejecuta el script como el usuario bandit24 que se aloja en la ruta “/usr/bin/cronjob_bandit24.sh”.
Veamos lo que contiene este script:
#!/bin/bash
myname=$(whoami)
cd /var/spool/$myname/foo || exit 1
echo "Executing and deleting all scripts in /var/spool/$myname/foo:"
for i in * .*;
do
if [ "$i" != "." -a "$i" != ".." ];
then
echo "Handling $i"
owner="$(stat --format "%U" ./$i)"
if [ "${owner}" = "bandit23" ]; then
timeout -s 9 60 ./$i
fi
rm -rf ./$i
fi
done
Primero almacena el output del comando whoami, lo almacena en la bariable “myname”, en este caso como es bandit24 quien ejecuta el script ya que así esta en la tarea cron entonces se almacenará el valor “bandit24” en la variable myname.
Después vamos a la ruta “/var/spool/$myname/foo” recuerda que $myname es bandit24 así que el script nos posiciona en la ruta “/var/spool/bandit24/foo”, y en caso de que no exista la ruta sale del script, en caso de que la ruta exista entonces no saldra y seguira con la ejecución del script, mostrará el mensaje en pantalla “Executing and deleting all scripts in /var/spool/$myname/foo:”. que significa que va a ejecutar y borrar todos los archivos dentro de la ruta “/var/spool/bandit24/foo”.
Ahora crea un bucle for, que es el siguiente: for i in * .*; esto lo que hace es que por cada variable i, se utiliza para almacenar cada elemento de la lista que se está iterando, en este caso la lista por la cual vamos a recorrer elementos es la que le indicamos con “in”, que primero es un asterisco * que engloba todos los archivos del directorio actual en el que estamos, y también de los archivos ocultos .* recuerda que los ocultos inician con un punto por lo cual también los contemplamos.
Y ahora por cada archivo en la lista lo que hará es lo siguiente: if [ "$i" != "." -a "$i" != ".." ]; comprobará si el elemento actual de la lista, recuerda que se almacena en la variable “i”, va a comprobar si el nombre del archivo actual es diferente a un “.” y también si es diferente a un “..”, el parametro -a indica un && en bash, y el operador != indica que no sea igual a algo, entonces si el archivo actual no tiene de nombre “.” ni “..”, entonces lo que hará es entrar a el if y ejecutar lo siguiente:
echo "Handling $i"
owner="$(stat --format "%U" ./$i)"
if [ "${owner}" = "bandit23" ]; then
timeout -s 9 60 ./$i
fi
rm -rf ./$i
Primero mostrará en pantalla el mensaje “Handling $i” recuerda que la variable “i” almacena el nombre del archivo actual.
Y después crea una variable llamada owner, la cuál almacenará el output de un comando ejecutado a nivel de sistema en forma de cadena(string), por eso esta entre comillas dobles, y lo que hace la ejecución de ese comando: stat --format "%U" ./$i simplemente es obtener el nombre del propietario de este archivo actual, usando la herramienta stat y filtrando por el usuario del archivo actual, algo que así por ejemplo:

Podemos ver que hace lo que habiamos dicho.
Así que en el script, almacena el nombre del propietario del archivo actual en la variable owner, después hace un if:
if [ "${owner}" = "bandit23" ]; then
Si el valor de la variable owner, es igual a bandit23 osea nuestro usuario en este nivel, entones entrará a el if y ejecutará sus instrucciones, que en este caso es esto: timeout -s 9 60 ./$i que esto lo que hace es ejecutar el archivo actual en un intervalo de tiempo. el parametro -s 9 indica que si después de 60 segundos no se completa la ejecucion del archivo actual, entonces se va a cancelar la ejecucion.
Y por último al salir de if, va a borrar el archivo actual: rm -rf ./$i.
Y esto se va a repetir con cada archivo que este en la lista del directorio actual que agregamos con el for in.
Así que si ya sabemos como funciona el script, vamos a abusar de que sabemos como funciona para intentar obtener la contraseña del siguiente nivel.
Creando un script ejecutado por la tarea cron de bandit24 para obtener su password
Como sabemos que la tarea cron anterior ejecuta el script mostrado anteriormente como el usuario bandit24, entonces intentaremos algo.

Podemos ver que el directorio foo al cual nos lleva el script anterior, tenemos permisos de escritura y ejecucion, como no tenemos lectura no podremos ver lo que hay dentro de ese directorio, pero si crear archivos y ejecutarlos.
Primero crearemos un directorio temporal para crearnos un script, y el objetivo es que este script envie la password de bandit24 a una ruta a la que si tengamos permiso de lectura, y como en la ruta foo se ejecuta cada archivo que hay ahí gracias a la tarea cron, entonces aprovecharemos esto.
Primero crearemos el directorio temporal:

Y vemos que le damos permisos a el directorio temporal que hemos creado, estos permisos permiten a otros escribir y atravesar el directorio que recien creamos, esto para que cuando el usuario bandit24 ejecute el script con la tarea cron, pueda tener permiso de atravesar este directorio para escribir la contraseña que le indicaremos en el script que crearemos.
Una vez dentro del directorio temporal, vamos a crear el script:

Cuando usamos chmod sin asignarle especificamente a que conjunto queremos asignarle el permiso, por defecto se les asigna a todos, tanto a propietario, grupos y otros. ya que no estamos indicandole uno en especifico y solo ponemos +x.
Ahora vamos a escribir el script:

Como el usuario bandit24 va a ejecutar este script gracias a la tarea cron, entonces va a poder leer la password que se almacena en la ruta de las contraseñas, y redirigiremos la salida del cat de esa password a nuestro directorio temporal y la va a meter a un archivo que se llamará password.txt.
Una vez tenemos el script creado, vamos a enviar una copia del script, a la ruta donde se ejecutan todos los scripts de esa ruta gracias al script de la tarea cron:

Vemos que hemos copiado el script a esa ruta, y solo toca esperar a que pase 1 minuto ya que ese es el intervalo de tiempo en el que se ejecuta la tarea cron y la tarea cron ejecuta el script que ejecuta todos los elementos de esa ruta.
Y esperando un minuto vemos que se ha creado el archivo password.txt:

Y vemos que ha funcionado lo que hemos planeado, así que tenemos la contraseña del siguiente nivel.
Flag: VAfGXJ1PBSsPSnvsjI8p759leLZ9GGar
Bandit 24-25: Aplicando fuerza bruta a una conexion por netcat hacia un puerto
Este nivel nos dice que existe un demonio corriendo en el puerto 30002, un demonio es un proceso del sistema que se ejeecuta en segundo plano, y nos dice que este va a responder con la contraseña de bandit25 siempre y cuando se le pase la contraseña del bandit actual osea bandit24 y también un pin de 4 digitos que no sabemos cual es pero nos dicen que se encuentra en el rango de 0000 hasta 9999 y que el pin esta en uno de esos rangos.
Primero haremos la prueba para ver que necesita un pin:
nc localhost 30002

Vemos que entablamos una conexión con ese puerto y nos salta el mensaje: “I am the pincode checker for user bandit25. Please enter the password for user bandit24 and the secret pincode on a single line, separated by a space.” nos dice que debemos introducir la contraseña del usuario actual y el pin separado de un espacio.
Y como vemos en la imagen eso hicimos pero obviamente el pin no es 1234.
Una manera más rapida de entablar la conexión y no tener que esperar a meter los datos podemos hacerlo con un echo:
echo "VAfGXJ1PBSsPSnvsjI8p759leLZ9GGar 1234" | nc localhost 30002

Podemos ver que de esta forma se toma la salida del output del echo como input para el siguiente comando con netcat.
Así que lo que haremos ahora será lo siguiente:
for pin in $(seq 0000 9999); do echo "VAfGXJ1PBSsPSnvsjI8p759leLZ9GGar $pin"; done
Con esto vamos a imprimir toda la secuencia desde 0 hasta 9999 en orden con la contraseña también. y se verá algo así:

Y vemos que con el for nos ha imprimido en pantalla la password seguido del valor del pin actual.
Ahora lo que haremos será meter todo esto en un archivo de texto:

Vemos que redigiremos la salida del bucle for hacía un archivo .txt, debemos estar en un directorio temporal para poder escribir en la ruta y crear el archivo.
Una vez tengamos el archivo con los pines en secuencia, lo que haremos será listar con cat la lista de pines y con netcat que pruebe cada intento dado:
cat pines.txt | nc localhost 30002
Pero al ver esto vemos que nos responde todos los errores y nosotros no queremos ver esto, por lo que vamos a filtrar para remover lo que no nos interesa, en este caso no queremos que nos muestre las lineas que digan la palabra “Wrong!”, así que usando awk agregaremos un filtro para que no nos muestre esta palabra, y para ello usamos el parametro -v:
cat pines.txt | nc localhost 30002 | grep -v "Wrong"

Ahora vemos que nos ha dejado de mostrar ya que con el parametro -v indicamos que NO nos muestre lo que contenga ciertas palabras, pero ahora tampoco queremos que nos muestre el primer mensaje que se ve arriba, por lo que lo eliminaremos igual con el grep -v.
| Pero para no hacer otro pipe de grep, podemos agregar el parametro -E para indicar que serán multiples cosas que queremos filtrar para que no nos muestre, y hacemos la separacion con un simbolo de “ | ”: |
cat pines.txt | nc localhost 30002 | grep -vE "Wrong|Please enter"
![]()
Le indicamos que tampoco queremos que nos muestre lo que contenga la palabra “Please enter”. y solo toca esperar la respuesta del demonio y deberiamos recibir la flag:

Si tuviste problemas al hacer este nivel, prueba a probar en 2 partes, por ejemplo en lugar de que el archivo llegue del 0000 hasta el 9999 prueba que llegue del 0000 hasta el 5555 luego intenta y si no esta en ese rango entonces vuelve a intentar pero ahora desde el 5555 hasta el 9999, esto es para dividir el trabajo y el servidor no responda mal ya que es muy probable que falle al poner tantas peticiones de una sola ejecucion y el servidor se sature.
Flag: p7TaowMYrmu23Ol8hiZh9UvD0O9hpx8d
Bandit 25-26: Escapando del contexto de un comando
Ahora este nivel nos dice que al ingresar a el bandit 26 desde bandit25, ya que solo podemos acceder por medio de la llave privada que nos dejan en bandit25 pero al conectarnos sucede lo siguiente:

Y vemos que al intentar entrar nos saca:
Nos expulsa del ssh.
Pero esta vez ya no podemos inyectar comandos:
Y vemos que se queda congelado y no nos responde nada.
Esto es a que este nivel no usa una bash como terminal, usa esto:

Usa algo llamado “showtext”, que no es una bash ni alguna terminal útil.
Y al leer lo que contiene ese valor vemos lo siguiente:
Vemos que nos inicia un script de shell, el cual cambia el valor de la variable de entorno TERM y la cambia por linux.
Y después ejecuta un archivo llamado text.txt que esta en el directorio personal de bandit26.
Y por último sale.
Lo que hace el comando more es como un cat pero en proporciones, nos muestra algo que se esta leyendo pero si la pantalla no esta completa te dará opcion para deslizar, pero esto es algo que nos servira.
Primero haremos la ventana pequeña antes de conectarnos nuevamente por ssh y ser expulsados:

Una vez tenemos la ventana más pequeña de la terminal, lo que haremos será volver a conectarnos por ssh a el siguiente nivel:

Y vemos que no nos expulsa aún ya que aún se esta ejecutando el more ya que nos esta mostrando primero el banner en letras grandes que dice BANDIT26, recuerda que more es como el cat, y vemos que nos muestra 33% del contenido, por lo que si damos para abajo ira aumentando, pero a nosotros nos interesa quedarnos estaticos aquí.
Ya que more tiene un modo visual, que al pulsar la tecla “v” se activará, y una vez hayamos entrado al modo visual, vamos a pulsar la tecla esc y luego shift + : y se nos abrira este modo:

Aquí vamos a crear una variable llamada shell, la cual valdra /bin/bash:
set shell=/bin/bash

Y al dar enter habremos creado la variable shell, la cual contiene el valor de una bash.
Y ahora que dimos enter, pulsaremos esc y luego shift + : y escribiremos “shell” y daremos enter, esto lo que hará es llamar a la variable que creamos y nos spawneara una bash:

Y vemos que ya tenemos una bash como bandit26.
Bandit 26-27: Abusando de un binario suid
Ahora como entramos aquí a este nivel por medio del bandit anterior ya que no hay una bash así que obtener la contraseña de este nivel será inutil por lo que obtendremos la del siguiente nivel.
Vemos que en el inicio hay un binario con permiso suid:

Y vemos que nos permite ejecutar comandos como el usuario bandit27 como vemos en el whoami ejecutado.
Así que simplemente haremos un cat de la contraseña de bandit27:

Y ya hemos sacado la password del siguiente nivel.
Flag: YnQpBuifNMas1hcUFk70ZmqkhUU2EuaS
Bandit 27-28: Clonar repositorios desde git
Git es una herramienta que funciona para el manejo de repositorios y de versiones, puedes tener un proyecto en git y manejar mucho más rapido ciertas cosas.
En este nivel nos dice que debemos bajar un repositorio que se encuentra alojado en la misma maquina local.
Y que la ruta donde se aloja el archivo git esta en: “ssh://bandit27-git@localhost/home/bandit27-git/” por el puerto 2220.
Así que usando git clone vamos a clonar un repositorio, en este caso esa ruta del git:
Primero iremos a un directorio temporal ya que vamos a descargar algo del servidor. así que una vez en la ruta temporal, vamos a clonar el repositorio:
git clone ssh://bandit27-git@localhost:2220/home/bandit27-git/repo
Le estamos indicando que vamos a clonar un repositorio de git y la ruta de este repositorio se encuentra en la conexión dada por el puerto 2220.
Nos pedirá la contraseña del servicio ssh del cual obtiene el recurso y en este caso es la misma que la que ingresamos al nivel actual.
Y vemos que nos dejo un directorio con un archivo llamado README:
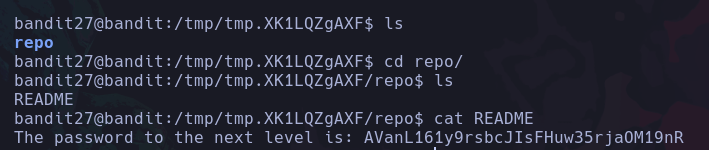
El cual al leerlo vemos que contiene la contraseña del siguiente nivel.
Flag: AVanL161y9rsbcJIsFHuw35rjaOM19nR
Bandit 28-29: Descubriendo cambios en el repositorio por medio de logs de commits
Un commit en git es un cambio en el repositorio que hubo y ahora es otra versión ya que ha sido modificada, pero estos cambios suelen guardarse en un registro.
En este nivel igual nos pidio clonar un repositorio desde “ssh://bandit28-git@localhost:2220/home/bandit28-git/repo” por el puerto 2220, así que lo hicimos, y ahora nos dejo el siguiente archivo:
git clone ssh://bandit28-git@localhost:2220/home/bandit28-git/repo
Vemos que nos dejo un directorio llamado repo y dentro de el encontramos lo siguiente:
Encontramos este archivo que contiene un nombre de usuario y la contraseña tapada, pero veremos el registro de logs para ver si en alguna versión anterior esta contraseña no estaba cubierta usando:
git log -p
Esto nos permite ver los registros de cambios:
Y podemos ver que estaba la contarseña anteriormente así que hemos obtenido la flag del siguiente nivel.
Flag: tQKvmcwNYcFS6vmPHIUSI3ShmsrQZK8S
Bandit 29-30: ramas de un repositorio en git
Nuevamente nos piden clonar un repositorio y encontramos lo siguiente:
Y vemos que hay un archivo nuevamente como el nivel anterior, así que miraremos los registros con git log -p:
Pero ahora no vemos nada interesante, así que pasaremos a ver en que rama del repositorio estamos con:
git branch

Vemos que estamos en la rama “Master”, veremos que otras hay con:
git branch -r

Y vemos que hay otras rutas, para viajar a alguna otra como por ejemplo dev, hacemos lo siguiente:
git checkout dev

Y vemos que hemos cambiado de rama satisfactoriamente, y aquí encontramos el mismo archivo pero aquí si esta la password:
Y hemos completado este nivel.
Flag: xbhV3HpNGlTIdnjUrdAlPzc2L6y9EOnS
Bandit 30-31: tags en git
En este nivel nuevamente nos piden clonar un repositorio y al hacerlo encontramos lo siguiente:
Nos da un archivo pero al leerlo solo hay un mensaje pero no hay ninguna contraseña, ni en logs, ni en branchs.
Vemos 2 directorios de branch pero los 2 es en el mismo que estamos actualmente y entonces no hay nada mas de esto.
Algo que podriamos ver en git son las etiquetas con:
git tag

Y para leer el contenido de esta etiqueta usamos:
git show secret

Y encontramos la password del siguiente nivel gracias a esta etiqueta.
Flag: OoffzGDlzhAlerFJ2cAiz1D41JW1Mhmt
Bandit 31-32: Subiendo un cambio del repositorio con git
Nuevamente clonamos un repositorio en este nivel y encontramos lo siguiente:
Y nos dice el archivo que debemos hacer un cambio agregando un archivo llamado key.txt, que contenga el texto “May I come in?” y que el branch sea Master.
Primero comprobamos que estamos en master:

Vemos que lo estamos, ahora crearemos el key.txt y le meteremos el contenido:

Vemos que hemos creado lo que nos piden, ahora para subir un cambio haremos lo siguiente:
git add key.txt key.txt es el cambio que queremos subir:

Nos dice que no se puede subir ya que en git cuando hay un archivo oculto llamado .gitignore esto va a ignorar los archivos que le digamos, vemos el contenido de .gitignore:
Podemos ver que el archivo ignorara todos los que sean .txt, por lo que como tenemos permiso de escritura vamos a eliminarlo, e intentar nuevamente subir el key.txt:

Vemos que ahora no nos arrojo error, por lo que se agrego correctamente y ahora toca ponerle un nombre a ese cambio con:
git commit -m "agregamos un txt"

Vemos que se ha guardado correctamente, ahora subiremos este cambio a origin master con:
git push origin master
Y vemos que hemos hecho esto de forma correcta y recibimos la contraseña del siguiente nivel.
Flag: rmCBvG56y58BXzv98yZGdO7ATVL5dW8y
Bandit 32-33: Escapando de una shell trampa
En este nivel al entrar nos da una shell extraña que nos convierte todo a mayusculas y no podemos hacer nada:
Y vemos que no podemos ejecutar nada, pero recordemos algo:
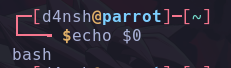
Podemos ver el valor de la shell en uso leyendola con echo $0, pero no solo esto ya que si ponemos solo el $0 sin el echo entonces le estamos indicando que nos spawnee una bash, así que haremos esto en el nivel:

Y sacamos la flag de bandit33:

Y vemos que hemos logrado spawnear una bash, y hemos terminado este nivel y todos los retos que hay por ahora de overthewire.
Scripting en Bash - buscador de maquinas en hack the box (script de s4vitar)
Finalmente hemos llegado a el scripting en bash, donde practicaremos todo lo aprendido en un proyecto en bash.
En este caso vamos a crear un buscador de información de maquinas en hack the box.
Todo esto para practicar, y lo que hará este script es filtrarnos información de determinadas maquinas, ya sea filtrar maquinas por dificultad, nombre, etc.
Creando la funcion de salida
Vamos a iniciar y separar por partes el script para que se entienda mejor.
Primero crearemos un archivo .sh donde vamos a escribir nuestro código, obviamente también le damos permisos de ejecución:

Una vez creado, empezaremos agregando las primeras lineas, primero nos interesa una manera de salir del script por cualquier motivo como vimos en scripts anteriores, así que primero crearemos la función que al capturar la combinación de teclas “ctrl + c” esta detenga el programa:
#!/bin/bash
#Colores
greenColour="\e[0;32m\033[1m"
endColour="\033[0m\e[0m"
redColour="\e[0;31m\033[1m"
blueColour="\e[0;34m\033[1m"
yellowColour="\e[0;33m\033[1m"
purpleColour="\e[0;35m\033[1m"
turquoiseColour="\e[0;36m\033[1m"
grayColour="\e[0;37m\033[1m"
function ctrl_c(){
echo -e "\n${redColour}[!] Saliendo del script...${endColour}\n"
exit 1
}
#Ctrl+c
trap ctrl_c INT
Vemos que igual agregamos colores, y en la función ctrl_c lo que hará es que cuando se presione ctrl + c, se va a ejecutar esa función y mostrara un mensaje en pantalla de que esta saliendo del script y finalmente hacemos un exit 1, que indica una salida no exitosa.
Obtener datos de las maquinas
Ahora lo que ocupamos primero es obtener los datos de todas las maquinas, para ello usaremos una web de s4vitar que es la siguiente: HtbMachines:
Ahora lo que haremos será obtener los datos que se muestran en la web y almacenarlos en un archivo para tratarlo.
Primero vamos a obtener una captura de esos datos, para ello usaremos la herramienta curl:
curl -s -X GET https://htbmachines.github.io/
Estamos haciendo una petición en modo silent -s (para no ver output de curl), y por el metodo GET usando el parametro -X. Y esta petición se tramita a la web mencionada anteriormente.
Y en la respuesta vemos:
vemos que aquí no estan las maquinas ya que es muy poca información y no vemos ninguna maquina, pero vemos en el recuadro que se esta obteniendo un recurso javascript de la misma web, así que haremos la petición a ese recurso ya que ahí se alojan las maquinas:
curl -s -X GET https://htbmachines.github.io/bundle.js
Vemos demasiados datos de javascript, y todo esta junto y no podemos ver bien, por lo que usaremos la herramienta js-beautify y para instalarla debemos ejecutar:
apt-get install jsbeautifier
Una vez la tengamos, agregaremos con un pipe esa herramienta a la petición de curl y vemos que ahora se ve mejor:
curl -s -X GET https://htbmachines.github.io/bundle.js | js-beautify
Vemos que ya tiene un mejor formato, y ahora podemos trabajar con esto.
Ahora este output lo queremos en un archivo, así que redirigiremos el output a un archivo llamado “bundle.js”:
curl -s -X GET https://htbmachines.github.io/bundle.js > bundle.js
Y ya tendriamos el archivo en nuestra ruta actual:

Esto lo hacemos para evitar que cada que ocupemos tratar la información de las maquinas no hacerle tantas peticiones a la web ya que esto realentizaria el script, así que es mejor tener los datos de las maquinas en un archivo y tratarlo.
Y vemos que el archivo esta en este formato:
Vemos que nuevamente esta todo amontonado, así que lo que haremos será aplicarle el formato de js-beautify y volver a guardar el archivo en si mismo, pero hay que tener cuidado, ya que no se debe hacer así:

Ya que nos arrojará un error y al leer el archivo este se habrá quedado vacío:
![]()
Vemos que no hay nada ya que lo anterior ha provocado esto, así que tendriamos que crear nuevamente el bundle.js con curl y eso, pero para evitar este error, podemos usar la herramienta sponge, que se instala con sudo apt install moreutils.
Y volveremos a intentar lo anterior pero ahora usando la herramienta sponge:
cat bundle.js | js-beautify | sponge bundle.js
Y ahora podemos ver que así si pudimos guardar algo de ese mismo archivo en si mismo:
Y que ahora si se mantiene el formato sin perder los datos.
Definiendo y entendiendo el flujo del programa
Ahora lo que haremos será crear el flujo del programa, primero usaremos while getopts para el manejo de los parametros que tendrá nuestro script.
En este caso para empezar primero pondremos 2 parametros, el primero será el -m que nos servirá para buscar una maquina y el segundo será -h para mostrar un panel de ayuda en caso de no saber usar el script o ejecutarlo mal.
function helpPanel(){
echo "estamos en la Funcion helpPanel"
}
function buscarMaquina(){
nombre=$1
echo "La maquina pasada por el argumento de la función es $nombre"
}
#Manejo de parametros
declare -i parameter_counter=0
while getopts "m:h" arg; do
case $arg in
m) nombreMaquina=$OPTARG; let parameter_counter+=1;;
h) ;;
esac
done
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
else
helpPanel
fi
Lo que hicimos primero fue declarar 2 funciones, la primera se llama helpPanel, la cuál más adelante declararemos, en este caso solamente muestra un echo de que se encuentra en la función de ayuda.
Y la otra función es similar solo que se llama buscarMaquina ya que esa función es la que nos buscará la información de una maquina pero por ahora solamente le metí un echo del parametro recibido como argumento, vemos que recibimos el primer argumento que se le paso a esta función cuando se llamo, y este argumento lo guardamos dentro de la variable nombre.
Después declaramos una vaariable entera declare -i parameter_counter=0 vemos que con el parametro -i indicamos que es int, osea un valor entero, no cadena/string(texto), y la igualamos a cero, esta variable nos servirá pará algo que veremos en lo siguiente que explicaré.
Ahora sigue lo del while getopts: while getopts "m:h" arg; En esto le estamos diciendo que nos vaya recorriendo cada parametro que tendrá el script, en este caso por ahora solo son 2 parametros, si el parametro tendrá argumentos al momento de usar su parametro se le ponen dos puntos a su derecha, es decir, si el parmetro -m tendrá argumentos en su ejecución, supongamos que se ejecuta así: ./script.sh -m "Maquina" vemos que el parametro -m tendrá un argumento que en este caso es “Maquina”, entonces como si tendrá argumento el parametro ponemos dos puntos “:” a la derecha en su declaracion el el while getopts. Y el parametro -h no tendrá por lo que lo dejamos sin dos puntos a la derecha.
Y seguido de eso vemos que ponemos “arg”, que esta es una variable que almacenará cada parametro uno por uno en cada ejecución, para lo siguiente:
while getopts "m:h" arg; do
case $arg in
m) nombreMaquina=$OPTARG; let parameter_counter+=1;;
h) ;;
esac
done
En el script una vez que entra a el while, primero revisa que si en caso de que el argumento actual que esta dentro de la variable arg en este momento se encuentré dentro de lo que esta abajo, entonces sucederá algo.
Supongamos que ejecutamos el script: ./script.sh -m "Maquina" , entonces al llegar al while getopts, lo que hará el script es que tomará el parametro -m y comprobará que existe, entonces como existe, lo que hará es obtener el argumento de dicho parametro usando “$OPTARG”, y lo va a guardar dentro de la variable nombreMaquina, así que la variable nombreMaquina tendrá el valor del argumento que se paso en el parametro -m, entonces en este caso el valor de la variable nombreMaquina será “Maquina”, ya que guardamos el valor de su argumento dentro de esa variable usando $OPTARG.
Y seguido de eso aumentaremos en un valor la variable parameter_counter que definimos anteriormente, usamos let para aumentar su valor en 1, ya que con esto nos permitirá más adelante saber que ha entrado en un parametro valido y no en el panel de ayuda.
Ya que como vemos en el parametro que definimos de h vemos que no ponemos nada ni aumenta el parameter_counter esto es intencional, para saber que si paramter_counter vale 0, quiere decir que no entro a ningun parametro valido por lo que se ejecutará la función helpPanel.
Y para que el script maneje estas funciones correctamente usamos las siguientes condicionales:
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
else
helpPanel
fi
Aquí es donde gracias a la variable parameter_counter podemos manejar el flujo del programa, en la primera condicion decimos que si el valor de parameter_counter es igual (-eq) a 1, quiere decir que el script en el while getopts entro a un paramtero valido, y el parametro valido que tenemos aumenta en un valor esa variable, por lo que entonces quiere decir que se va a ejecutar la función buscarMaquina que en este caso es la única que tenemos por ahora valida aparte del panel de ayuda.
Y se va a llamar a la función pasandole como parametro el valor de la variable nombreMaquina que recordamos que en esa variable se almacena el argumento que se paso en la ejecución del script, y esto se pasa ya que en la función buscarMaquina necesitamos este nombre para después buscar la información de dicha maquina. Recordemos que en la declaración de la función buscarMaquina hemos recibido el parametro que se enviaría por aquí al llamar a la función junto con el argumento(valor de la variable nombreMaquina).
Y en caso de que el valor de parameter_counter no sea igual a 1, quiere decir que no entro a ningún parametro valido, por lo que se llamará automaticamente a la función helpPanel para mostrarle al usuario como se debe ejecutar el script.
Y ahora esto en la ejecución se ve así:

Podemos ver que se ejecuto correctamente y entro a la función buscarMaquina correctamente y nos ejecuto lo que hay en esa función.
Y en caso de ejecutar algo que no exista o incorrecto vemos que igual nos funciona el flujo que definimos del panel de ayuda:

Vemos que nos ha llevado a la función de ayuda al momento de hacer algo que no existe en el script.
Definiendo las funciones
Ahora que ya definimos el flujo de el programa, lo que toca ahora es escribir lo que hará cada función.
Primero la función de helpPanel la modificamos con colores y instrucciones de uso quedando así:
function helpPanel(){
echo -e "\n${greenColour}[!] ${yellowColour}Uso del script:"
echo -e "\t${purpleColour}m) ${yellowColour}Buscar una maquina por su nombre${endColour}"
echo -e "\t${purpleColour}h) ${yellowColour}Mostrar este panel de ayuda${endColour}"
}
Indicamos con colores las instrucciones de los parametros y su función de cada una, y el help panel ahora se verá mucho mejor:

Podemos ver que se ve mucho mejor.
Ahora antes de escribir lo que ejecutará la función buscarMaquina , vamos a definir otra función antes, esta función nueva se llamará actualizarArchivos y lo que hará es descargarnos el archivo javascript más reciente de la web donde se alojan todas las maquinas.
la vamos a definir en el script:
function actualizarArchivos(){
echo -e "\n${greenColour}[!] ${turquoiseColour}Actualizando archivos...${endColour}"
}
Por el momento solo le indicamos un mensaje de que se actualizará los archivos, esta función la agregamos cerca de las demas funciones.
Agregando la funcion actualizarArchivos a el getopts
Ahora que ya tenemos la función creada llamada actualizarArchivos la agregaremos a el while getopts para que nuestro script reconozca un parametro que llame a esta función en caso de que el usuario haya usado dicho parametro:
#Manejo de parametros
declare -i parameter_counter=0
while getopts "m:uh" arg; do
case $arg in
m) nombreMaquina=$OPTARG; let parameter_counter+=1;;
u) let parameter_counter+=2;;
h) ;;
esac
done
En este caso editamos el while getopts para agregar un nuevo parametro, en este caso será el parametro -u (no necesita parametros por lo que se agrega sin dos puntos a la derecha al igual que el parametro h), y vemos que en caso de que se use el parametro -u, lo que hará es aumentar en 2 la variable parameter_counter, esto se hace para saber que en caso de que esa variable valda 2, sabremos que se esta usando ese parametro, por lo que en el manejo de funciones sabremos si se ejecutará esa función.
Definiendo el flujo de la nueva funcion
Ahora que ya esta creada la función actualizarArchivos y está en el while getopts para manejar el parametro, lo que queda ahora es llamar a la función en caso de que se use ese parametro, y como recordamos que en caso de que se use, la variable parameter_counter valdría 2, entonces haremos otra condición en el manejo de funciones:
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
elif [ $parameter_counter -eq 2 ]; then
actualizarArchivos
else
helpPanel
fi
Vemos que agregamos un elif, que esto indica que en caso de que el primer if no se cumpla, entonces siga con la siguiente condición, que en este caso es que si la variable parameter_counter es igual a 2, entonces se llamará a la función actualizarArchivos, de este modo ya hemos creado el flujo de ese parametro. Recuerda que el 2 es porque si la variable entro a el valor del parametro u) en el while getopts, indica que el usuario ingreso ese parametro y como pusimos el 2 para darnos cuenta de que se trata de ese parametro, y esa es la lógica del manejo de las funciones.
Así que ahora que definimos esto, ejecutaremos el script con este nuevo parametro para ver que funciona:

Vemos que nos muestra lo que escribimos que se hiciera en la función actualizarArchivos, obviamente aún no sucede algo más que mostrar el mensaje ya que aún no definimos las instrucciones pero ya tenemos el flujo de ese paremtro definido.
Y por último no olvidemos agregar lo que hace ese parametro en la función helpPanel:
function helpPanel(){
echo -e "\n${greenColour}[!] ${yellowColour}Uso del script:"
echo -e "\t${purpleColour}u) ${yellowColour}Actualizar archivos necesarios${endColour}"
echo -e "\t${purpleColour}m) ${yellowColour}Buscar una maquina por su nombre${endColour}"
echo -e "\t${purpleColour}h) ${yellowColour}Mostrar este panel de ayuda${endColour}"
}
Vemos que hemos agregado la linea del parametro -u, y ahora el helpPanel se vería así:
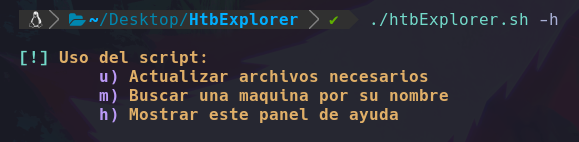
Definiendo las instrucciones de la funcion actualizarArchivos
Recordemos que primero debemos descargar el archivo y pasarle el js-beautify, así que agreagaremos esos comandos para descargar el archivo.
Primero crearemos una variable global con la URL de la web donde se aloja el archivo que contiene las maquinas:
htbweb="https://htbmachines.github.io/bundle.js"
Esta variable la agregamos casi hasta el inicio del script, para que sea global y no solo de una función.
Una vez tengamos esta variable global definida, lo que haremos sera escribir las instrucciones de la función actualizarArchivos, primero definiremos en caso de que sea la primera vez y el archivo bundle.js no exista:
function actualizarArchivos(){
if [ ! -f bundle.js ]; then
echo -e "\n${greenColour}[!] ${turquoiseColour}Actualizando archivos...${endColour}"
curl -s -X GET $htbweb > bundle.js
js-beautify bundle.js | sponge bundle.js
echo -e "\n${greenColour}[!] ${turquoiseColour}Los archivos se han descargado correctamente!"
fi
}
Primero en el if estamos comprobando si el archivo bundle.js no existe, usamos el parametro -f para indicar un archivo “file” y el signo ! indica lo contrario, es decir si no estuviera ese signo la condicion sería “Si existe el archivo bundle.js entonces ….” Pero como en este caso tiene el signo entonces es “Si el archivo bundle.js NO existe entonces…”, así que lo que hará en caso de que el archivo bundle.js no exista es lo siguiente:
Primero muestra el mensaje de que se estan actualizando los archivos, después hace una petición con curl a la URL que se almacena en la variable global htbweb, por el metodo GET, y almacenamos el output dentro de un archivo llamado bundle.js , Y en la siguiente linea usamos la herramienta js-beautify para darle mejor formato a el archivo, y por último reemplazamos el formato anterior con el nuevo usando sponge.
Y mostramos un mensaje de que los archivos se han descargado correctamente.
Y si ejecutamos el script así:

Vemos que no nos ejecuto nada ya que la condición no se cumplio, ya que el archivo si existe, y la condicion solo se ejecutará si el archivo no existia, pero si lo eliminamos y ejecutamos nuevamente veremos que ahora si se descarga:
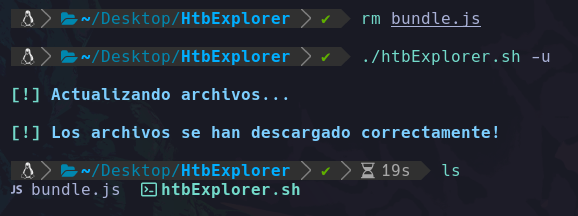
Así que la primera parte esta hecha.
Pero ahora queremos que si ya existe el archivo bundle.js, buscar si existe alguna actualizacion en el archivo para cambiarlo por este nuevo, así que para esto agregaremos otra condición en caso de exista el archivo ya, lo que haremos será lo siguiente.
Definiendo la actualizacion del archivo usando (md5sum)
md5sum Es una herramienta que nos servirá para en este caso saber si se han agregado cosas nuevas a el archivo bundle.js que tenemos, pero primero entenderemos que es md5sum.
En este caso dijimos que nos servirá para saber si el contenido de 2 archivos es igual o distinto, si es distinto significa que se ha actualizado, veamos un ejemplo.
He creado 2 archivos de texto llamados texto1.txt y texto2.txt pero ambos tienen el mismo contenido el cual eso es “Hello friend” como podemos ver:
Vemos que contienen el mismo contenido, así que deben tener el mismo hash de huella de archivo, ya que cada archivo contiene un valor hash en base a el contenido, como en este caso el contenido es el mismo, vermos sus valores md5:

Y vemos que es el mismo valor ya que tienen el mismo contenido, pero si modificamos algun archivo aunque sea un solo un valor vemos que el hash va a cambiar completamente:
Podemos ver que el valor del archivo 1 ha cambiado ya que agregamos un valor y ya no es el mismo hash.
Así que usaremos esta metodología en el script y nos servirá para comparar el archivo actual con uno nuevo y en caso de que no sean igual reemplazar el antiguo por el nuevo.
Así que en caso de que el archivo bundle.js ya se encuentre en el equipo, entonces lo que sucederá es esta siguiente condición else que agregamos a la función actualizarArchivos:
function actualizarArchivos(){
if [ ! -f bundle.js ]; then
echo -e "\n${greenColour}[!] ${turquoiseColour}Actualizando archivos...${endColour}"
curl -s -X GET $htbweb > bundle.js
js-beautify bundle.js | sponge bundle.js
echo -e "\n${greenColour}[!] ${turquoiseColour}Los archivos se han descargado correctamente!"
else
curl -s -X GET $htbweb > bundle_new.js
js-beautify bundle_new.js | sponge bundle_new.js
md5_newhash=$(md5sum bundle_new.js | awk '{print $1}')
md5hash=$(md5sum bundle.js | awk '{print $1}')
fi
}
la parte del else es la que nos interesa, vemos que primero obtenemos el contenido de el bundle.js de la web y lo guardamos dentro de un nuevo archivo llamado bundle_new.js , ahora le aplicamos el js-beautify para darle el formato más legible, después con sponge reemplazamos el contenido antiguo desordenado con el nuevo ordenado.
Y después creamos 2 variables, estas contienen el valor del hash del comando que arroja md5sum y las guarda cada una en una variable, en este caso en una variable guardamos el hash de el archivo bundle_new.js y en la otra en el archivo que ya teniamos.
Y usamos awk y print $1 ya que al hacer md5sum vemos que el valor 1 es el hash:

Vemos que nos interesa quedarnos con el primer valor no con toda la linea.
Así que una vez ya tengamos los hash de los 2 archivos en las variables vamos a comprobar si son distintas o no, para ello agregaremos la siguiente condicional:
function actualizarArchivos(){
tput civis
if [ ! -f bundle.js ]; then
echo -e "\n${greenColour}[!] ${turquoiseColour}Actualizando archivos...${endColour}"
curl -s -X GET $htbweb > bundle.js
js-beautify bundle.js | sponge bundle.js
echo -e "\n${greenColour}[!] ${turquoiseColour}Los archivos se han descargado correctamente!"
else
curl -s -X GET $htbweb > bundle_new.js
js-beautify bundle_new.js | sponge bundle_new.js
md5_newhash=$(md5sum bundle_new.js | awk '{print $1}')
md5hash=$(md5sum bundle.js | awk '{print $1}')
if [ "$md5_newhash" == "$md5hash" ]; then
echo -e "${turquoiseColour}[!] Los archivos estan actualizados${endColour}"
rm bundle_new.js
else
echo -e "${yellowColour}[!] Iniciando con las actualizaciones...${endColour}"
rm bundle.js && mv bundle_new.js bundle.js
echo -e "${yellowColour}[+] Los archivos se han actualizado correctamente${endColour}"
fi
fi
tput cnorm
}
Primero agregamos una condición if que dice que si el contenido de la variable md5_newhash es igual a el contenido de la variable md5hash entonces lo que ocurrira será que mostrará un mensaje que los archivos estan actualizados y eliminará el nuevo que se creo para comparar pero como son el mismo entonces se elimina para no tener 2 iguales.
Y en caso de que no sean iguales entonces se irá a el else y ejecutará un mensaje que dice que iniciaron las actualizaciones y lo que sucede es que eliminamos el archivo antiguo osea el bundle.js y lo reemplazamos por el nuevo cambiandolo de nombre a bundle.js para que este sea el mas nuevo y por último mostramos un mensaje que dice que se ha actualizado correctamente.
Y también en el codigo agregamos tput civis que sirve para ocultar el cursor durante la ejecución del código y también al final agregamos tput cnorm para restablecer el cursor una vez termine de ejecutarse la función.
Y en este punto esto estaría listo, y probaremos primero:
Y en caso de que haya una actualización en el archivo sucederá esto:

Y habremos terminado de definir esta función.
Creando un one-liner para obtener los datos de una maquina que nos interesa
Esto lo haremos para definir una función que nos muestre los datos de una maquina, para ello primero buscaremos una maquina en el bundle.js para ver como esta estructurada la información:
En este caso nos interesa desde el nombre de la maquina osea el texto “name:” hasta el texto “resuelta:”, Ya que en ese rango nos interesa los valores name, ip, so, dificultad, etc. hasta llegar a resuelta.
Primero ocupamos crear una cadena de comandos para filtrar los valores que nos interesan:
cat bundle.js | grep "name: \"Tentacle\"" -A 10
En este caso estamos viendo que debajo de el valor name se encuentra el resto de valores que nos interesan, en este caso usamos grep y escapamos las comillas dobles dentro de las comillas dobles para evitar una confusion de sintaxis y provocar un error, recuerda que el parametro -A en grep es para ver ciertas lineas hacía abajo de un determinado elemento, en este caso queremos que nos muestre 10 lineas debajo de lo que filtramos.
Pero ahora para este proposito usaremos awk no grep, ya que awk nos permite lo siguiente:
cat bundle.js | awk "/name: \"Tentacle\"/,/resuelta:/"
En este caso estamos filtrando el valor name: “Tentacle” hasta el valor resuelta: , aquí igual se escapan las comillas dobles, y para filtrar hasta un determinado valor se usa una comilla segudido del valor al cual es hasta donde debemos filtrar, y cada valor debe estar entre barras //, la sintaxis es algo así para que la entiendas mejor:
awk "/inicio/,/final/"
Vemos que primero va de donde queremos empezar a filtrar y hasta donde queremos llegar.
Y esto se verá algo así:
Obviamente en el script el valor del nombre de la maquina será relativo ya que le pediremos a el usuario el nombre de la maquina y através de una variable recibiremos ese valor y lo utilizaremos.
Ahora vamos a eliminar valores que no nos interesan, como id, sku, resuelta, para ello ahora si usaremos grep para remover esos elementos:
cat bundle.js | awk "/name: \"MultiMaster\"/,/resuelta:/" | grep -vE "id|sku|resuelta"
Y vemos que ya se han removido los elementos que no nos interesan:
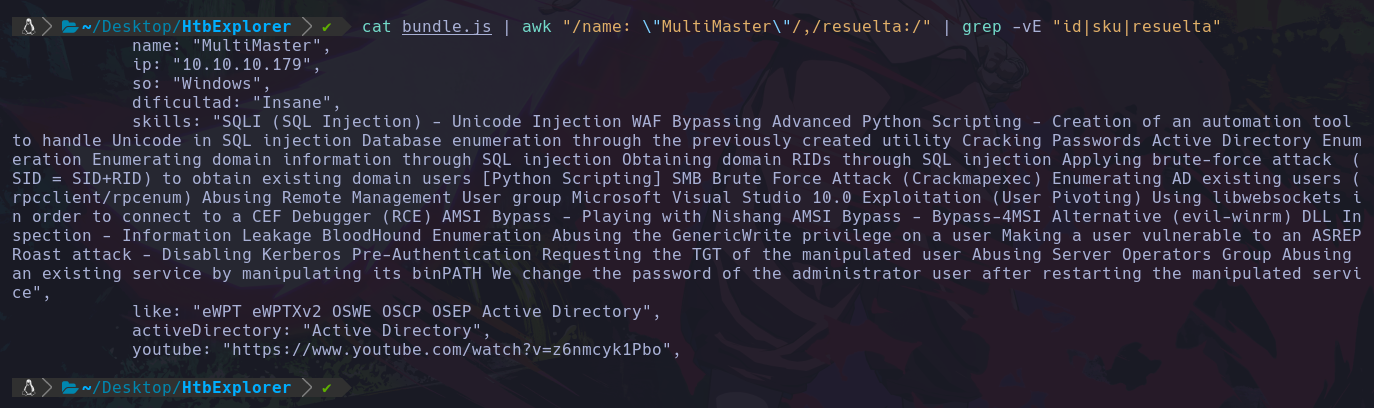
Ahora vamos a hacer la información lo mas limpia posible, en este caso removeremos las comillas dobles y comas que tiene la información:
cat bundle.js | awk "/name: \"MultiMaster\"/,/resuelta:/" | grep -vE "id|sku|resuelta" | tr -d '"|,'
En este caso usamos tr para eliminarlo, y nos quedará así:
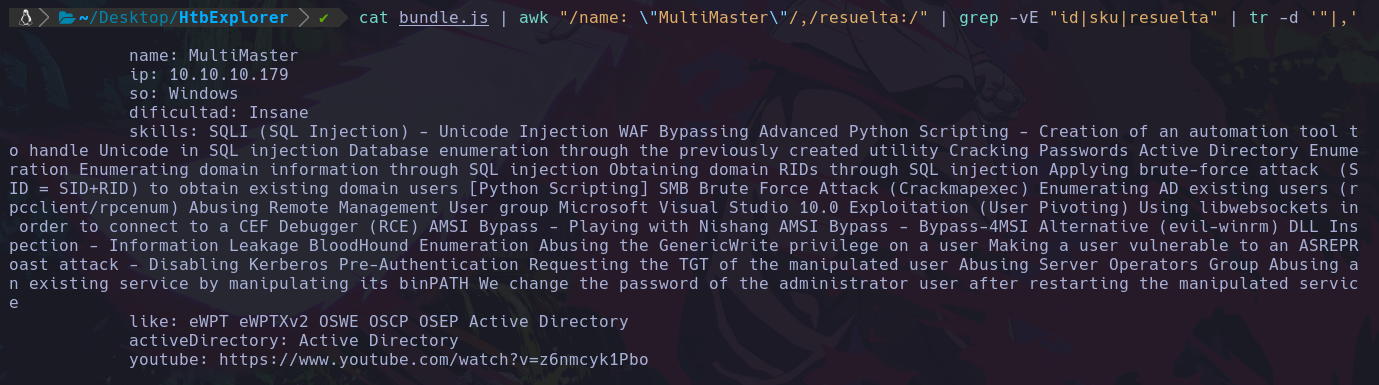
Ahora lo único que queda por limpiar son los espacios extras que se agregan a el output.
Para ello usaremos sed: sed 's/^ *//' indicamos que queremos sustituir por eso usamos el valor “s”, queremos sustituir los espacios que se representan con ‘^’ y queremos sustituir todos los espacios seguidos que existen, osea si hay 2 espacios seguidos los cambiara por nada por lo que los va a eliminar, por eso pa parte final son 2 barras vacias ya que no hay contenido que reemplazar porque solo queremos eliminar esos espacios.
Y quedará así:
cat bundle.js | awk "/name: \"MultiMaster\"/,/resuelta:/" | grep -vE "id|sku|resuelta" | tr -d '"|,' | sed 's/^ *//'
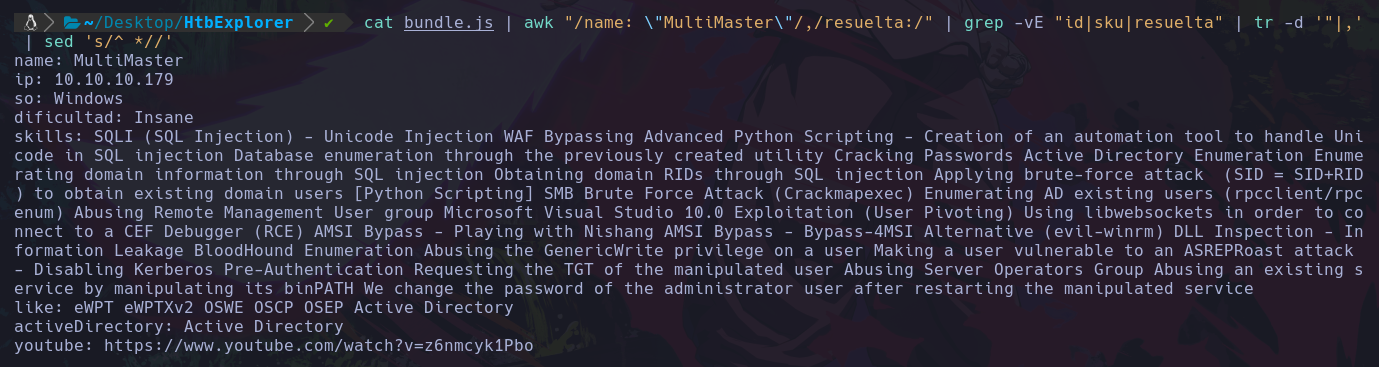
Definiendo la funcion buscarMaquina
Recordemos que esta función ya la agregamos a el while getopts y también ya la creamos, ahora queda definir las instrucciones, primero vamos a agregar mensaje en pantalla de lo que esta sucediendo y poner el one-liner que hemos creado anteriormente para mostrar los datos de cierta maquina, y la función buscarMaquina quedará así:
function buscarMaquina(){
nombre=$1
echo -e "\n${yellowColour}[+] ${greenColour}Listando propiedades de la maquina ${purpleColour}$nombre${endColour}\n"
echo -e "${yellowColour}"
cat bundle.js | awk "/name: \"$nombre\"/,/resuelta:/" | grep -vE "id|sku|resuelta" | tr -d '"|,' | sed 's/^ *//'
echo -e "${endColour}"
}
Primero recibimos el nombre de la maquina que recordamos se paso en el parametro -m, y lo recibimos y lo almacenamos en una variable llamada nombre que en este caso ese valor es el nombre de la maquina.
Luego mostramos un mensaje que indica que se mostraran las propiedades de la maquina, y seguido de eso hacemos el filtrado de información de dicha maquina vemos que llamamos a la variable $nombre con los filtros que creamos anteriormente y en la ejecución se verá algo así:
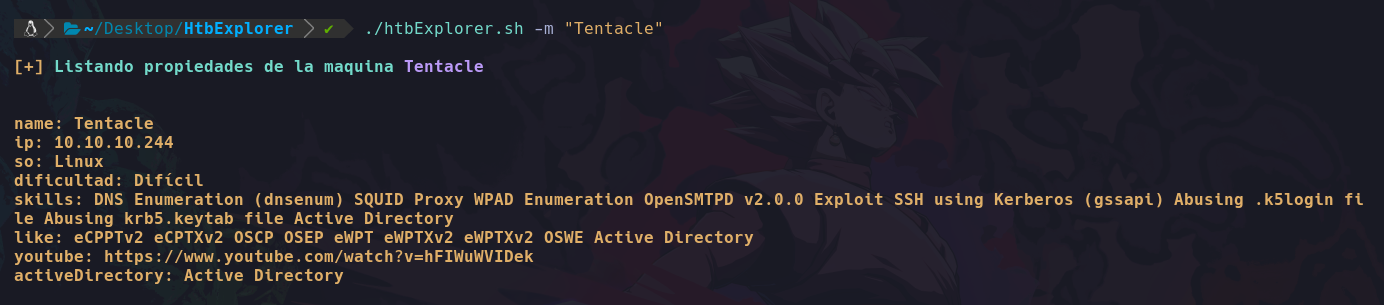
Vemos que se muestra todo lo que nos interesa de dicha maquina.
Definiendo un nuevo parametro al script para buscar una maquina por una IP
Ahora agregaremos algo nuevo, sabemos que primero debemos agregar ese nuevo parametro a el helpPanel para que el usuario sepa, también agregarlo a el while getopts, y por su puesto crear la función y agregarla a el manejo de funciones.
Primero agregaremos su uso en el helpPanel:
function helpPanel(){
echo -e "\n${greenColour}[!] ${yellowColour}Uso del script:"
echo -e "\t${purpleColour}u) ${yellowColour}Actualizar archivos necesarios${endColour}"
echo -e "\t${purpleColour}m) ${yellowColour}Buscar una maquina por su nombre${endColour}"
echo -e "\t${purpleColour}i) ${yellowColour}Buscar una maquina por su dirección IP${endColour}"
echo -e "\t${purpleColour}h) ${yellowColour}Mostrar este panel de ayuda${endColour}"
}
Vemos que hemos agregado el nuevo parametro -i en el panel de ayuda.
Ahora en el while getopts para que nos detecte este parametro como existente:
while getopts "m:i:uh" arg; do
case $arg in
m) nombreMaquina=$OPTARG; let parameter_counter+=1;;
u) let parameter_counter+=2;;
i) ipAddress=$OPTARG; let parameter_counter+=3;;
h) ;;
esac
done
Vemos que hemos agregado el valor de la IP que se pasará como argumento a ese parametro, el valor lo guardaremos dentro de la variable ipAddress, y con parameter_counter aumentaremos en 3 para identificarlo en el manejo de funciones.
Agregando el manejo de función en caso de que se use el parametro -i en el script:
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
elif [ $parameter_counter -eq 2 ]; then
actualizarArchivos
elif [ $parameter_counter -eq 3 ]; then
buscarIp $ipAddress
else
helpPanel
fi
Vemos que si en caso de que el valor del parameter_counter sea igual a 3 entonces se ejecutará la función buscarIp pasandole como argumento el valor de la variable ipAddress.
En resumen hicimos esto:
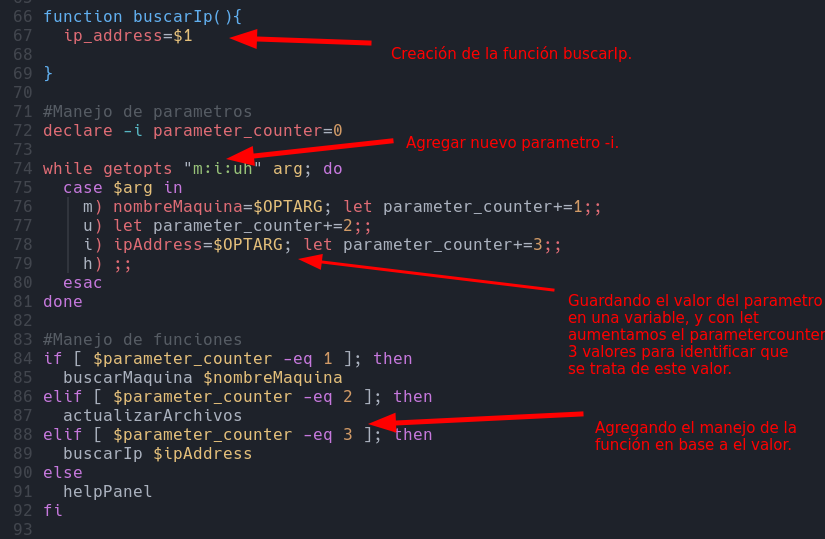
Definir la nueva funcion buscarIp
Ahora vamos a definir la función buscarIp para que en base a una IP dada nos reporte que maquina tiene esa dirección IP.
Primero crearemos un one-liner para que através de una IP dada nos muestre el nombre de la maquina.
Sabemos que todas las maquinas se encuentran dentro del bundle.js por lo tanto su IP igual se encuentra en cada maquina.
Así que si filtramos con grep por “ip:” veremos todas:
cat bundle.js | grep "ip:"
Así que para hacer el one-liner usaremos una IP cualquiera de ejemplo y la filtraremos:
cat bundle.js | grep "ip: \"10.10.10.85\""
Recuerda escapar las dobles comillas
Y vemos:

Ahora nos interesa ver 3 elementos hacía arriba ya que arriba se encuentra el nombre de la maquina, así que usaremos el parametro -B de grep:
cat bundle.js | grep "ip: \"10.10.10.85\"" -B 3

Vemos que se encuentra ahí el nombre en “name”, así que filtraremos por eso que nos interesa:
cat bundle.js | grep "ip: \"10.10.10.85\"" -B 3 | grep "name:"

Ahora nos interesa quedarnos solo con el valor del nombre no con las comillas, así que usaremos awk para quedarnos con el ultimo elemento:
cat bundle.js | grep "ip: \"10.10.10.85\"" -B 3 | grep "name:" | awk 'NF{print$NF}'

Ahora por ultimo vamos a remover las comillas con tr -d:
cat bundle.js | grep "ip: \"10.10.10.85\"" -B 3 | grep "name:" | awk 'NF{print$NF}' | tr -d '"|,'

Y vemos que ya tenemos el valor solo de lo que nos interesa, ahora simplemente meteremos esto al script y através del parametro -i que agregamos usaremos el argumento pasado a ese parametro para usarlo en una variable y así funcione nuestro script, así que lo agregaremos a la función y nos quedará así:
function buscarIp(){
ip_address="$1"
nombreMaquina=$(cat bundle.js | grep "ip: \"$ip_address\"" -B 3 | grep "name:" | awk 'NF{print$NF}' | tr -d '"|,')
echo -e "\n${turquoisecolour}[+] ${purpleColour}El nombre de la maquina en la IP ${greenColour}$ip_address${purpleColour} es
${greenColour}$nombreMaquina"
}
Como ya vimos primero obtenemos el argumento que se le paso cuando se llamo a la función buscarIp en la variable ip_address.
Luego el one-liner que recien creamos lo guardamos en una variable llamada nombreMaquina, y usamos el valor de la variable ip_address para que el one-liner sea relativo en cuanto a todas las IP.
Y por último mostramos el nombre de la maquina de dicha IP.
Y ya habremos terminado de definir esta función.
Creando una funcion para obtener el Link de Youtube de una maquina
Ahora si queremos obtener el Link para saber como se resuelve una maquina necesitamos crear una función nueva:
Primero agregarla al helpPanel:
function helpPanel(){
echo -e "\n${greenColour}[!] ${yellowColour}Uso del script:"
echo -e "\t${purpleColour}u) ${yellowColour}Actualizar archivos necesarios${endColour}"
echo -e "\t${purpleColour}m) ${yellowColour}Buscar una maquina por su nombre${endColour}"
echo -e "\t${purpleColour}i) ${yellowColour}Buscar una maquina por su dirección IP${endColour}"
echo -e "\t${purpleColour}y) ${yellowColour}Obtener el link de la resolución de una maquina${endColour}"
echo -e "\t${purpleColour}h) ${yellowColour}Mostrar este panel de ayuda${endColour}"
}
Vemos que hemos agregado a el menú de ayuda un parametro -y que indica el uso de ese parametro.
Después lo agregaremos a el while getopts:
while getopts "m:i:y:uh" arg; do
case $arg in
m) nombreMaquina="$OPTARG"; let parameter_counter+=1;;
u) let parameter_counter+=2;;
i) ipAddress="$OPTARG"; let parameter_counter+=3;;
y) NombreMaquina="$OPTARG"; let parameter_counter+=4;;
h) ;;
esac
done
Primero agregamos el parametro y a el getopts, después definimos en caso de que se use.
Vemos que guardaremos el argumento que se le pasará a ese parametro en caso de que se llame, y se guardará dentro de la variable NombreMaquina ya que se pasará el nombre de la maquina que ocupamos para obtener su link, y el parameter_counter aumentará en 4 para identificar que parametro se esta usando en el control de funciones.
Vemos que hemos guardado el valor de cada parametro que se obtiene en sus variables con comillas dobles, esto para que la variable se tome de valor string y evitar errores. es una pequeña corrección pero muy importante.
Y ahora agregaremos la condición en el manejo de funciones:
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
elif [ $parameter_counter -eq 2 ]; then
actualizarArchivos
elif [ $parameter_counter -eq 3 ]; then
buscarIp $ipAddress
elif [ $parameter_counter -eq 4 ]; then
getLink $NombreMaquina
else
helpPanel
fi
En este caso se llamará a la función getLink y se le pasará como argumento el nombre de la maquina que se le paso al parametro -y.
Esta función getLink la crearemos enseguida.
Antes de definir esta funcion vamos a crear un one-liner para obtener el link de una maquina.
Primero como vimos ya, vamosa mostrar el rango desde “name” hasta “resuelta” de una maquina:
cat bundle.js | awk "/name: \"MultiMaster\"/,/resuelta:/"
Ahora que ya tenemos el rango de esa maquina especifica, en este caso solo nos interesa el link así que usando grep obtendremos ese valor:
cat bundle.js | awk "/name: \"MultiMaster\"/,/resuelta:/" | grep "youtube:"

Ahora simplemente nos interesa quedarnos con el último argumento:
cat bundle.js | awk "/name: \"MultiMaster\"/,/resuelta:/" | grep "youtube:" | awk 'NF{print $NF}'

Ahora solamente usando tr -d vamos a eliminar las comillas dobles y coma:
cat bundle.js | awk "/name: \"MultiMaster\"/,/resuelta:/" | grep "youtube:" | awk 'NF{print $NF}' | tr -d '"|,'

Y vemos que en el output ya tenemos el puro link.
Ahora meteremos este one-liner a la función getLink:
function getLink(){
maquina="$1"
obtenerLink="$(cat bundle.js | awk "/name: \"$maquina\"/,/resuelta:/" | grep "youtube:" | awk 'NF{print $NF}' | tr -d '"|,')"
echo -e "${purpleColour}[*] ${turquoiseColour}El link de la resolución de la maquina ${greenColour}$maquina ${turquoiseColour}es: ${greenColour}$obtenerLink${endColour}"
}
Primero obtenemos el valor pasado a la función y lo guardamos como string dentro de la variable maquina.
Luego en la variable obtenerLink guardamos el output de la salida del one-liner, en este caso la maquina que se le busca el Link es la que contenga la variable maquina osea la maquina que el usuario indico en el parametro -y.
Luego con un echo nos muestra el link de la maquina.
Y se verá algo así:
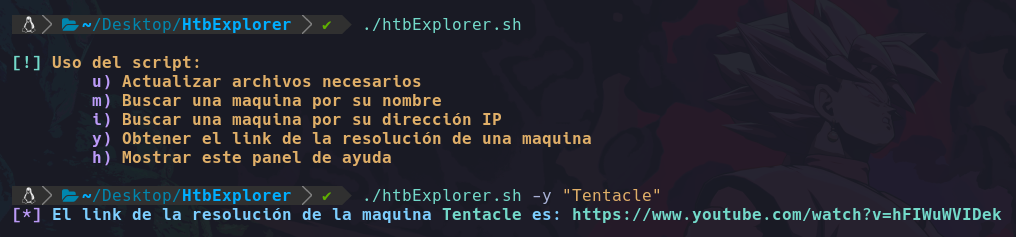
Agregando a las funciones un mensaje en caso de que el elemento ingresado por el usuario no exista
Ahora debemos arreglar algo, ya que cuando el usuario ingresa algo invalido a cualquiera de los parametros que devuelven un output vemos que se ve así:
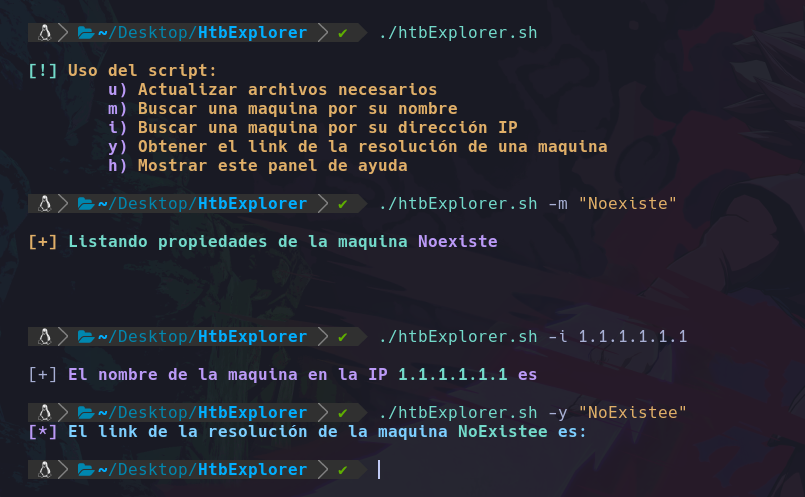
Podemos ver que se muestra el output pero no muestra nada, y esto es algo que debemos arreglar.
Así que en cada función vamos a agregar una condición para saber si existe o no.
Para ello iremos a la primera función a arreglar esto, nuestra función buscarMaquina se ve así:
function buscarMaquina(){
nombre=$1
echo -e "\n${yellowColour}[+] ${greenColour}Listando propiedades de la maquina ${purpleColour}$nombre${endColour}\n"
echo -e "${yellowColour}"
cat bundle.js | awk "/name: \"$nombre\"/,/resuelta:/" | grep -vE "id|sku|resuelta" | tr -d '"|,' | sed 's/^ *//'
echo -e "${endColour}"
}
Pero le agregaremos la condicion:
function buscarMaquina(){
nombre="$1"
validacion="$(cat bundle.js | awk "/name: \"$nombre\"/,/resuelta:/" | grep -vE "id|sku|resuelta" | tr -d '"|,' | sed 's/^ *//'
)"
if [ "$validacion" ]; then
echo -e "\n${yellowColour}[+] ${greenColour}Listando propiedades de la maquina ${purpleColour}$nombre${endColour}\n"
echo -e "${yellowColour}"
cat bundle.js | awk "/name: \"$nombre\"/,/resuelta:/" | grep -vE "id|sku|resuelta" | tr -d '"|,' | sed 's/^ *//'
echo -e "${endColour}"
else
echo -e "${redColour}[!] El nombre de la maquina No existe${endColour}"
fi
}
Primero metimos el mismo one-liner en una variable que es el que se mostraba en esta funcion antes de agregar esta condicion, pero esta vez también lo almacenamos en una variable y antes de mostrarse primero se valida si ese valor tiene contenido, si tiene contenido quiere decir que los filtros se aplicaron osea grep, awk, etc. indica que se aplicaron correctamente al encontrar un valor con ese nombre al cual hacerle modificaciones con estos filtros.
Y en caso de que no exista el nombre de esa maquina en el bundle.js que es de donde obtenemos todos los datos entonces la variable quedará vacía ya que no encontro nada a que hacerle esos filtros.
Y recuerda que la condición para saber si una variable tiene contenido es simplemente ponerla así tal cual la variable dentro del if if [ "$validacion" ]; then y le estaremos indicando eso sin agregar nada mas.
Y en caso de que si exista vemos que se muestra ahora si el output original, y en caso de que no exista se mostrará un mensaje de que no existe esa maquina.
Y en la practica se verá algo así:
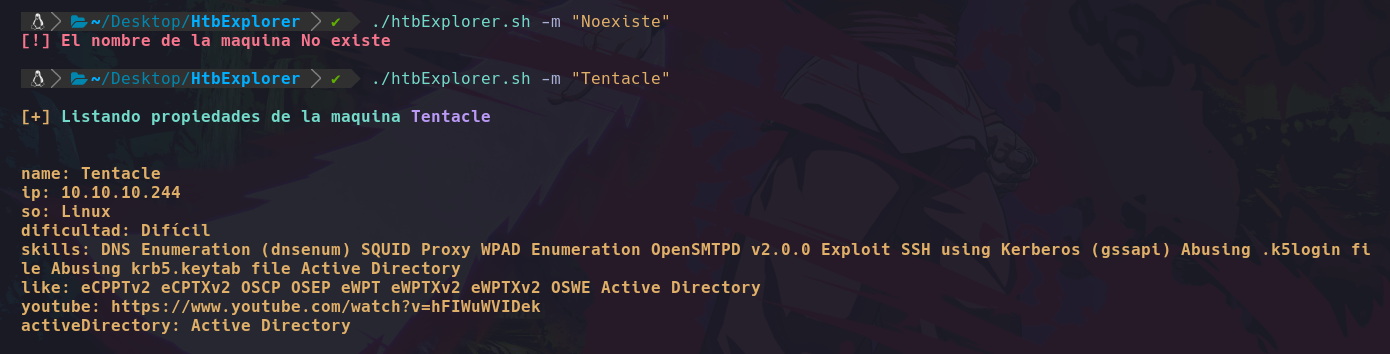
Ahora si le metemos un valor inexistente nos mostrará ese mensaje en rojo.
Lo mismo haremos con el resto de funciones que muestran un output, como la función de buscar por IP:
function buscarIp(){
ip_address="$1"
nombreMaquina=$(cat bundle.js | grep "ip: \"$ip_address\"" -B 3 | grep "name:" | awk 'NF{print$NF}' | tr -d '"|,')
if [ "$nombreMaquina" ]; then
echo -e "\n${turquoisecolour}[+] ${purpleColour}El nombre de la maquina en la IP ${greenColour}$ip_address${purpleColour}
es ${greenColour}$nombreMaquina"
else
echo -e "${redColour} [!] La dirección IP proporcionada no existe${endColour}"
fi
}
Usamos el mismo concepto, usando la variable que guarda el puro nombre de la maquina verificamos si en verdad guardo algo ya que de ser asi quiere decir que logro encontrar un valor con el nombre de esa maquina al cual aplicarle los filtros, y de lo contrario si está vacia la variable quiere decir que no encontro nada a que hacerle esos filtros con ese nombre pasado por el parametro.
Así que usando esa variable aplicamos la condición if, y en caso de que si tenga contenido, se mostrará ahora si lo que se mostraba anteriormente que era el nombre de la maquina en base a su IP.
Y así se vería en la practica:

Y por último también haremos esto con la función de getLink:
function getLink(){
maquina="$1"
obtenerLink="$(cat bundle.js | awk "/name: \"$maquina\"/,/resuelta:/" | grep "youtube:" | awk 'NF{print $NF}' | tr -d '"|,')"
if [ "$obtenerLink" ]; then
echo -e "${purpleColour}[*] ${turquoiseColour}El link de la resolución de la maquina ${greenColour}$maquina ${turquoiseColour}es: ${greenColour}$obtenerLink${endColour}"
else
echo -e "${redColour}[!] El nombre de la maquina proporcionada no existe${endColour}"
fi
}
Nuevamente el mismo concepto, una vez tengamos el valor en la variable obtenerLink comprobaremos con el if si en verdad obtuvo un valor o no encontro nada y solo almaceno una cadena vacia.
En caso de que si encontro a que aplicarle el one-liner en este caso el nombre de la maquina a la cual se le quiere sacar el link de youtube, entonces continuará con normalidad.
Y en caso de que no exista lo que ingreso el usuario entonces mostrará el mensaje de error.
Y el cuál en la practica se ve así:

Y ya habremos definido este concepto en cada función que muestra un output en base al input del usuario, y seguiremos usando este concepto para verificar si el contenido existe o no.
Creando una funcion para obtener todas las maquinas de una cierta dificultad
Ahora queremos agregar un parametro al script que al usarlo e indicarle la dificultad nos muestre las maquinas con esa dificultad.
Primero ya sabemos lo que se hace, agregar el parametro nuevo al helpPanel:
function helpPanel(){
echo -e "\n${greenColour}[!] ${yellowColour}Uso del script:"
echo -e "\t${purpleColour}u) ${yellowColour}Actualizar archivos necesarios${endColour}"
echo -e "\t${purpleColour}m) ${yellowColour}Buscar una maquina por su nombre${endColour}"
echo -e "\t${purpleColour}i) ${yellowColour}Buscar una maquina por su dirección IP${endColour}"
echo -e "\t${purpleColour}y) ${yellowColour}Obtener el link de la resolución de una maquina${endColour}"
echo -e "\t${purpleColour}d) ${yellowColour}Listar las maquinas en base a su dificultad${endColour}"
echo -e "\t${purpleColour}h) ${yellowColour}Mostrar este panel de ayuda${endColour}"
}
Vemos que agregamos el parametro -d que este indicará la dificultad.
Ahora sigue agregarlo al while getopts:
while getopts "m:i:y:d:uh" arg; do
case $arg in
m) nombreMaquina="$OPTARG"; let parameter_counter+=1;;
u) let parameter_counter+=2;;
i) ipAddress="$OPTARG"; let parameter_counter+=3;;
y) NombreMaquina="$OPTARG"; let parameter_counter+=4;;
d) Dificultad=$OPTARG; let parameter_counter+=5;;
h) ;;
esac
done
Vemos que en caso de que se use este parametro, el argumento pasado a este parametro será guardado dentro de la variable Dificultad, y aumentamos el parameter_counter en 5, recordemos que esto es para identificarlo en el manejo de funciones.
Ahora toca agregarlo al manejo de funciones:
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
elif [ $parameter_counter -eq 2 ]; then
actualizarArchivos
elif [ $parameter_counter -eq 3 ]; then
buscarIp $ipAddress
elif [ $parameter_counter -eq 4 ]; then
getLink $NombreMaquina
elif [ $parameter_counter -eq 5 ]; then
ListarDificultad $Dificultad
else
helpPanel
fi
En este caso si el parameter_counter es igual a 5, entonces llamaremos a la función llamada listarDificultad y se le pasa como argumento el valor que se obtuvo del parametro -d.
Ahora vamos a definir la función ListarDificultad pero primero necesitamos un one-liner para filtrar las maquinas de cierta dificultad:
Por ejemplo si queremos listar las de dificultad insane haremos esto:
cat bundle.js | grep "dificultad: \"Insane\""
Y vemos que nos muestra la dificultad de cada maquina que encontro, pero nos interesa ver también el nombre de esa maquina que es insane, por lo que usando el parametro -B de grep listaremos 5 valores anteriores a lo que estamos filtrando así que nos mostrará lo siguiente:
cat bundle.js | grep "dificultad: \"Insane\"" -B 5
Ahora vemos el nombre, pero ahora nos interesa quedarnos con el puro nombre de las maquinas, así que usando grep filtraremos por “name:”:
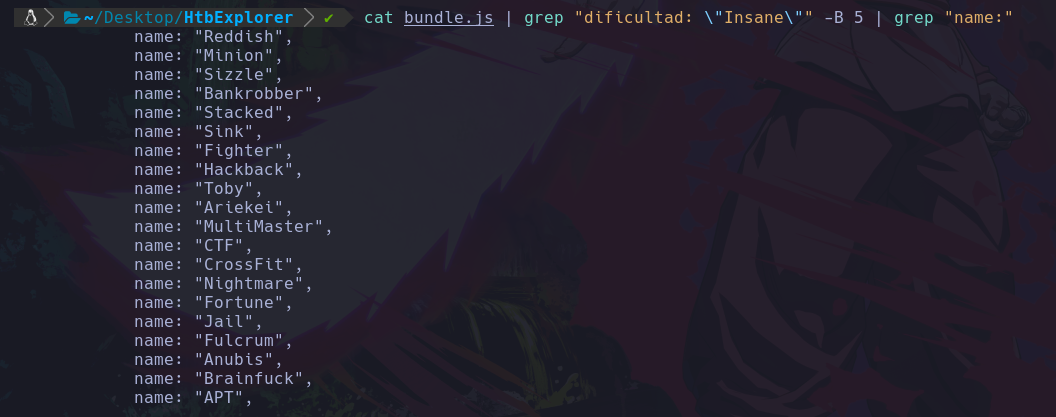
Y ahora queremos quedarnos con el ultimo valor de cada elemento, por lo que usaremo awk:
cat bundle.js | grep "dificultad: \"Insane\"" -B 5 | grep "name:" | awk 'NF{print $NF}'
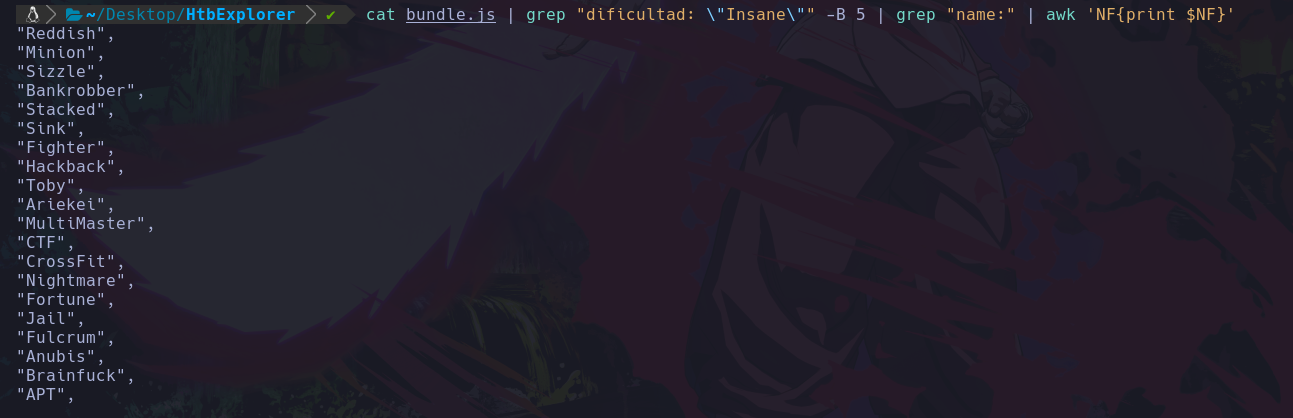
Ya las tenemos, ahora nos interesa quitarles las comillas dobles y simples, ya sabemos que usaremos tr -d:
cat bundle.js | grep "dificultad: \"Insane\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,'
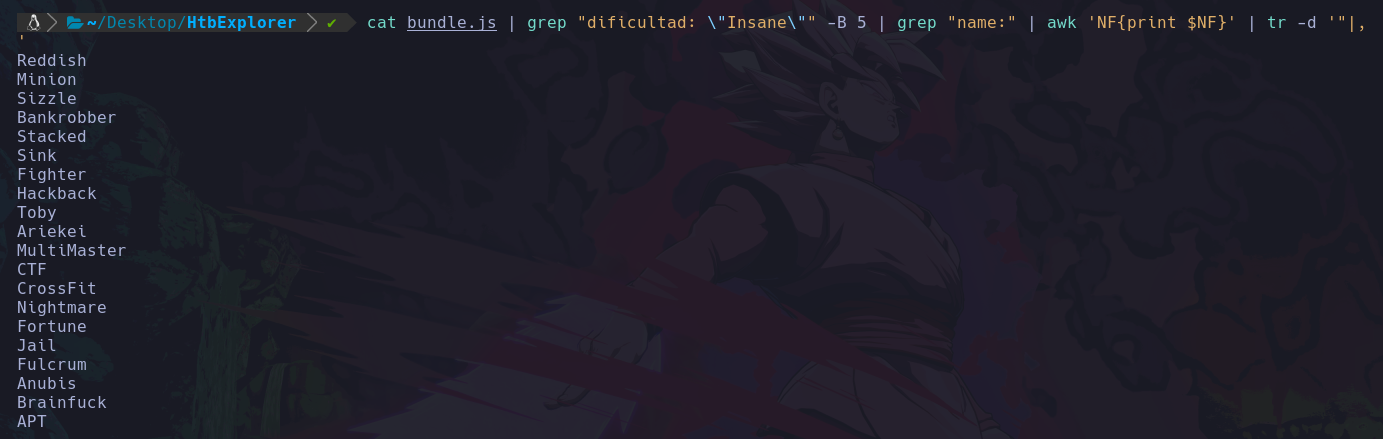
Ahora vemos que tenemos todas las de dificultad insane, y agregaremos el comando column para acomodarlas en una columna:
cat bundle.js | grep "dificultad: \"Insane\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
Viendose así:

Ahora que ya tenemos el one-liner vamos a definir la función ListarDificultad:
function ListarDificultad(){
dificultad="$1"
dificultadLista="$(cat bundle.js | grep "dificultad: \"$dificultad\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,
' | column)"
if [ "$dificultadLista" ]; then
echo -e "${purpleColour}[*] ${yellowColour}Las maquinas con dificultad ${greenColour}$dificultad ${yellowColour}son:${endC
olour}"
echo -e "${turquoiseColour}"
cat bundle.js | grep "dificultad: \"$dificultad\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
echo -e "${endColour}"
else
echo -e "${redColour}[!] La dificultad proporcionada no existe${endColour}"
fi
}
Primero obtenemos el parametro que se le paso a esa función en la ejecución del script, y luego guardamos en la variable dificultadLista el output del one-liner que recien creamos, esto para enseguida en el if comprobar si existe esa dificultad que paso el usuario por el parametro -d.
En caso de que si entonces muestra un mensaje de las maquinas que se van a mostrar para posteriormente mostrar el output del one-liner en color turquoise.
Y en caso de que no exista la dificultad entonces nos dará ese mensaje del else.
Y así se ve en ejecución:
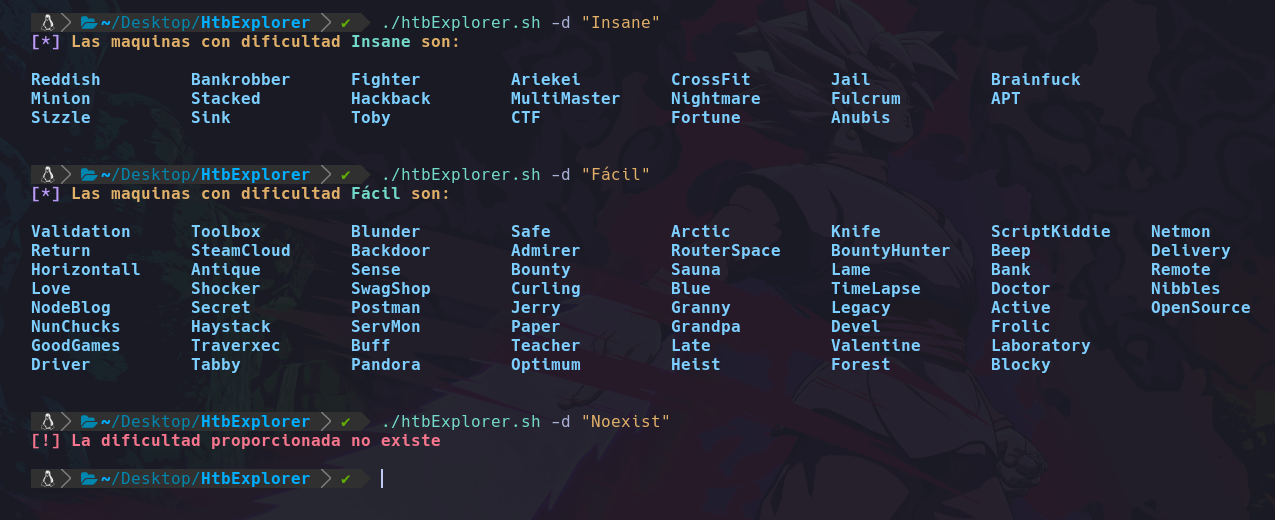
Creando una funcion para filtrar maquinas por sistema operativo
Ahora vamos a crear una función para que nos muestre las maquinas por sistema operativo, ya sean Linux o Windows.
Primero agregamos al helpPanel el parametro para que el usuario sepa cuál es:
function helpPanel(){
echo -e "\n${greenColour}[!] ${yellowColour}Uso del script:"
echo -e "\t${purpleColour}u) ${yellowColour}Actualizar archivos necesarios${endColour}"
echo -e "\t${purpleColour}m) ${yellowColour}Buscar una maquina por su nombre${endColour}"
echo -e "\t${purpleColour}i) ${yellowColour}Buscar una maquina por su dirección IP${endColour}"
echo -e "\t${purpleColour}y) ${yellowColour}Obtener el link de la resolución de una maquina${endColour}"
echo -e "\t${purpleColour}d) ${yellowColour}Listar las maquinas en base a su dificultad${endColour}"
echo -e "\t${purpleColour}o) ${yellowColour}Mostrar las maquinas por sistema operativo especifico${endColour}"
echo -e "\t${purpleColour}h) ${yellowColour}Mostrar este panel de ayuda${endColour}"
}
Vemos que agregamos el parametro -o que en este caso es el que usaremos para filtrar las maquinas por sistema operativo.
Ahora agregaremos a el while getopts el parametro:
while getopts "m:i:y:d:o:uh" arg; do
case $arg in
m) nombreMaquina="$OPTARG"; let parameter_counter+=1;;
u) let parameter_counter+=2;;
i) ipAddress="$OPTARG"; let parameter_counter+=3;;
y) NombreMaquina="$OPTARG"; let parameter_counter+=4;;
d) Dificultad=$OPTARG; let parameter_counter+=5;;
o) SO=$OPTARG; let parameter_counter+=6;;
h) ;;
esac
done
Agregamos el parametro en el while getopts con dos puntos a la derecha ya que recordamos que recibirá argumentos.
Y ese argumento pasado se almacenará en la variable SO, y recordemos aumentar el parameter counter en valor 6 para identificarlo en el manejo de funciones:
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
elif [ $parameter_counter -eq 2 ]; then
actualizarArchivos
elif [ $parameter_counter -eq 3 ]; then
buscarIp $ipAddress
elif [ $parameter_counter -eq 4 ]; then
getLink $NombreMaquina
elif [ $parameter_counter -eq 5 ]; then
ListarDificultad $Dificultad
elif [ $parameter_counter -eq 6 ]; then
ListarSO $SO
else
helpPanel
fi
Ahora hemos agregado la función en el manejo de funciones, en este caso llamaremos a la función ListarSO pasandole el argumento que obtuvimos del parametro -o.
Esta función la vamosa crear y definir ahora, primero crearemos el one-liner para esta función.
Nos interesa filtrar por sistema operativo, así que para crear el one-liner hacemos lo siguiente:
cat bundle.js | grep "so: \"Linux\""
Vemos que filtramos todas las lineas de cada maquina Linux, pero ahora queremos saber el nombre de esa maquina filtrada, por lo que listaremos 5 elementos hacía arriba:
cat bundle.js | grep "so: \"Linux\"" -B 5
Ahora vemos el valor “name:” seguido del nombre que nos interesa, por lo que ahora filtraremos por “name:”:
cat bundle.js | grep "so: \"Linux\"" -B 5 | grep "name:"
Ahora vemos que ya hemos filtrado las que nos interesan, ahora queda quedarnos con el último argumento:
cat bundle.js | grep "so: \"Linux\"" -B 5 | grep "name:" | awk 'NF{print $NF}'
Y ahora simplemente eliminamos las comillas dobles y comillas con tr -d:
Y con el comando column lo ponemos en formato de columna:
cat bundle.js | grep "so: \"Linux\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
Y ya tenemos el one-liner.
Ahora vamos a crear la función ListarSO:
function ListarSO(){
so="$1"
comprobar="$(cat bundle.js | grep "so: \"$so\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column)"
if [ "$comprobar" ]; then
echo -e "\n${yellowColour}[*] ${blueColour}Listando las maquinas que son ${greenColour}$so:${endColour}"
echo -e "${yellowColour}"
cat bundle.js | grep "so: \"$so\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
echo -e "${endColour}"
else
echo -e "${redColour}[!] Error, el sistema operativo indicado no existe${endColour}"
fi
}
Primero creamos la variable y su contenido es el output del one-liner que recien creamos, y la guardamos dentro de esta variable que llamamos comprobar esto para comprobar que el valor pasado por el parametro -o sea existente.
En caso de que si tenga contenido, entonces muestra un mensaje con ahora si la ejecución del output del one-liner.
En caso de que no entonces mostramos el mensaje de error.
Configurando la logica en caso de que el usuario quiera buscar por sistema operativo y a la vez por dificultad
Ahora si queremos filtrar las maquinas de x dificultad pero que sean un sistema operativo especifico debemos hacer lo siguiente.
Haremos uso de los chivato que son variables extra que nos ayudarán a saber si se llamo a 2 parametros.
Veamos:
#Manejo de parametros
declare -i parameter_counter=0
declare -i chivato_so=0
declare -i chivato_dificultad=0
while getopts "m:i:y:d:o:uh" arg; do
case $arg in
m) nombreMaquina="$OPTARG"; let parameter_counter+=1;;
u) let parameter_counter+=2;;
i) ipAddress="$OPTARG"; let parameter_counter+=3;;
y) NombreMaquina="$OPTARG"; let parameter_counter+=4;;
d) Dificultad=$OPTARG; chivato_dificultad=1; let parameter_counter+=5;;
o) SO=$OPTARG; chivato_so=1; let parameter_counter+=6;;
h) ;;
esac
done
Primero vemos que declaramos 2 variables, una llamada chivato_so y otra llamada chivato_dificultad ambas de valor entero e iniciadas en 0.
Estas nos van a servir para saber si se usaron mas parametros.
Vemos que en el parametro -d de dificultad agregamos la instrucción de que la variable chivato_dificultad valga 1.
Si el usuario llamo a este parametro aumentará en 1 la variable chivato_dificultad.
Pero si el usuario también usa el parametro -o de sistema operativo igual vemos que decimos la instrucción en el parametro -o de que chivato_so valga 1.
Así que ya sabemos que si las 2 variables chivato valen 1 ambas, quiere decir que se usaron ambas en una misma llamada al script.
Por lo que ahora nos será más facíl manejar esto en el manejo de funciones:
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
elif [ $parameter_counter -eq 2 ]; then
actualizarArchivos
elif [ $parameter_counter -eq 3 ]; then
buscarIp $ipAddress
elif [ $parameter_counter -eq 4 ]; then
getLink $NombreMaquina
elif [ $parameter_counter -eq 5 ]; then
ListarDificultad $Dificultad
elif [ $parameter_counter -eq 6 ]; then
ListarSO $SO
elif [ $chivato_dificultad -eq 1 ] && [ $chivato_so -eq 1 ]; then
DifSO $SO $Dificultad
else
helpPanel
fi
vemos que agregamos un elif y en caso de que la variable chivato_dificultad sea igual a 1 y también que si la variable chivato_so es igual a 1, entonces esto indica que entro a ambas variables y les aumento en valor 1.
Por lo que quiere decir que el usuario paso argumentos a esos 2 parametros, así que llamamos a una función nueva que crearemos llamada DifSO y le pasamos los argumentos de cada valor que guardo el parametro.
Y ahora crearemos la funcion DifSO pero primero crearemos un one-liner que nos filtre por este par de cosas:
cat bundle.js | grep "so: \"Linux\"" -C 5
Como en este caso ocupamos el nombre de la maquina por la cual estamos filtrando su sistema y su nombre esta arriba del valor desde el cual estamos filtrando en este caso estamos filtrando desde el valor “so: Linux” pero el nombre de la maquina se encuentra varias lineas hacía arriba y la dificultad esta varias lineas hacía abajo.
Y como nos interesa tomar ambos valores pero recordemos que el parametro de grep -A solo nos muestra lineas de abajo y el parametro -B solo las de arriba, usaremos en este caso el parametro -C que nos filtra a ambos lados una cantidad de lineas.
En este caso indicamos que nos muestre 5 lineas hacía arriba y a la vez 5 hacía abajo.
De este modo ya podemos ver lo que nos interesa.
Ahora filtraremos por la dificultad:
cat bundle.js | grep "so: \"Linux\"" -C 5 | grep "dificultad: \"Fácil\""
Como anteriormente ya habriamos filtrado por las maquinas Linux ahora a estas filtradas filtraremos las que sean de dificultad Facil:
Ahora nos muestran las que son Linux y Fácil, así que ahora nos interesa ver el nombre de estas maquinas, por lo que mostraremos 5 lineas hacía arriba ya que arriba de cada maquina filtrada se encuentra el nombre de dicha maquina, para ello usamos el parametro -B de grep:
cat bundle.js | grep "so: \"Linux\"" -C 5 | grep "dificultad: \"Fácil\"" -B 5
Y ahora nos interesa quedarnos solo con el nombre:
cat bundle.js | grep "so: \"Linux\"" -C 5 | grep "dificultad: \"Fácil\"" -B 5 | grep "name:"
Y vemos que ahora nos muestra los nombres de las maquinas Linux que son facil, ahora nos quedamos con el último valor y removemos comillas dobles y normales:
cat bundle.js | grep "so: \"Linux\"" -C 5 | grep "dificultad: \"Fácil\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,'
No olvidemos mostrarlas en forma de columna:
cat bundle.js | grep "so: \"Linux\"" -C 5 | grep "dificultad: \"Fácil\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column

Ya tenemos el one-liner.
Ahora definiremos la función DifSO:
function DifSO(){
so="$1"
dificultad="$2"
comprobar="$(cat bundle.js | grep "so: \"$so\"" -C 5 | grep "dificultad: \"$dificultad\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column)"
if [ "$comprobar" ]; then
echo -e "\n${turquoiseColour}[+] ${greenColour}Mostrando las maquinas ${purpleColour}$so ${greenColour}con dificultad ${purpleColour}$dificultad"
echo -e "${yellowColour}"
cat bundle.js | grep "so: \"$so\"" -C 5 | grep "dificultad: \"$dificultad\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
echo -e "${endColour}"
else
echo -e "${redColour}[!] Error el sistema operativo o dificultad no existe${endColour}"
fi
}
Siguiendo la misma lógica que las funciones anteriores, recibimos en este caso 2 argumentos, el de el sistema operativo y el de la dificultad, debemos respetar el orden que hicimos al llamar la función así que primero recibimos el primer parametro que en este caso fue el del sistema operativo y segundo el de la dificultad y los guardamos en variables.
Ahora con el one-liner anterior y obviamente reemplazando los valores que filtramos por las variables guardamos este optut dentro de la variable comprobar.
Luego metemos en la condición la variable comprobar para ver si tiene contenido, en caso de que si se muestra un mensaje que se va a mostrar y posteriormente se muestra.
Y en caso contrario nos da un mensaje de error.
Y así se ve funcionando:
Y habremos terminado con esta funcion.
Agregando una funcion para filtrar maquinas por skills
Por último vamos a crear un nuevo parametro en el script que nos permita filtrar por skills, es decir por temas que se tocan en la maquina, como inyecciones SQL, SSRF, etc.
Supongamos que la skill es “SSRF”:
cat bundle.js | grep "SSRF" -B 6
Filtramos las maquinas que contengan “SSRF” en skills y con el parametro -B de grep mostramos 6 lineas hacía arriba ya que nos interesa ver el nombre de dicha maquina.
Ahora que ya filtramos las maquinas que tiene skill “SSRF” nos interesa filtrar el puro nombre de dichas maquinas:
cat bundle.js | grep "SSRF" -B 6 | grep "name:"
Ahora nos quedaremos con el puro nombre de las maquinas y removeremos las cosas que no nos interesan como las comillas dobles y normales con tr:
cat bundle.js | grep "SSRF" -B 6 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,'

Y ahora lo listaremos en una columna:
cat bundle.js | grep "SSRF" -B 6 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column

Y ya tenemos el one-liner para filtrar por skills.
Ahora crearemos una funcion nueva y todo para implementarlo al script, primero agregamos la opción al helpPanel:
function helpPanel(){
echo -e "\n${greenColour}[!] ${yellowColour}Uso del script:"
echo -e "\t${purpleColour}u) ${yellowColour}Actualizar archivos necesarios${endColour}"
echo -e "\t${purpleColour}m) ${yellowColour}Buscar una maquina por su nombre${endColour}"
echo -e "\t${purpleColour}i) ${yellowColour}Buscar una maquina por su dirección IP${endColour}"
echo -e "\t${purpleColour}y) ${yellowColour}Obtener el link de la resolución de una maquina${endColour}"
echo -e "\t${purpleColour}d) ${yellowColour}Listar las maquinas en base a su dificultad${endColour}"
echo -e "\t${purpleColour}o) ${yellowColour}Mostrar las maquinas por sistema operativo especifico${endColour}"
echo -e "\t${purpleColour}s) ${yellowColour}Filtrar maquinas por skills${endColour}"
echo -e "\t${purpleColour}h) ${yellowColour}Mostrar este panel de ayuda${endColour}"
}
Vemos que hemos agregado el parametro -s , así es como se llamará para filtrar maquinas por skills.
Ahora agregamos este parametro al while getopts:
while getopts "m:i:y:d:o:s:uh" arg; do
case $arg in
m) nombreMaquina="$OPTARG"; let parameter_counter+=1;;
u) let parameter_counter+=2;;
i) ipAddress="$OPTARG"; let parameter_counter+=3;;
y) NombreMaquina="$OPTARG"; let parameter_counter+=4;;
d) Dificultad=$OPTARG; chivato_dificultad=1; let parameter_counter+=5;;
o) SO=$OPTARG; chivato_so=1; let parameter_counter+=6;;
s) skill=$OPTARG; let parameter_counter+=7;;
h) ;;
esac
done
Vemos que arriba agregamos el parametro s y dos puntos a su derecha ya que recibira argumentos.
Y lo que se reciba al llamar a este parametro se almacenará dentro de la variable skill y aumentamos el parameter_counter en 7 para darnos cuenta de que se utilizo este parametro en la ejecución del script.
Y por último lo agregaremos a el manejo de funciones:
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
elif [ $parameter_counter -eq 2 ]; then
actualizarArchivos
elif [ $parameter_counter -eq 3 ]; then
buscarIp $ipAddress
elif [ $parameter_counter -eq 4 ]; then
getLink $NombreMaquina
elif [ $parameter_counter -eq 5 ]; then
ListarDificultad $Dificultad
elif [ $parameter_counter -eq 6 ]; then
ListarSO $SO
elif [ $chivato_dificultad -eq 1 ] && [ $chivato_so -eq 1 ]; then
DifSO $SO $Dificultad
elif [ $parameter_counter -eq 7 ]; then
Skill $skill
else
helpPanel
fi
Vemos que agregamos la condicion en caso de que la variable parameter_counter sea igual a 7 entonces indica que el usuario uso el parametro -s. Así que ahora llamaremos a la función Skill y le pasamos el valor que paso el usuario y se almaceno en la variable skill.
Y ahora vamos a crear la función Skill ya que aún no la creamos:
function Skill(){
skill="$1"
comprobar="$(cat bundle.js | grep "$skill" -B 6 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column)"
if [ "$comprobar" ]; then
echo -e "\n${blueColour}[+]${purpleColour}Mostrando las maquinas con la skill ${greenColour}$skill${endColour}"
echo -e "${yellowColour}"
cat bundle.js | grep "$skill" -B 6 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
echo -e "${endColour}"
else
echo -e "${redColour}[!] La skill proporcionada No existe${endColour}"
fi
}
Primero guardamos el valor que se le paso a la función, este valor lo recibimos y guardamos dentro de la variable skill.
Luego creamos la variable comprobar y guardará el output del one-liner que creamos anteriormente, y recordemos que primero lo almacenamos en una variable para comprobar si existe lo que el usuario paso al parametro como argumento.
En caso de que si entonces se muestra lo anterior ahora si en pantalla indicando que se mostrarán las maquinas con cierta skill y después las muestra.
Y en caso de que no simplemente arroja un mensaje de error.
Y así se ve en la ejecución:
Proyecto terminado
Y ya hemos terminado con este primer proyecto en bash, el código final del script es:
#!/bin/bash
#Colores
greenColour="\e[0;32m\033[1m"
endColour="\033[0m\e[0m"
redColour="\e[0;31m\033[1m"
blueColour="\e[0;34m\033[1m"
yellowColour="\e[0;33m\033[1m"
purpleColour="\e[0;35m\033[1m"
turquoiseColour="\e[0;36m\033[1m"
grayColour="\e[0;37m\033[1m"
#Variables Globales
htbweb="https://htbmachines.github.io/bundle.js"
function ctrl_c(){
echo -e "\n${redColour}[!] Saliendo del script...${endColour}\n"
exit 1
}
#Ctrl+c
trap ctrl_c INT
function helpPanel(){
echo -e "\n${greenColour}[!] ${yellowColour}Uso del script:"
echo -e "\t${purpleColour}u) ${yellowColour}Actualizar archivos necesarios${endColour}"
echo -e "\t${purpleColour}m) ${yellowColour}Buscar una maquina por su nombre${endColour}"
echo -e "\t${purpleColour}i) ${yellowColour}Buscar una maquina por su dirección IP${endColour}"
echo -e "\t${purpleColour}y) ${yellowColour}Obtener el link de la resolución de una maquina${endColour}"
echo -e "\t${purpleColour}d) ${yellowColour}Listar las maquinas en base a su dificultad${endColour}"
echo -e "\t${purpleColour}o) ${yellowColour}Mostrar las maquinas por sistema operativo especifico${endColour}"
echo -e "\t${purpleColour}s) ${yellowColour}Filtrar maquinas por skills${endColour}"
echo -e "\t${purpleColour}h) ${yellowColour}Mostrar este panel de ayuda${endColour}"
}
function buscarMaquina(){
nombre="$1"
validacion="$(cat bundle.js | awk "/name: \"$nombre\"/,/resuelta:/" | grep -vE "id|sku|resuelta" | tr -d '"|,' | sed 's/^ *//'
)"
if [ "$validacion" ]; then
echo -e "\n${yellowColour}[+] ${greenColour}Listando propiedades de la maquina ${purpleColour}$nombre${endColour}\n"
echo -e "${yellowColour}"
cat bundle.js | awk "/name: \"$nombre\"/,/resuelta:/" | grep -vE "id|sku|resuelta" | tr -d '"|,' | sed 's/^ *//'
echo -e "${endColour}"
else
echo -e "${redColour}[!] El nombre de la maquina No existe${endColour}"
fi
}
function actualizarArchivos(){
tput civis
if [ ! -f bundle.js ]; then
echo -e "\n${greenColour}[!] ${turquoiseColour}Actualizando archivos...${endColour}"
curl -s -X GET $htbweb > bundle.js
js-beautify bundle.js | sponge bundle.js
echo -e "\n${greenColour}[!] ${turquoiseColour}Los archivos se han descargado correctamente!"
else
curl -s -X GET $htbweb > bundle_new.js
js-beautify bundle_new.js | sponge bundle_new.js
md5_newhash=$(md5sum bundle_new.js | awk '{print $1}')
md5hash=$(md5sum bundle.js | awk '{print $1}')
if [ "$md5_newhash" == "$md5hash" ]; then
echo -e "${turquoiseColour}[!] Los archivos estan actualizados${endColour}"
rm bundle_new.js
else
echo -e "${yellowColour}[!] Iniciando con las actualizaciones...${endColour}"
rm bundle.js && mv bundle_new.js bundle.js
echo -e "${yellowColour}[+] Los archivos se han actualizado correctamente${endColour}"
fi
tput cnorm
fi
}
function buscarIp(){
ip_address="$1"
nombreMaquina=$(cat bundle.js | grep "ip: \"$ip_address\"" -B 3 | grep "name:" | awk 'NF{print$NF}' | tr -d '"|,')
if [ "$nombreMaquina" ]; then
echo -e "\n${turquoisecolour}[+] ${purpleColour}El nombre de la maquina en la IP ${greenColour}$ip_address${purpleColour} es ${greenColour}$nombreMaquina"
else
echo -e "${redColour} [!] La dirección IP proporcionada no existe${endColour}"
fi
}
function getLink(){
maquina="$1"
obtenerLink="$(cat bundle.js | awk "/name: \"$maquina\"/,/resuelta:/" | grep "youtube:" | awk 'NF{print $NF}' | tr -d '"|,')"
if [ "$obtenerLink" ]; then
echo -e "${purpleColour}[*] ${turquoiseColour}El link de la resolución de la maquina ${greenColour}$maquina ${turquoiseColour}es: ${greenColour}$obtenerLink${endColour}"
else
echo -e "${redColour}[!] El nombre de la maquina proporcionada no existe${endColour}"
fi
}
function ListarDificultad(){
dificultad="$1"
dificultadLista="$(cat bundle.js | grep "dificultad: \"$dificultad\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column)"
if [ "$dificultadLista" ]; then
echo -e "${purpleColour}[*] ${yellowColour}Las maquinas con dificultad ${greenColour}$dificultad ${yellowColour}son:${endColour}"
echo -e "${turquoiseColour}"
cat bundle.js | grep "dificultad: \"$dificultad\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
echo -e "${endColour}"
else
echo -e "${redColour}[!] La dificultad proporcionada no existe${endColour}"
fi
}
function ListarSO(){
so="$1"
comprobar="$(cat bundle.js | grep "so: \"$so\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column)"
if [ "$comprobar" ]; then
echo -e "\n${yellowColour}[*] ${blueColour}Listando las maquinas que son ${greenColour}$so:${endColour}"
echo -e "${yellowColour}"
cat bundle.js | grep "so: \"$so\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
echo -e "${endColour}"
else
echo -e "${redColour}[!] Error, el sistema operativo indicado no existe${endColour}"
fi
}
function DifSO(){
so="$1"
dificultad="$2"
comprobar="$(cat bundle.js | grep "so: \"$so\"" -C 5 | grep "dificultad: \"$dificultad\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column)"
if [ "$comprobar" ]; then
echo -e "\n${turquoiseColour}[+] ${greenColour}Mostrando las maquinas ${purpleColour}$so ${greenColour}con dificultad ${purpleColour}$dificultad"
echo -e "${yellowColour}"
cat bundle.js | grep "so: \"$so\"" -C 5 | grep "dificultad: \"$dificultad\"" -B 5 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
echo -e "${endColour}"
else
echo -e "${redColour}[!] Error el sistema operativo o dificultad no existe${endColour}"
fi
}
function Skill(){
skill="$1"
comprobar="$(cat bundle.js | grep "$skill" -B 6 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column)"
if [ "$comprobar" ]; then
echo -e "\n${blueColour}[+]${purpleColour}Mostrando las maquinas con la skill ${greenColour}$skill${endColour}"
echo -e "${yellowColour}"
cat bundle.js | grep "$skill" -B 6 | grep "name:" | awk 'NF{print $NF}' | tr -d '"|,' | column
echo -e "${endColour}"
else
echo -e "${redColour}[!] La skill proporcionada No existe${endColour}"
fi
}
#Manejo de parametros
declare -i parameter_counter=0
declare -i chivato_so=0
declare -i chivato_dificultad=0
while getopts "m:i:y:d:o:s:uh" arg; do
case $arg in
m) nombreMaquina="$OPTARG"; let parameter_counter+=1;;
u) let parameter_counter+=2;;
i) ipAddress="$OPTARG"; let parameter_counter+=3;;
y) NombreMaquina="$OPTARG"; let parameter_counter+=4;;
d) Dificultad=$OPTARG; chivato_dificultad=1; let parameter_counter+=5;;
o) SO=$OPTARG; chivato_so=1; let parameter_counter+=6;;
s) skill=$OPTARG; let parameter_counter+=7;;
h) ;;
esac
done
#Manejo de funciones
if [ $parameter_counter -eq 1 ]; then
buscarMaquina $nombreMaquina
elif [ $parameter_counter -eq 2 ]; then
actualizarArchivos
elif [ $parameter_counter -eq 3 ]; then
buscarIp $ipAddress
elif [ $parameter_counter -eq 4 ]; then
getLink $NombreMaquina
elif [ $parameter_counter -eq 5 ]; then
ListarDificultad $Dificultad
elif [ $parameter_counter -eq 6 ]; then
ListarSO $SO
elif [ $chivato_dificultad -eq 1 ] && [ $chivato_so -eq 1 ]; then
DifSO $SO $Dificultad
elif [ $parameter_counter -eq 7 ]; then
Skill $skill
else
helpPanel
fi
Y esto sería el resultado final.